上一期我们讨论了一个地基问题:Abaqus 工作流并不是一串按钮操作,而是一条工程决策链;Python 脚本化的意义,也不只是自动建模,而是让这些工程判断变成可复用、可检查、可调用的流程。
这一期继续往前走:当这些脚本化流程已经存在,AI Agent 该怎样接入?它能接管什么,哪些判断仍然要由工程师负责?
●1. AI Agent 不是魔法,它接管的是工程流程
很多人想象中的 AI CAE 是这样的:对着大模型说一句"帮我做一个冲击仿真",然后它就生成一个完整的 Abaqus 模型,网格漂亮、材料合理、接触正确、结果可信。工程师最后只需要看报告。
这个画面很诱人,但现在并不可靠。大模型并不天然拥有你的工程经验、企业建模规范,也不了解某条产品线里的隐含约束。让它直接生成脚本,就像让一个没做过这类项目的人直接上手建模。过程可能看着像那么回事,模型设置却不一定有依据。
更可靠的做法,是让 AI 在规则里调用已有流程:先查 API、规范和历史脚本,再从模板生成脚本,调用 Abaqus 执行并监控日志,最后整理结果并给出待确认的修正建议。AI 不是在"创造"仿真,而是在执行一条可追溯的工程流程。
这时常被提到的几个概念,分别对应闭环里的不同能力:
●RAG(检索增强生成)。 负责查文档、规范和历史案例,避免凭空生成。
●MCP(模型上下文协议)。 负责把 AI 接到 Abaqus 和脚本环境上,让它能执行动作。
●物理 AI(代理模型 / 降阶模型)。 负责先做快速近似判断,提前筛掉明显不合理的方案。
●多 Agent 协作。 负责把建模、求解、校核、报告拆给不同角色分工处理。
这样看,AI CAE 的重点不是"自动生成一个模型",而是把已有流程拆成可检索、可调用、可检查的步骤。
AI 接入 Abaqus 后,完整闭环会长什么样?
我们可以先把完整闭环想清楚:
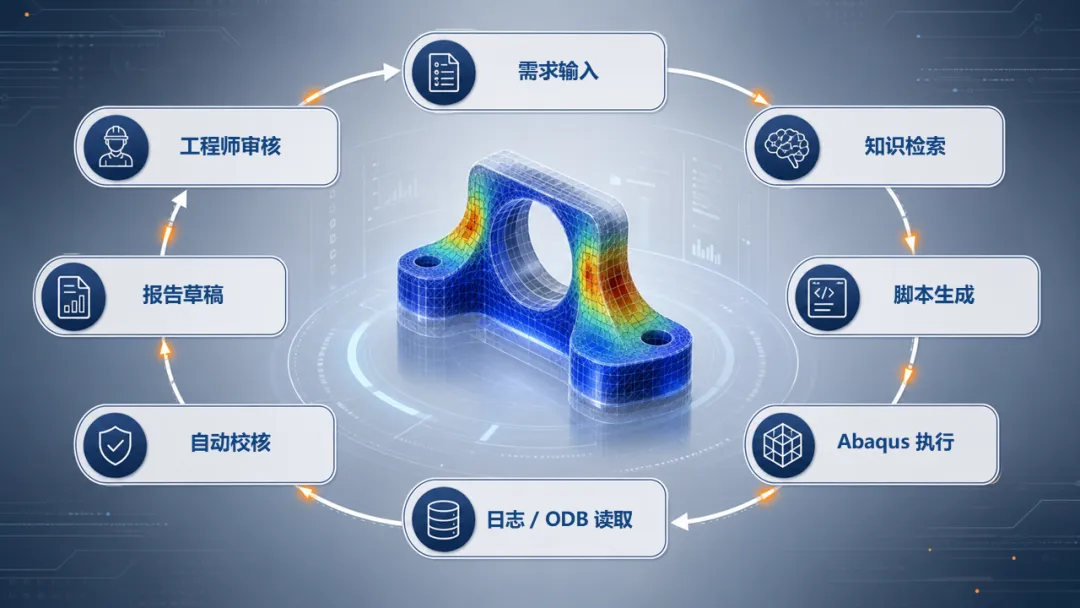
图 1|AI 接入 Abaqus 的工程闭环。 从需求到报告,所有环节都在同一条可追溯链路上。
1.工程师输入需求。 例如某支架在 5m/s 冲击下的响应评估,需要关注最大塑性应变和能量吸收。
2.AI 检索规范、历史案例和 Abaqus API。 它据此确定几何简化、网格尺度、接触类型和分析步。
3.AI 选择 Python 模板并补全参数。 生成可执行脚本。
