Python从入门到实战-第 11 章:数据分析实战
- 2026-07-01 18:55:56
Python在数据分析领域也应用广泛,这一章我们就来了解一下使用Python进行数据分析时一些常见的库,如numpy、pandas、matplotlib、seaborn等。
数据加载与快速预览
在开始之前,我们需要先创建一个工程并安装一下numpy、pandas、matplotlib、seaborn这些库,便于我们后续的学习与操作。
加载数据集
数据分析当然首先要有数据,如果手中没有现成的数据也不要紧,这一点seaborn库已经帮我们解决了,它内置了超过20个数据集,我们可以通过下面的代码查看内置的数据集:
import seaborn as snsprint(sns.get_dataset_names())我们以内置的泰坦尼克号生存数据为基础来了解数据分析中常见的一些操作。首先我们来加载和预览数据:
import seaborn as snsdf = sns.load_dataset('titanic')print(df.head())使用seaborn模块中的load_dataset()方法来加载泰坦尼克的数据集,然后使用head()方法来输出前五行数据,方便我们快速了解一下数据长什么样。会有如下输出:
survived pclass sex age sibsp parch fare embarked class who adult_male deck embark_town alive alone0 0 3 male 22.0 1 0 7.2500 S Third man True NaN Southampton no False1 1 1 female 38.0 1 0 71.2833 C First woman False C Cherbourg yes False2 1 3 female 26.0 0 0 7.9250 S Third woman False NaN Southampton yes True3 1 1 female 35.0 1 0 53.1000 S First woman False C Southampton yes False4 0 3 male 35.0 0 0 8.0500 S Third man True NaN Southampton no True查看数据的基本信息
这么多列数据,如果想了解每列数据的类型,每条数据是否有缺失值,可以用info()方法:
df.info()这行代码会输出如下内容:
<class 'pandas.DataFrame'>RangeIndex: 891 entries, 0 to 890Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 survived 891 non-null int64 1 pclass 891 non-null int64 2 sex 891 non-null str 3 age 714 non-null float64 4 sibsp 891 non-null int64 5 parch 891 non-null int64 6 fare 891 non-null float64 7 embarked 889 non-null str 8 class 891 non-null