Python对同一文件夹多工作簿进行合并
- 2026-06-16 01:27:17
Python对同一文件夹多工作簿进行合并网上的一个经典例题,同一文件夹下有多张工作簿,将这些工作簿合并为一个: 
本来这种多工作簿合并的问题用VBA最方便,很多小工具可以一键合并,但是打开工作簿发现每个工作簿的列名顺序不一致,有的甚至缺列: 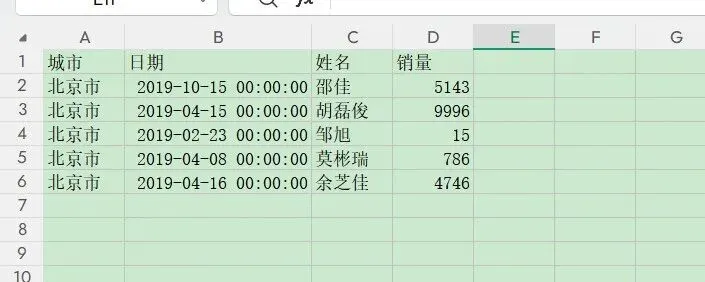
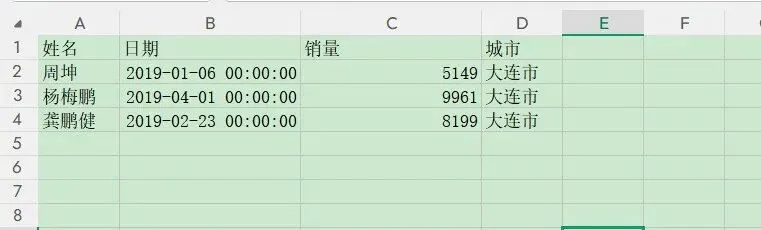
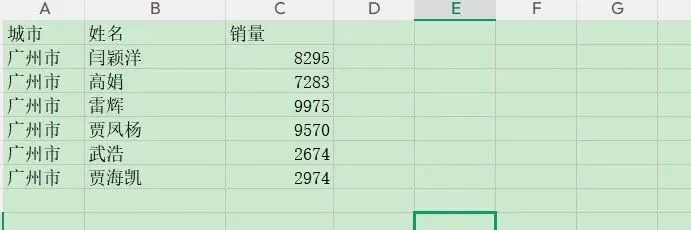
VBA是按表格的‘A’列对‘A’列,‘B’列对‘B’列进行合并,所以合并后数据是错乱的,除非提前手工清洗,将列名顺序改为一致。剩下解决的方案只剩下:PowerQuery和Python,PQ同样可以按列名合并,但Excel2016以下版本和WPS不支持,不适合大多数用户,而Pandas库的concat功能却能轻松解决这一问题。 第一步借助OS读取文件夹下所有的工作簿: 第二步用for循环读取所有工作簿下的数据: 
files = [f for f in os.listdir(folder) if f.endswith(('.xlsx', '.xls')) and f != os.path.basename(output_file)]
for f in files:
path = os.path.join(folder, f)
df = pd.read_excel(path, sheet_name=0)
..........
dfs.append(df)
第三步对相同的列进行合并并写入输出文件:
merged = pd.concat(dfs, ignore_index=True)#对数据进行合并
merged.to_excel(output_file, index=False)#合并数据写入输出文件
完整的代码如下:
看下执行过程:
已关注
关注
重播 分享 赞
所有工作簿按相同列名进行了完整的合并,跳过了缺列的那些数据,并且增加合并表索引,方便溯源。因Pandas强大数据处理能力,即使同一文件夹下有上千个工作簿也能轻松处理。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 学协*法学院丨Python期末倒计时!请查收这份专属备考攻略!
- Proton Drive大提速,Linux客户端即将上线
- 少儿自学编程第33课:Python让飞船发射子弹,打中陨石就加分,游戏从此有了“打击感”
- 45个Python办公自动化脚本,效率翻倍!
- Python 里最会“报进度”的小工具:tqdm
- 【Python】Day24:Git基础与项目准备
- python入门【学习路线】,小白有这一篇就够了!
- Python快速入门学习笔记三十八:多进程 vs 多线程,该如何选择?
- Python+Fortran混合编程神器gfort2py3.0.0发布
- Python 的 namedtuple 有什么作用?怎么使用?