4.Abaqus 自动建模、划网格、赋材料、设接触、建 Step。
5.系统提交 Job 并监控日志。 收敛问题或参数错误会被标出来。
6.计算完成后读取 ODB。 提取塑性应变、能量吸收和异常变形等结果。
7.系统检查关键状态。 包括收敛、能量平衡、位移和接触状态。
8.自动生成图表、结论草稿和风险提示。
9.工程师审核、解释并决定是否采信。
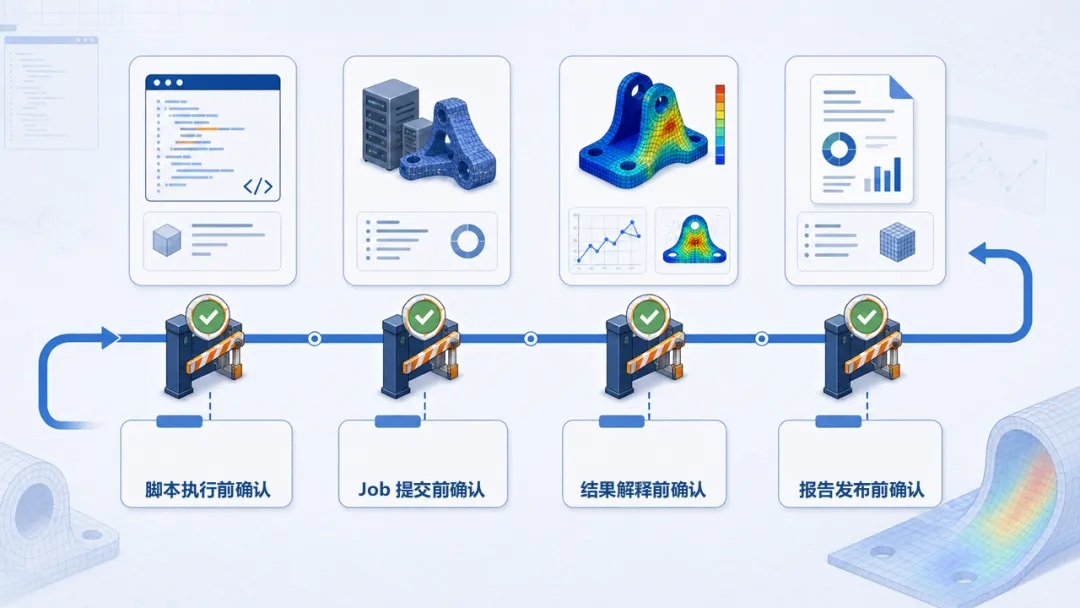
要让这个流程真正可用,至少要守住三条边界:
●AI 可以接管重复动作,但不能替工程师决定建模假设、边界条件和结果解释。
●每一步都要留下输入、参数和日志。 出了问题,团队能直接回溯到具体环节。
●脚本执行、Job 提交和报告结论前,都要有明确的人工确认点。
图 2|AI CAE 闭环中的人工确认点。 自动化流程越长,越需要在脚本执行、Job 提交、结果解释和报告发布前设置清晰的人工确认门。
这条路的起点并不神秘:先把手上的 Abaqus 流程写成稳定的 Python 能力。
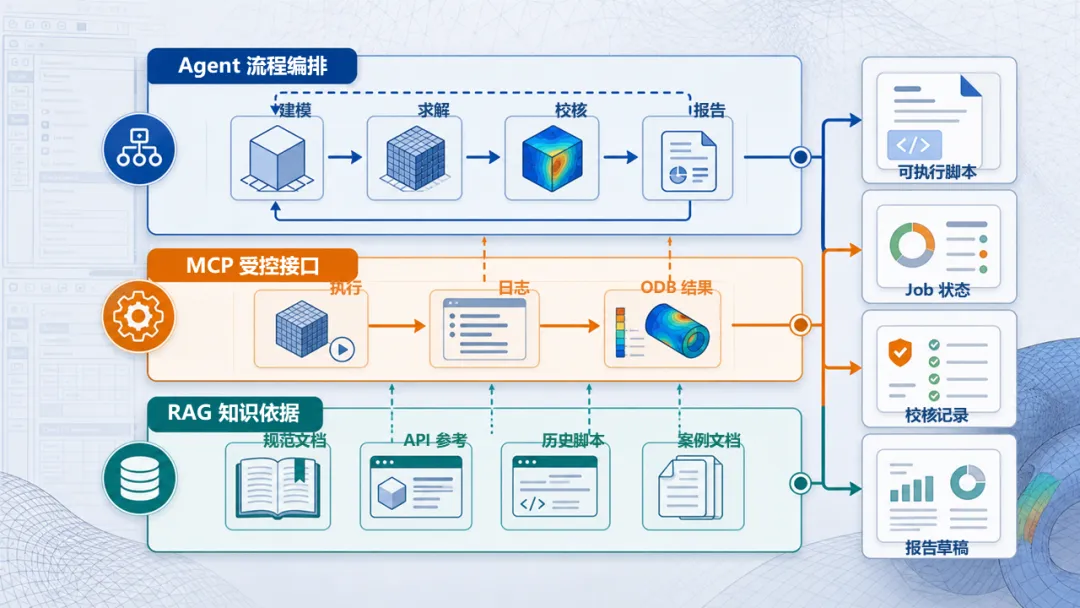
落地 AI CAE,关键不是模型多炫,而是闭环是否受控。可以把它拆成三层:
●RAG 提供依据层。 每一条建议都能追到 API、规范或历史项目。
●MCP 提供执行层。 脚本、Job 提交和日志读取都通过受控接口完成。
●Agent 流程提供组织层。 它把检索、执行、校核和报告串成一条闭环。
图 3|RAG、MCP 与 Agent 流程的三层关系。 RAG 提供依据,MCP 提供受控调用接口,Agent 流程把检索、执行、校核和报告组织成闭环。
无论自动化走到哪一步,工程判断都不能外包。现实的方向不是"AI 替代仿真工程师",而是把重复交给脚本,把流程交给智能体,把判断留给工程师。
下一期,我们进一步进入更具体的实现问题:如果真的要让 AI 查 Abaqus 文档、理解项目规范、调用 Python 脚本并读取 ODB,一个最小可行的 RAG + MCP 工作流应该怎么搭起来?
从脚本到智能体,第一步不是让 AI 自由发挥,而是先把工程流程变成它可以安全调用的能力。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