category 9 who 891 non-null str 10 adult_male 891 non-null bool 11 deck 203 non-null category 12 embark_town 889 non-null str 13 alive 891 non-null str 14 alone 891 non-null booldtypes: bool(2), category(2), float64(2), int64(4), str(5)memory usage: 80.7 KB从输出中我们可以明确看到每一列的数据类型,也可以判断哪些列有数据缺失,比如age列的非空数据有714条,而实际的记录是有891条,说明是有数据缺失的,还给出了数据集加载占用的内存大小,方便我们判断自己的机器是否具备处理这些数据的能力或者调整处理数据的策略。
在输出中我们还看到有一个category类型,这并不是Python中的内置数据类型,它是pandas库的一种扩展数据类型,专门用于处理分类数据,这类数据在数据集中存在大量重复,category类型通过存储整数编码而非原始字符串来节省内存,比如在泰坦尼克号这个数据集中class字段的值有三个:First,Second,Third,可以用数字0,1,2来代表,我们可以用下面的代码来打印分类以及数据中编码:
print(df['class'].cat.categories)print(df['class'].cat.codes)会输出如下内容:
Index(['First', 'Second', 'Third'], dtype='str')0 21 02 23 04 2 ..886 1887 0888 2889 0890 2Length: 891, dtype: int8如果想看一下分类与编码的对应关系,可以这么做:
for code, categroy in enumerate(df['class'].cat.categories): print(f'{code} - {categroy}')执行代码会输出:
0 - First1 - Second2 - Third生成的编码是按照分类名称的字母(A-Z)或数字顺序排序,编码则从0开始依次编号。
当然我们也可以改变它,比如原先class分类是按照First对应编码0,现在我希望修改为Third对应编码0,则可以这么做:
df['class'] = df['class'].cat.set_categories(['Third', 'Second', 'First'])for code, categroy in enumerate(df['class'].cat.categories): print(f'{code} - {categroy}')这样就会输出:
0 - Third1 - Second2 - First这里我们也顺便说一下titanic这个数据集各个字段的含义:
survived 是否幸存 0=遇难,1=幸存pclass 船舱等级 1=头等,2=二等,3=三等sex 性别 male/femaleage 年龄sibsp 同乘的兄弟姐妹/配偶人数parch 同乘的父母/子女人数fare 船票价格embarked 登船港口 C=瑟堡,Q=皇后镇,S=南安普顿class 舱位等级(文字)First/Second/Thirdwho 人群类型 man/woman/childadult_male 是否成年男性 True代表是,False代表否deck 甲板位置(A, B, C, D, E, F, G等)embark_town 登船城市全称alive 生存状态的文字描述(与 survived对应)'yes'代表存活,'no'代表遇难alone 是否独自乘船 True代表独自一人,False代表有家属陪同查看数据的统计指标
如果我们想快速了解数据的分布情况,可以使用describe()方法:
print(df.describe())上面的代码会输出如下内容:
survived pclass age sibsp parch farecount 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000mean 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208std 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429min 0.000000 1.000000 0.420000 0.000000 0.000000 0.00000025% 0.000000 2.000000 20.125000 0.000000 0.000000 7.91040050% 0.000000 3.000000 28.000000 0.000000 0.000000 14.45420075% 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000max 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200它展示了8个指标的信息:count表示非空数据数量,mean表示平均值,std表示标准差(数据波动大小),min表示最小值,25%表示前四分之一分位数,50%表示中位数(中间值),75%表示后四分之一分位数,max表示最大值。
我们从这个统计信息中看到它只显示了6个字段的指标,为什么?
因为这个统计信息只展示数字类型的字段,其他的字段是非数字类型,不能计算像平均值,标准差这些指标。如果非要在统计结果中看到所有的字段,可以设置describe的参数:
print(df.describe(include='all'))这样就可以展示所有的数据字段了,但因为有些字段不是数字,你会看到很多的NaN。
加载自己的数据
前面我们加载的数据是seaborn模块中自带的数据集,如果自己有数据集怎么加载呢?比如我现在有一份grades.csv数据:
姓名,语文,数学,英语张三,80,90,75李四,88,92,95王五,70,80,65按照前面加载数据的方法,我可以这么做:
import seaborn as snsdf = sns.load_dataset('grades')print(df.head())但实际上这样不行,虽然grades.csv与脚本文件在同级目录下,但执行仍然会出现如下的错误:
ValueError: 'grades' is not one of the example datasets.根据这个提示我们大致知道load_dataset()方法是加载示例数据集的,也就是内置的数据集,所以我们要换个更为常用的方式来加载自己的数据集:
import pandas as pddf = pd.read_csv('grades.csv')print(df.head())pandas模块支持加载的数据格式非常的丰富,除了csv,还有excel,json,xml,数据库,spass等。
数据清洗
在正式分析数据之前,我们需要先对数据进行清洗,毕竟很多情况下,数据中都会存在一些问题,比如有些值是缺失的,有些值是重复的,有些还需要进行类型转换。
我们先来看看各列数据的缺失情况:
import seaborn as snsdf = sns.load_dataset('titanic')print(df.isnull().sum())输出的结果是这样的:
survived 0pclass 0sex 0age 177sibsp 0parch 0fare 0embarked 2class 0who 0adult_male 0deck 688embark_town 2alive 0alone 0dtype: int64从这个结果中我们可以看出age,deck,embarked,embark_town是有数据缺失的,尤其是deck列缺失严重,因为在前面我们用df.info()方法来查信息时得知有891条记录,而这一列缺失了688条。
对于age(年龄)这一列,我们可以考虑用中位数填充,这样鲁棒性更强:
df['age'] = df['age'].fillna(df['age'].median())使用fillna()来填充缺失值,填充的值是使用age的中位数,这个通过df['age'].median()计算得到年龄的中位数。
对于deck(甲板位置)这一列,缺失值过多,就没必要再分析了,所以可以直接删除:
df = df.drop(columns=['deck'])对于embarked(登船港口)可以用众数填充:
mode_town = df['embarked'].mode()[0]df['embarked'] = df['embarked'].fillna(mode_town)为什么用众数?我们先来看一下embarked这一列都是什么数据:
print(df['embarked'].value_counts())这行代码会输出以下内容:
embarkedS 644C 168Q 77Name: count, dtype: int64embarked是类别数据,它有三个取值S,C,Q,这就没法做平均数、中位数之类的计算,那我们就可以选一个出现最多的分类,也就是用众数。众数使用mode()方法来计算,因为得到的众数可能有多个,所以我们使用索引0来取第一个值。
对于embark_town,因为它是和embarked对应的,所以我们也可以用众数来填充,他们的对应关系是这样的:
S → SouthamptonC → CherbourgQ → Queenstown我们可以先做一个映射关系,然后再填充空值:
town_map = {'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'}# 只对 embark_town 为缺失值的位置进行填充mask = df['embark_town'].isna()df.loc[mask, 'embark_town'] = df.loc[mask, 'embarked'].map(town_map)数据中可能存在一些重复数据,我们可以用drop_duplicates()方法来删除重复数据:
df = df.drop_duplicates()数据清洗完之后,我们来简单验证一下清洗的结果:
print(df.isnull().sum())print(f'清洗后数据形状:{df.shape}')上面的代码执行后输出如下内容:
survived 0pclass 0sex 0age 0sibsp 0parch 0fare 0embarked 0class 0who 0adult_male 0embark_town 0alive 0alone 0dtype: int64清洗后数据形状:(775, 14)我们可以看出已经没有空数据了,现在数据还剩余775行,14列。
数据加工与分析
数据清洗完成之后,就可以进行数据的加工与分析了,比如我们想看一下titanic数据集中乘客的平均年龄和平均票价:
import numpy as npavg_age = np.mean(df['age'])avg_fare = np.mean(df['fare'])print(f'平均年龄:{avg_age:.2f}岁,平均票价:{avg_fare:.2f}美元')如果我们想了解数据中性别与生存率的关系,可以使用分组聚合的方式实现:
sex_survive = df.groupby('sex')['survived'].mean()print(sex_survive)上述代码会有如下输出:
sexfemale 0.739726male 0.215321Name: survived, dtype: float64我们也可以使用同样的方法来研究一下舱位等级与生存率的关系:
pcls_suvive = df.groupby('pclass')['survived'].mean()print(pcls_suvive)会输出以下内容:
pclass1 0.6333332 0.5060983 0.259352Name: survived, dtype: float64性别与生存率的关系,舱位与生存率的关系,我们都是从单个维度来分析数据,当然也可以从多个维度来分析数据,比如性别和舱位与生存率的关系,这就是需要用透视表来分析了:
import pandas as pdpivot_tab = pd.pivot_table(df, values='survived', index='sex', columns='pclass')print(pivot_tab)上面的代码会输出:
pclass 1 2 3sex female 0.967742 0.916667 0.472441male 0.367521 0.184783 0.160584所谓透视表可以理解为多维度交互式的统计表,可以用pandas模块中的pivot_table()方法实现,在这个方法中:index参数表示按行分组的字段,columns表示按列分组的字段,values表示要统计的字段。
还有一个常用参数是aggfunc,表示按照什么方式来计算,省略不写就是默认按照mean(平均值)计算,也可以自定义计算方法。
我们通过数据的字段之间的关系能够找到一些相对明显的规律,也可以通过新增特征来找到一些看不见的规律,所谓新增特征指的是基于现有的数据通过数学运算、业务理解等创造出的全新的字段,它可能更有助于发现数据间的规律。
