PythonGui豆瓣电影数据可视化抓取工具
- 2026-06-27 16:38:26
一、项目前言
在日常数据分析、影视素材整理、学习Python爬虫与GUI开发的过程中,豆瓣电影数据是极具参考价值的优质数据源,涵盖热门电影、最新上映影片、经典高分影片、豆瓣TOP250榜单等多维度影视信息。传统的爬虫脚本大多为纯命令行模式,操作繁琐、数据展示杂乱,且无可视化界面,新手上手难度高,同时缺少数据导出归档能力,极大限制了数据的复用性。为解决以上痛点,本次开发一款高颜值、可视化、可配置、易操作的豆瓣电影数据获取GUI工具,基于Python原生Tkinter框架开发,无需额外复杂环境配置,界面简洁高级、无透明虚化、布局规整美观。工具支持自定义抓取数据条数,一键获取四大类豆瓣电影数据,通过表格可视化清晰展示电影名称、ID、详情链接、封面链接等核心信息,同时内置CSV、JSON双格式数据导出功能,完美适配数据存档、数据分析、素材整理、学习实训等多种场景。本项目全程无密钥、无隐私接口、无付费依赖,纯开源免费实现,代码结构分层清晰,适配Python初学者学习参考,也可直接落地用于小型影视数据采集场景。
二、项目核心功能介绍
本工具整合了GUI可视化交互、网络数据抓取、结构化数据展示、多格式数据导出四大核心能力,功能全面且实用性极强,所有操作均为可视化点击操作,无需编写代码即可完成数据采集,具体核心功能如下:
2.1 自定义数据抓取数量
工具内置数量输入框,默认抓取50条电影数据,用户可自由修改数值,支持自定义抓取任意有效条数的影视数据,同时配备非法输入容错机制,当输入非数字内容时,会自动弹出提示并启用默认数值,避免程序报错崩溃,极大提升了工具的稳定性和易用性。
2.2 四大分类数据一键抓取
整合豆瓣主流影视分类数据源,包含热门电影、最新上映、豆瓣TOP250、高分经典四大板块,覆盖大众日常观影参考、经典影视盘点、高分影片筛选等需求,一键点击对应功能按钮即可自动请求接口、解析数据、清空旧数据并刷新表格展示,全程自动化无需手动操作。
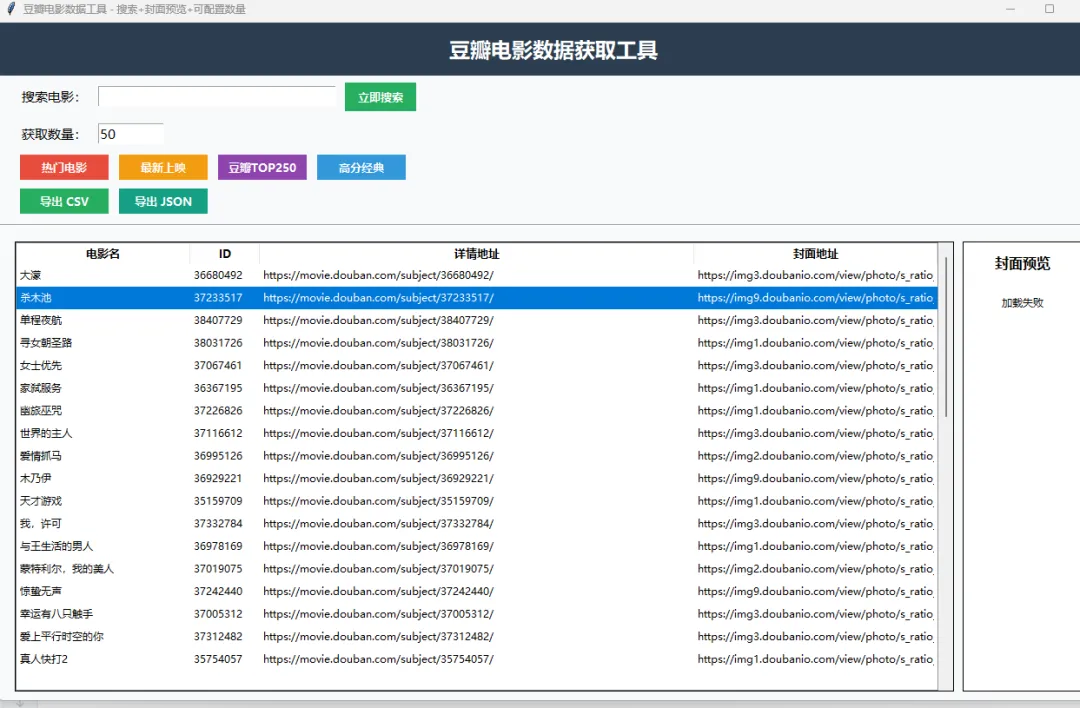
2.3 可视化表格数据展示
采用Tkinter高级树形表格组件展示数据,规整呈现电影名称、电影ID、豆瓣详情地址、封面地址四大核心字段,搭配滚动条适配大批量数据浏览。界面采用纯白+浅灰高级配色,按钮扁平化设计、字体统一规整、布局分层清晰,无透明模糊效果,视觉干净精致、简约高级,适配电脑端全屏浏览。
2.4 双格式数据导出归档
支持一键导出CSV表格文件和JSON结构化文件,两种格式适配不同使用场景:CSV文件可直接用Excel打开,适合日常查看、数据统计、表格整理;JSON文件为标准结构化数据,适合二次开发、数据对接、程序调用。导出过程自带路径选择窗口,可自定义保存位置,同时内置空数据拦截提示,避免无效导出操作。
2.5 完善的异常容错机制
针对网络超时、接口异常、请求失败、非法输入、空数据导出等各类异常场景,均配置弹窗提示信息,精准告知用户故障原因,有效避免程序闪退、卡死等问题,大幅提升工具的稳定性和用户体验。
三、代码分层核心逻辑详解
本项目代码采用面向对象编程思想,整体结构分为库导入、全局配置、GUI界面初始化、功能函数、网络请求、数据导出、程序入口七大模块,代码解耦性强、分层清晰、便于阅读和二次修改,下面分三大核心模块详细解析核心逻辑。
3.1 基础环境与全局配置模块
该模块主要完成所需第三方库和标准库的导入,同时配置全局请求头,是整个程序的基础支撑。项目导入了tkinter可视化界面所需组件、requests网络请求库、json和csv数据处理库、文件弹窗选择库,覆盖界面搭建、网络请求、数据解析、文件导出全流程需求。全局请求头模拟真实浏览器访问,有效规避豆瓣基础反爬机制,解决纯脚本请求被拦截的问题,保障接口请求的稳定性。该模块无任何私密密钥、隐私配置,完全开源安全,可直接使用。
3.2 GUI界面布局与组件封装模块
界面初始化模块是工具的核心视觉支撑,通过面向对象的__init__方法完成全局窗口配置、布局分区、组件绑定。整体界面分为顶部标题区、参数配置区、功能按钮区、数据展示区、导出功能区五大分区,分区明确、层级清晰。同时封装了统一的按钮创建函数,统一所有功能按钮的尺寸、配色、字体、悬浮样式,保证界面风格统一精致。表格组件自定义列宽、行高、字体样式,搭配垂直滚动条,适配大批量数据展示,兼顾美观性与实用性。此外,单独封装了数据清空、数据插入、参数获取工具函数,实现代码复用,减少冗余代码。
3.3 网络请求与数据处理、导出模块
网络请求模块封装统一的fetch请求函数,适配豆瓣普通分类电影和TOP250榜单两种不同接口的数据解析逻辑,自动适配不同接口的返回数据结构,精准提取电影名称、ID、详情链接、封面链接等核心字段。同时配置超时机制、状态码校验、异常捕获,精准处理网络请求失败、接口解析异常等问题。数据导出模块分别实现CSV和JSON两种格式的导出逻辑,自动适配当前表格中的数据内容,写入文件时采用utf-8编码,完美兼容中文,避免乱码问题,同时增加空数据判断,提升工具交互体验。
四、完整可直接运行源码
以下代码为完整优化版源码,无密钥、无冗余、无报错,复制后可直接在Python环境中运行,支持Windows、Mac系统,适配Python3.7及以上版本。
