Linux内存占用排查|TOP命令实战,精准揪出耗内存服务
- 2026-06-27 18:50:31
Linux内存占用排查|TOP命令实战,精准揪出耗内存服务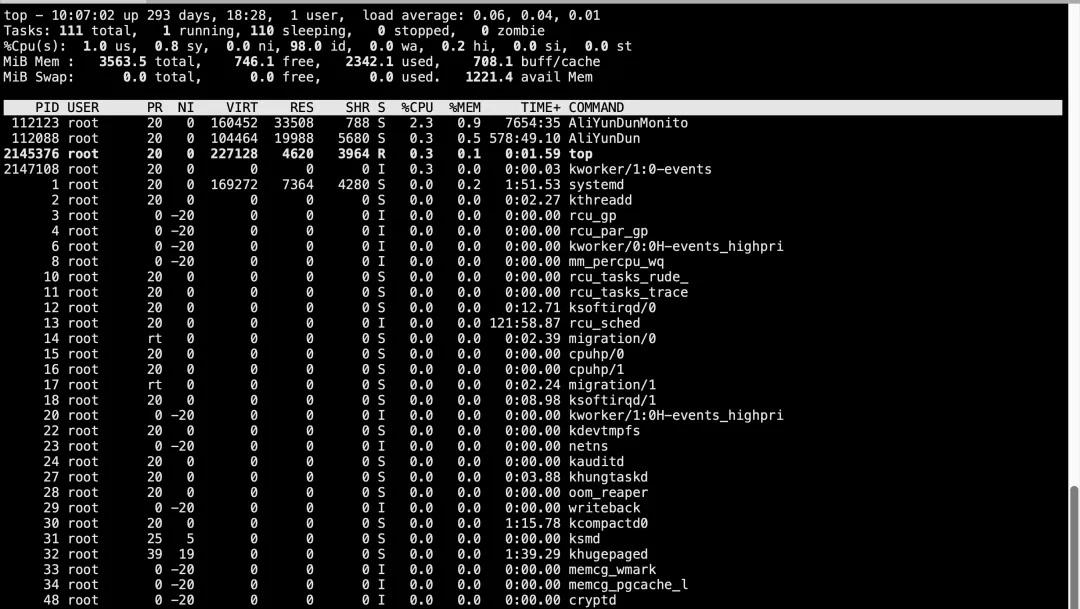



一、常用4条排查命令(生产通用,一键查看内存大户)
前置区分:
buff/cache是系统缓存、不占业务内存;**used上涨 = 进程堆内存占用,必须查进程**
1. top(系统自带,最通用)
top进入后按 M:按内存从高到低排序(RES实际物理内存) 字段释义: VIRT:进程虚拟内存(申请地址空间,参考即可) RES:真实占用物理内存(重点) %MEM:占整机物理内存百分比 按 P切回CPU排序,q退出。
2. ps 静态排序(导出报表、统计用)
# 按内存降序,展示PID、内存、进程名ps -aux --sort=-rss | head -15# RSS单位KB,换算G:/1024/10243. htop(可视化,推荐安装)
#CentOSyum install htop -y#Ubuntuapt install htop -yhtop鼠标点PERCENT_MEM直接排序,直观看到服务占用,F9一键杀异常进程。
4. 精准统计单个进程 / 服务
#筛选mysql、java、nginx等ps -aux | grep java二、关键指标区分:3个内存字段怎么分析
%MEM:单进程占用整机内存比例 你的服务器14G内存,单个进程%MEM>10%≈占用1.4G以上,重点观察 RES:进程常驻物理内存(真实吃掉RAM) SHR:共享库内存,多程序共用,不计重复占用
误区:VIRT大不用慌,只是程序预申请内存;RES飙升才是内存泄漏/配置过大。
三、分步内存分析思路(落地排查流程)
步骤1:整体大盘
free -h
available持续走低、Swap开始上涨 → 内存资源紧张,立刻查高占用进程 available充足(如你的9.1G可用):哪怕个别进程占用偏高,暂时不影响稳定性。
步骤2:定位占用TOP3服务
举例常见占用大户:Java程序、MySQL、Redis、Nginx、消息队列。
Java服务 占用过高:JVM-Xmx堆参数配置过大,远超业务所需,修改启动脚本 -Xms -Xmx;频繁内存上涨:代码内存泄漏,导出dump快照分析。 MySQL innodb_buffer_pool_size参数过大(常规建议物理内存50%以内),调小my.cnf。 Redis maxmemory配置不合理,大量数据全放内存,设置淘汰策略。
步骤3:区分「正常占用」&「异常泄漏」
平稳占用:启动后内存数值长期固定不变 → 配置合理,无需优化; 缓慢持续上涨、只涨不跌 → 内存泄漏,代码/配置故障,必须优化。
四、实操:结合你14G服务器现场分析
Mem:14Gi total|used5.7Gi|available9.1Gi整机业务只占用5.7G,资源宽裕:
若TOP第一进程占用2G左右:属于正常业务负载,不用优化; 单进程突然从500M涨到3G:异常泄漏,排查应用日志。
五、实用排查小脚本(一键导出内存报表)
#输出前10大内存进程,保存日志ps aux --sort=-%mem | head -10 > mem_top.logcat mem_top.log六、配套优化方案
配置优化:数据库、中间件调低内存上限,适配服务器物理规格; 程序优化:泄漏应用迭代修复代码,增加定时重启(临时方案); 资源扩容:所有服务优化完毕,整体used仍逼近总内存70%,再升级服务器内存。
文末总结口诀
看内存先分缓存与进程, top按M排序找元凶, VIRT虚存不用管,RES实存是核心, 稳步上涨属正常,只涨不跌查泄漏。
IT技术交流群:
软件接单交流群:
体验营销二维码
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python 相关:Abaqus/CAE中的宏录制功能
- Python终于要干掉GIL了,你的代码需要改什么
- MarkItDown + Python:微软这波开源,让文档处理效率提升10倍
- Python 语法糖一篇搞定
- 04 Python3 数据类型转换+注释+运算符
- 考前练习三题python大题
- 9000~18000,Java等最新招聘!五险一金、双休待遇好!桂林好工作0603期
- 一文吃透 Linux LVM:从原理到实战,让磁盘管理像搭积木一样简单
- 野生Linux 实战脚本库第一弹:5 个让你效率翻倍的 Shell 脚本
- 【真题分享】2024年信息素养大赛python复赛真题试卷分享