比如我们可以把杂乱的数字年龄变成清晰的人群分类:
bins = [0, 12, 18, 35, 60, 100]labels = ['孩童', '少年', '青年', '中年', '老年']df['age_group'] = pd.cut(df['age'], bins= bins, labels=labels)我们创建了一个新的age_group列,后续分析还会用的到。
数据可视化
前面输出的结果都是文本,所谓一图胜千言,Python中Matplotlib和Seaborn模块就能帮助我们完成这个任务,可以实现柱状图、饼图、热力图、箱线图、计数图等。
柱状图
比如我们可以将前面分析的性别与生存率关系绘制成柱状图:
import matplotlib.pyplot as pltplt.figure(figsize=(6, 4))sex_survive.plot(kind='bar', color=['#1f77b4', '#ff7f0e'])plt.title('不同性别生存率对比', fontsize=12)plt.xlabel('性别')plt.ylabel('生存率')plt.xticks(rotation = 0)plt.tight_layout()plt.show()我们使用matplotlib.pyplot来绘制柱状图,其中:figsize是指定画布的大小,plot()方法来绘制柱状图,title()方法设置图标标题,xlabel()设置x轴的标签,ylabel()设置y轴的标签,xticks()设置x轴上标签的旋转角度,这里就是分组的female和male标签,设置0就是水平显示,tight_layout()是自动调整图标内的布局,show()方法则是显示图标。
执行上述的代码就可以看到有类似下面的图片显示:
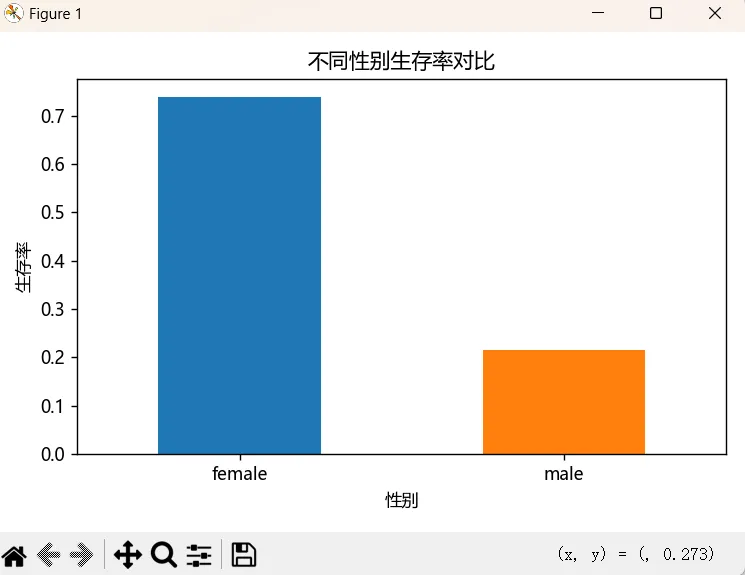
刚开始这个图中会出现一些问题,就是设置的一些中文信息都不能正常显示,都变成了方格,我们需要进行一些设置:
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']这样就可以正常显示中文信息了。
上面我们使用plot()方法绘制柱状图实际上是要基于已经手动聚合的数据,如果想直接基于原始数据也可以:
plt.figure(figsize=(6, 4))sns.barplot(data=df, x='sex', y='survived')plt.title('不同性别生存率对比', fontsize=12)plt.xlabel('性别')plt.ylabel('生存率')plt.xticks(rotation = 0)plt.tight_layout()plt.show()上面的代码执行后会显示如下图:
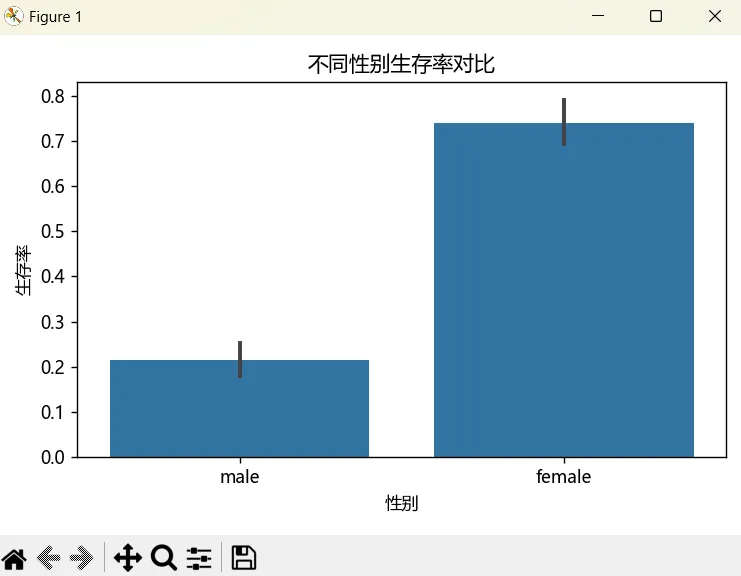
barplot()方法会自动添加置信区间(黑色的竖线),如果不想显示,可以设置ci参数去掉:
sns.barplot(data=df, x='sex', y='survived', ci=None)饼图
如果我们想看一下乘客的遇难和幸存人数占比情况,可以用饼图,使用pie()方法来实现:
survive_count = df['survived'].value_counts()plt.figure(figsize=(6, 6))plt.pie(survive_count, labels=['遇难', '幸存'], autopct='%1.1f%%', colors=['#ff6b6b', '#4ecdc4'], startangle=90 )plt.title('乘客生存占比情况')plt.show()执行上述代码,可以看到如下图:
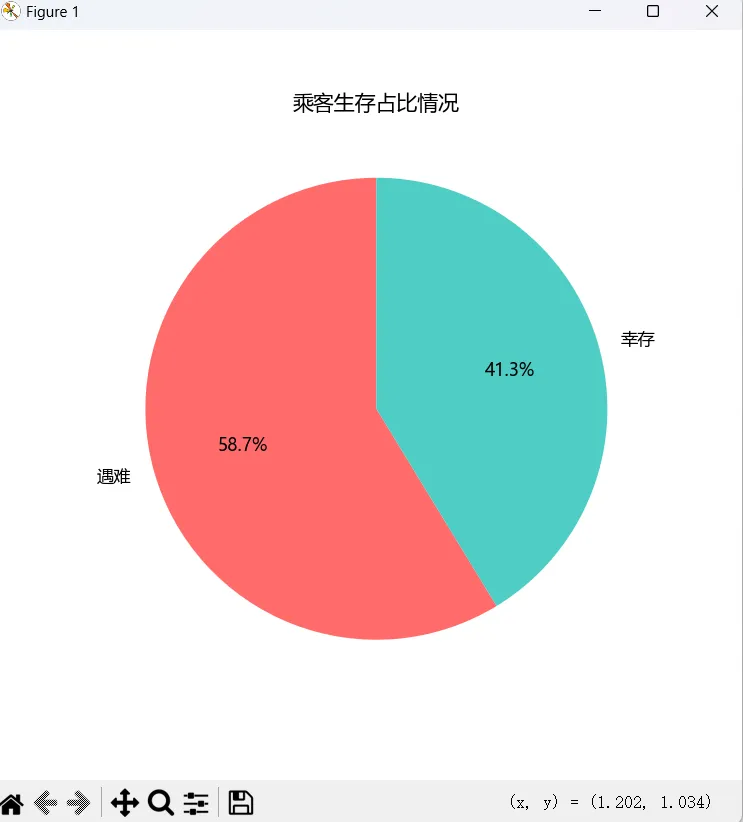
通过value_counts()来计算幸存和遇难人数,将其作为pie()方法的输入数据,然后通过labels设置显示的标签,autopct设置百分比的显示格式,colors设置饼图的每一块的颜色,startangle决定了饼状图第一刀从哪切,0度是3点钟方向,逆时针为正,也就是12点钟方向为90度,9点钟方向为180度,也可以顺时针,比如6点钟方向为-90度。
热力图
热力图能够帮助我们分析两个分类变量之间的相关性或交叉分布的情况,比如我们可以看一下titanic数据中数值特征相关性:
# 选取数值型字段numberic_cols = df.select_dtypes(include=[np.number])# 计算相关系数矩阵corr_matrix = numberic_cols.corr()plt.figure(figsize=(6, 6))sns.heatmap( corr_matrix, annot=True, # 显示相关系数 fmt='.2f', # 保留2位小数 cmap='coolwarm', # 红蓝配色 square=True, # 正方形格子 linewidths=0.5 # 格子边框)plt.title('数值特征相关热力图')plt.tight_layout()plt.show()我们使用seaborn模块中的heatmap()来绘制热力图,使用select_dtypes()方法来选取数值类型的字段,然后计算出系数矩阵,annot参数用于设置在图中是否显示相关系数,cmap参数控制热力图的颜色风格,可选值有很多,比如coolwarm、RdBu_r、viridis、plasma等,也可以自定义,square=True表示显示的格子是正方形,默认为False,是矩形格子,linewidths参数设置每个小格子之间的边框粗细。
执行上面的代码会显示下面这样的图: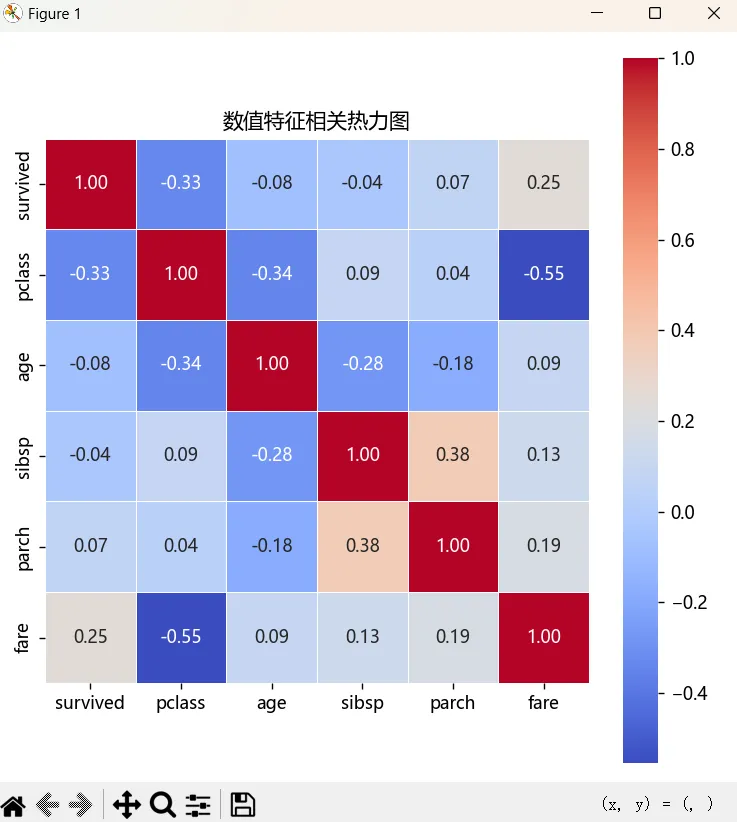
箱线图
如果我们想了解数据的分布特征、离散程度、异常值等信息,可以使用箱线图,比如想看一下不同舱位等级的票价分布以及是否存在异常票价:
plt.figure(figsize=(8, 6))sns.boxplot(x='pclass', y='fare', data=df)plt.title('不同舱位票价分布')plt.xlabel('舱位等级')plt.ylabel('票价')plt.grid(axis="y", linestyle="--", alpha=0.6)plt.tight_layout()plt.show()我们使用boxplot()方法来绘制箱线图,grid()方法用来绘制网格线,这里是在y轴方向显示网格线,执行上述代码会显示下面这样的图:
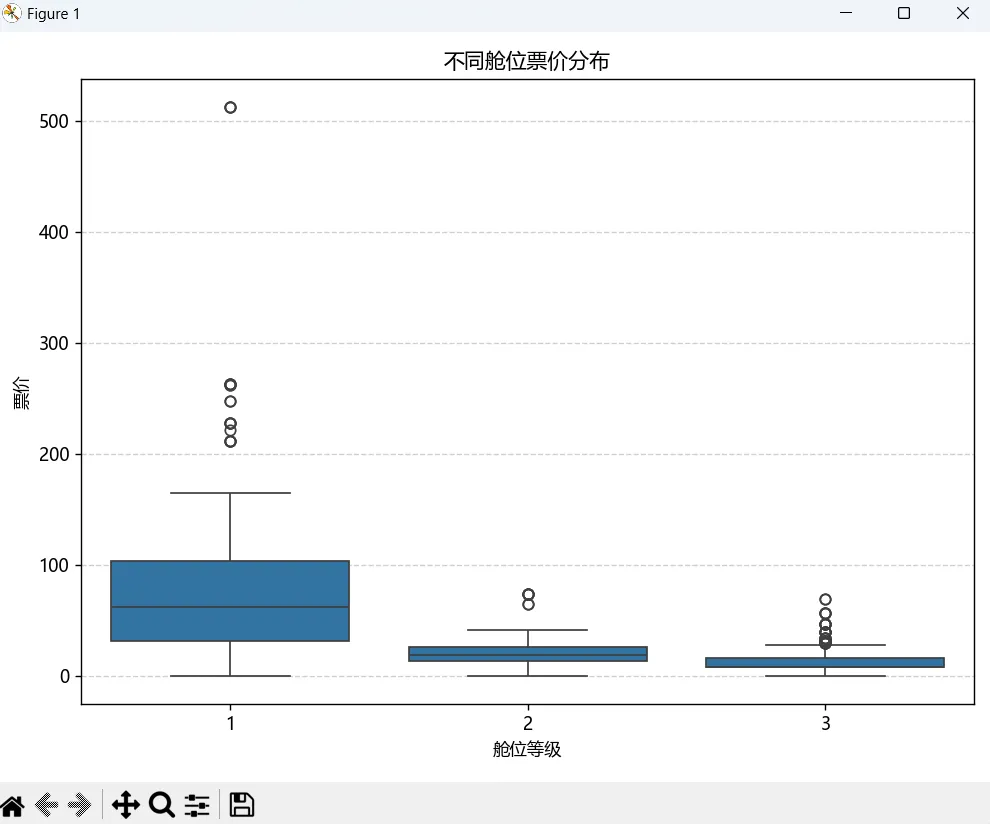
计数图