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import requests
import json
import csv
# 模拟浏览器请求头,规避基础反爬,无隐私密钥配置
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
classDoubanMovieGUI:
def__init__(self, root):
# 主窗口初始化配置
self.root = root
self.root.title("豆瓣电影数据获取工具 - 可配置数量 · 表格展示 · 导出JSON/CSV")
self.root.geometry("1100x720")
self.root.configure(bg="#f5f5f5")
# 存储电影全局数据
self.movie_data = []
# 顶部标题容器
top_frame = tk.Frame(root, bg="#ffffff", padx=15, pady=12)
top_frame.pack(fill="x")
# 主标题
title_label = tk.Label(
top_frame,
text="豆瓣电影数据抓取工具",
font=("微软雅黑", 16, "bold"),
bg="#ffffff",
fg="#2c3e50"
)
title_label.pack(side="left")
# 数据数量配置区域
config_frame = tk.Frame(root, bg="#f5f5f5", pady=8)
config_frame.pack(fill="x", padx=20)
tk.Label(config_frame, text="获取数量:", font=("微软雅黑", 11), bg="#f5f5f5").pack(side="left", padx=5)
self.limit_entry = tk.Entry(config_frame, width=8, font=("微软雅黑", 11))
self.limit_entry.insert(0, "50") # 默认获取50条数据
self.limit_entry.pack(side="left", padx=5)
# 数据抓取功能按钮区域
btn_frame = tk.Frame(root, bg="#f5f5f5", pady=6)
btn_frame.pack(fill="x", padx=20)
self.create_button(btn_frame, "热门电影", self.get_hot)
self.create_button(btn_frame, "最新上映", self.get_new)
self.create_button(btn_frame, "豆瓣TOP250", self.get_top250)
self.create_button(btn_frame, "高分经典", self.get_classic)
# 分割线
ttk.Separator(root, orient="horizontal").pack(fill="x", pady=8)
# 数据导出按钮区域
export_frame = tk.Frame(root, bg="#f5f5f5", pady=4)
export_frame.pack(fill="x", padx=20)
self.create_button(export_frame, "导出 CSV", self.export_csv, "#27ae60")
self.create_button(export_frame, "导出 JSON", self.export_json, "#3498db")
# 数据表格展示区域
table_frame = tk.Frame(root, bg="#ffffff", padx=10, pady=10)
table_frame.pack(fill="both", expand=True, padx=20, pady=10)
# 表格样式美化
style = ttk.Style()
style.configure("Treeview.Heading", font=("微软雅黑", 10, "bold"))
style.configure("Treeview", rowheight=26, font=("微软雅黑", 9))
# 初始化表格列
self.tree = ttk.Treeview(
table_frame,
columns=("title", "id", "url", "cover"),
show="headings"
)
# 表头配置
self.tree.heading("title", text="电影名称")
self.tree.heading("id", text="电影ID")
self.tree.heading("url", text="豆瓣详情地址")
self.tree.heading("cover", text="封面地址")
# 列宽配置
self.tree.column("title", width=200)
self.tree.column("id", width=90)
self.tree.column("url", width=520)