如果我们想看一下不同年龄段的生存人数分布情况,可以用计数图来实现:
plt.figure(figsize=(8, 5))sns.countplot(data=df, x='age_group', hue='survived')plt.title('不同年龄段乘客生存情况')plt.xlabel('年龄段')plt.ylabel('人数')plt.legend(title='是否生存', labels=['是', '否'])plt.tight_layout()plt.show()计数图使用countplot()方法来绘制,其中参数x定义了横轴分类,这用到了我们前面创建过的新特征age_group,划分了不同的年龄段,hue参数是用颜色来区分x轴分类中的不同子类,这里就是否生存两个分类。legend()方法是为图形添加图例,说明不同颜色对应的分类含义。
运行上面的代码,可以看到类似下图效果:
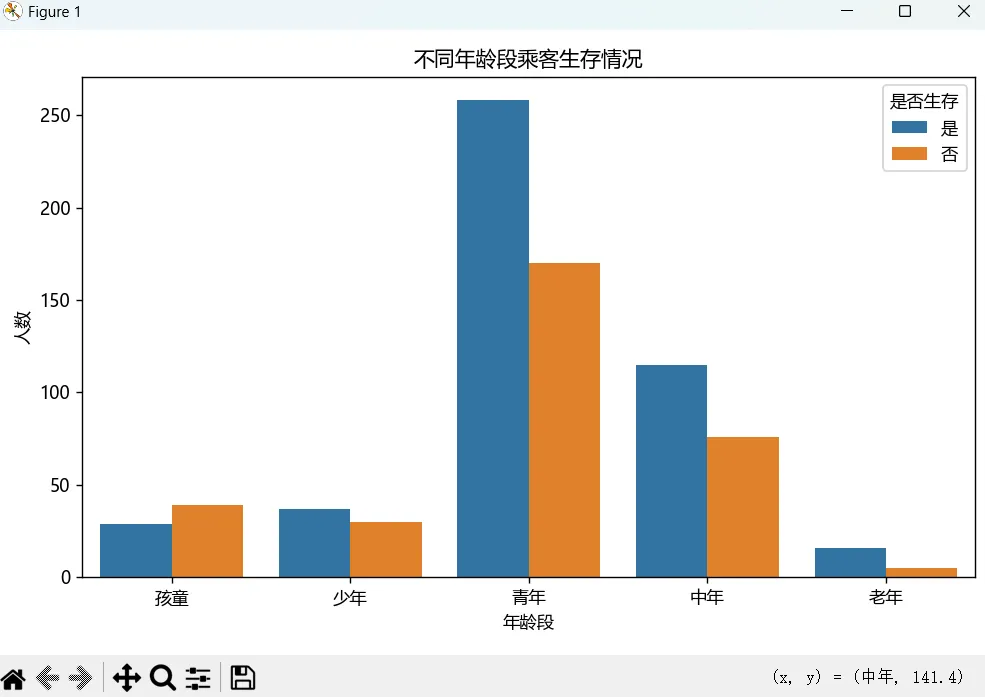
更多类型的图
上面我们提到的几种可视化图是比较常用的几种,Python结合不同的库支持更多的图表可视化,这取决于我们想做什么,比如地理空间可视化可以展示地图、气泡地图、路径地图等,比如多维数据可视化可以用3D散点图、雷达图等。需要展示什么样的图,我们可以再去查找相关的库和资料即可。
数据分析结论
经过一番数据分析,我们需要得出一些结论,这些结论或许可以支撑业务决策优化策略;或许可以诊断问题根源,精准改进;或许可以预测趋势,提前布局;或许可以提升效率。总之通过数据分析与实际问题业务关联起来,最终有助于我们的行动或决策。
我们对内置数据集titanic的分析,也可以得出一些结论,比如:1)从性别与生存率关系柱状图,我们可以看出女性生存率远高于男性,这反映了当时“妇女和儿童优先”的救援原则。2)从乘客生存占比饼状图,我们可以看出约三分之二的乘客不幸遇难,这反映了这场海难的严重性。3)从舱位与票价的箱线图,我们可以看出一等舱乘客支付的票价最高,也存在一些票价异常值。
Jupyter
在数据分析中,Jupyter是一个非常常用的工具,这里我们在vscode中安装一下这个插件就可以使用了,以下是基本步骤:1)在扩展中搜索Jupyter(由Microsoft发布)并安装2)打开VSCode的终端,在控制台中使用命令(如pip,uv等)安装ipykernel3)新建.ipynb结尾的文件,这样就可以在其中编写和执行代码了
至此,这一章的主要内容就聊完了,有什么问题可以在评论区交流。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 一图精讲Python的顶级框架
- Python高并发核心架构:用STOMP协议玩转Pub/Sub发布订阅模式
- 100 个文件要重命名?Python 5 行代码搞定
- Python 编程作业自动评分系统设计与教学实践
- Python自动化办公:3秒统一100份Word格式
- 7.Ros2系列课程之-Python编写客户端引用自定义服务接口
- 如何学习python
- 一键回测整个策略库:让 Python 帮你自动筛选交易策略
- 北航python我惹你没..我感觉我真的要完了
- 赛博安全狗:Linux容器逃逸漏洞风险通报 / Silent Ransom勒索攻击律所 (06月08日)