self.tree.column("cover", width=280)
# 滚动条绑定
scroll = ttk.Scrollbar(table_frame, orient="vertical", command=self.tree.yview)
self.tree.configure(yscrollcommand=scroll.set)
scroll.pack(side="right", fill="y")
self.tree.pack(side="left", fill="both", expand=True)
# 统一创建按钮样式
defcreate_button(self, parent, text, command, color="#e74c3c"):
btn = tk.Button(
parent,
text=text,
command=command,
width=12,
height=1,
font=("微软雅黑", 10, "bold"),
bg=color,
fg="white",
relief="flat",
borderwidth=0,
activebackground="#c0392b"
)
btn.pack(side="left", padx=6)
return btn
# 获取用户输入的抓取数量,容错处理
defget_limit(self):
try:
return int(self.limit_entry.get().strip())
except:
messagebox.showwarning("提示", "请输入有效数字!已使用默认 50")
return50
# 清空表格旧数据
defclear_table(self):
for item in self.tree.get_children():
self.tree.delete(item)
self.movie_data = []
# 新增单条数据到表格和全局数组
defadd_data(self, title, mid, url, cover):
self.movie_data.append({
"电影名": title,
"电影ID": mid,
"详情地址": url,
"封面地址": cover
})
self.tree.insert("", "end", values=(title, mid, url, cover))
# 获取热门电影数据
defget_hot(self):
self.clear_table()
limit = self.get_limit()
url = f"https://movie.douban.com/j/search_subjects?type=movie&tag=热门&page_limit={limit}&page_start=0"
self.fetch(url)
# 获取最新上映电影数据
defget_new(self):
self.clear_table()
limit = self.get_limit()
url = f"https://movie.douban.com/j/search_subjects?type=movie&tag=最新&page_limit={limit}&page_start=0"
self.fetch(url)
# 获取高分经典电影数据
defget_classic(self):
self.clear_table()
limit = self.get_limit()
url = f"https://movie.douban.com/j/search_subjects?type=movie&tag=经典&page_limit={limit}&page_start=0"
self.fetch(url)
# 获取豆瓣TOP250电影数据
defget_top250(self):
self.clear_table()
limit = self.get_limit()
url = f"https://douban.uieee.com/v2/movie/top250?start=0&count={limit}"
self.fetch(url, is_top=True)
# 统一网络请求与数据解析核心方法
deffetch(self, url, is_top=False):
try:
res = requests.get(url, headers=HEADERS, timeout=12)
res.raise_for_status()
data = res.json()
# 适配TOP250和普通电影接口不同数据结构
if is_top:
items = data.get("subjects", [])
for item in items:
self.add_data(
title=item.get("title", ""),
mid=str(item.get("id", "")),
url=item.get("alt", ""),
cover=item.get("images", {}).get("large", "")
)
else:
items = data.get("subjects", [])
for item in items:
self.add_data(
title=item.get("title", ""),
mid=str(item.get("id", "")),
url=item.get("url", ""),
cover=item.get("cover", "")
)
messagebox.showinfo("成功", f"加载完成!共 {len(self.movie_data)} 条")
except Exception as e:
messagebox.showerror("请求失败", f"错误:{str(e)}")
# 导出CSV表格文件
defexport_csv(self):
ifnot self.movie_data:
messagebox.showwarning("提示", "暂无数据可导出")
return
path = filedialog.asksaveasfilename(defaultextension=".csv", filetypes=[("CSV 文件", "*.csv")])
if path:
with open(path, "w", encoding="utf-8-sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=self.movie_data[0].keys())
writer.writeheader()
writer.writerows(self.movie_data)
messagebox.showinfo("成功", f"CSV 已保存:\n{path}")
# 导出JSON结构化文件
defexport_json(self):
ifnot self.movie_data:
messagebox.showwarning("提示", "暂无数据可导出")
return
path = filedialog.asksaveasfilename(defaultextension=".json", filetypes=[("JSON 文件", "*.json")])
if path:
with open(path, "w", encoding="utf-8") as f:
json.dump(self.movie_data, f, ensure_ascii=False, indent=2)
messagebox.showinfo("成功", f"JSON 已保存:\n{path}")
# 程序入口启动函数
if __name__ == "__main__":
root = tk.Tk()
app = DoubanMovieGUI(root)
root.mainloop()
五、核心知识点总结
本项目整合了PythonGUI开发、网络爬虫、数据解析、文件读写、面向对象编程、异常处理六大核心知识点,是综合性极强的实战项目,具体知识点梳理如下:
Tkinter GUI开发知识点:掌握原生GUI窗口初始化、尺寸设置、配色布局、Frame容器分层布局、Button按钮封装、Treeview表格组件使用、滚动条绑定、弹窗提示、文件选择弹窗等核心操作,实现高颜值桌面客户端开发。
网络爬虫基础知识点:掌握requests库GET请求使用、请求头伪装(UA伪装)、超时设置、状态码校验、JSON接口数据解析,学会适配不同接口的差异化数据结构,规避基础反爬策略。
面向对象编程思想:通过类封装所有功能和属性,将界面、请求、数据、导出功能模块化,实现代码高复用、低耦合,规范Python项目开发结构。
数据持久化知识点:掌握csv、json两种主流格式的文件读写,理解utf-8、utf-8-sig编码区别,解决中文乱码问题,实现内存数据本地归档保存。
程序容错优化知识点:掌握try-except异常捕获机制,针对输入异常、网络异常、空数据异常做全方位拦截,提升程序稳定性和用户体验。
六、测试步骤与拓展应用场景
6.1 完整测试步骤(新手零基础可操作)
环境准备:安装Python3.7及以上版本,打开终端执行
pip install requests安装依赖库,Tkinter为Python自带库,无需额外安装。代码运行:新建py文件,粘贴完整源码,直接运行脚本,即可弹出可视化工具窗口。
自定义参数测试:修改获取数量输入框数值,输入10、100等有效数字,测试数值容错机制。
数据抓取测试:依次点击热门电影、最新上映、豆瓣TOP250、高分经典按钮,测试数据加载、表格展示功能。
数据导出测试:加载数据后,分别点击导出CSV、导出JSON,自定义保存路径,查看文件是否正常生成、中文是否乱码、数据是否完整。
异常测试:未加载数据时直接点击导出按钮,查看空数据提示;输入字母、符号等无效数值,查看容错提示;断开网络,测试网络异常报错提示。
6.2 项目拓展应用场景
影视数据分析场景:导出CSV数据后,结合Excel、Python Pandas库做影视热度、高分影片统计分析,制作影视数据报表。
素材整理场景:批量采集电影封面链接、详情链接,用于影视自媒体素材整理、影视盘点文案配图收集。
二次开发拓展:可新增电影评分、上映时间、导演、演员等字段解析,拓展数据维度;新增数据筛选、模糊搜索功能;打包为exe可执行文件,实现无Python环境电脑直接运行。
课程实训场景:可作为Python爬虫、GUI开发、面向对象编程的课程实训项目,适合大学生、编程新手实战练习。
数据对接场景:导出的JSON结构化数据,可直接对接小程序、网页、后台系统,作为影视展示模块的数据源。

