CPU 到 92% 了。
是不是该扩容?
CPU 高时扩容,有时候也确实是最快止血方式。
但有时它可以很高,但业务没事,因为机器正在认真做计算;也可以不算特别高,但服务已经很慢,因为线程都在排队;还可以看起来像 CPU 问题,最后根因却是云盘抖了一下、容器被限流、虚拟机被宿主机抢了时间片,或者网卡软中断把几个核磨得很累。
所以看 CPU,不要把它当一个百分比。思考以下问题:
这台机器上的任务,正在算、正在等、正在被抢,还是正在被限?
一、CPU 高,不一定是坏事;CPU 忙错地方,才麻烦
服务器 CPU 被用起来,本来不是问题。
如果是一台构建机,白天有人跑编译,CPU 全核压上去,我不会太紧张。
如果是一台离线计算机器,批处理窗口里 CPU 持续 90%,只要队列按预期往前走,也不一定要动它。
甚至有些在线服务,只要延迟、错误率、队列都稳定,CPU 在一个比较高的位置运行,也未必立刻说明危险。
真正值得紧张的是另一类现象:CPU 看起来很忙,但业务没拿到等价的吞吐。比如:
- CPU 时间花在
sy、si、wa、st,而不是业务真正的计算上
这时候 CPU 指标就不能只看总量。要开始问它的去向。
同样是 1 秒钟 CPU 时间,花在用户态做业务计算,和花在内核协议栈、小包处理、频繁系统调用、IO 等待、虚拟化争用、容器 throttling 上,性质完全不一样。
一个是业务在花钱买结果。
一个可能是系统在为某种设计或环境问题付税。
我现在排 CPU,第一眼会看使用率;第二眼一定会看拆分。
topmpstat -P ALL 1
us、sy、wa、si、st 这些小字段,比“总 CPU 多少”更像线索。
二、把 CPU 时间拆开
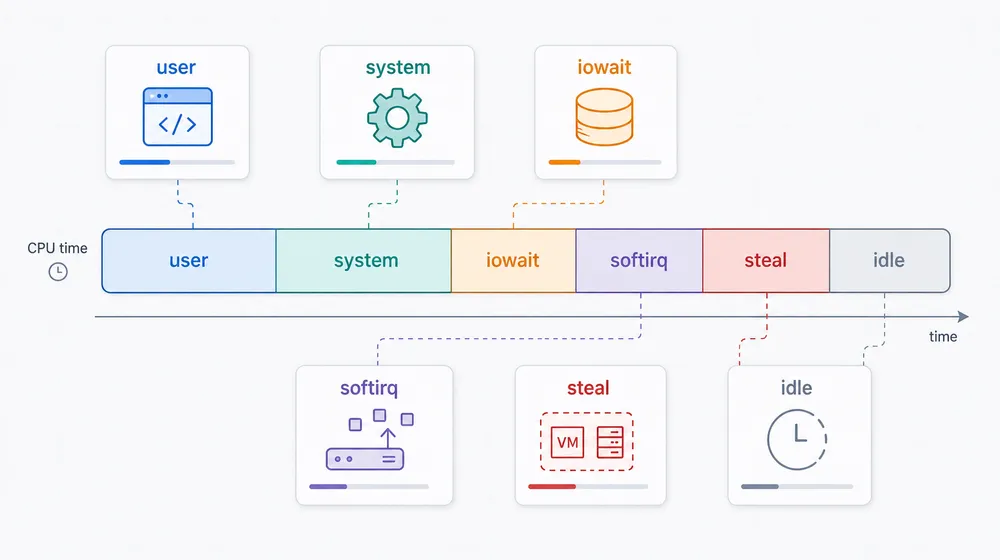
CPU 使用率要拆开看:用户态、系统态、iowait、软中断、steal 和 idle 代表不同方向top 里那一行 CPU 字段,很多人看过无数次,但真正排障时还是容易只记住一个总数。而实际分析,需要拆开看:
us 高,优先怀疑业务自己在算。
这可能是正常增长,也可能是某段代码突然变重了。比如压缩、加解密、JSON 序列化、正则、图片处理、规则引擎、报表聚合、GC、模型推理、某个循环没收住。
这类问题,方向通常在应用内部。看进程、看线程、看 profile
ps -eo pid,comm,%cpu --sort=-%cpu | headpidstat -u -t 1
sy 高,就要换个脑子。
系统态高不是业务代码“没写好”这么简单,它常常说明 CPU 花在内核路径上:系统调用、网络协议栈、文件系统、调度、锁、容器网络、iptables、conntrack、页表、驱动。
我见过一些服务,业务代码没怎么变,CPU 却涨了。最后不是算法问题,而是请求变成了大量小包,系统调用次数放大,日志写得太碎,或者 sidecar/代理把链路变长了。
这时候 perf top、strace -c、网络和文件系统指标会更有用。
perf topstrace -c -p <pid>
线上用这些工具要克制。抓短一点,范围小一点,别让排障动作变成新的扰动。
wa 高,先别把锅扣给 CPU。
它更像 CPU 在旁边等:任务卡在 IO 上,CPU 当前没别的可运行任务,只能把这段时间记成 iowait。
数据库刷盘、云盘延迟、NFS 抖动、日志同步写、对象存储挂载、文件系统元数据压力,都可能把 wa 顶起来。
si 高,优先去看网络。
软中断高经常出现在网关、代理、Ingress、日志采集、消息队列、服务网格、Kubernetes 节点上。它不是业务线程在算,而是内核在处理网络包、软中断队列和延后任务。
st 高,可能是虚拟化环境里的一个提醒。
虚拟机想跑,但宿主机没及时把物理 CPU 给它。这时候你进机器看,可能找不到一个特别能吃 CPU 的进程,但业务就是慢。
所以 CPU 排查里有一个很朴素的原则:
先排查时间花给谁,再问要不要扩容。
如果时间花在业务计算上,扩容可能有效。
如果时间花在内核、IO、网络、虚拟化或限制上,扩容就不一定有用了。
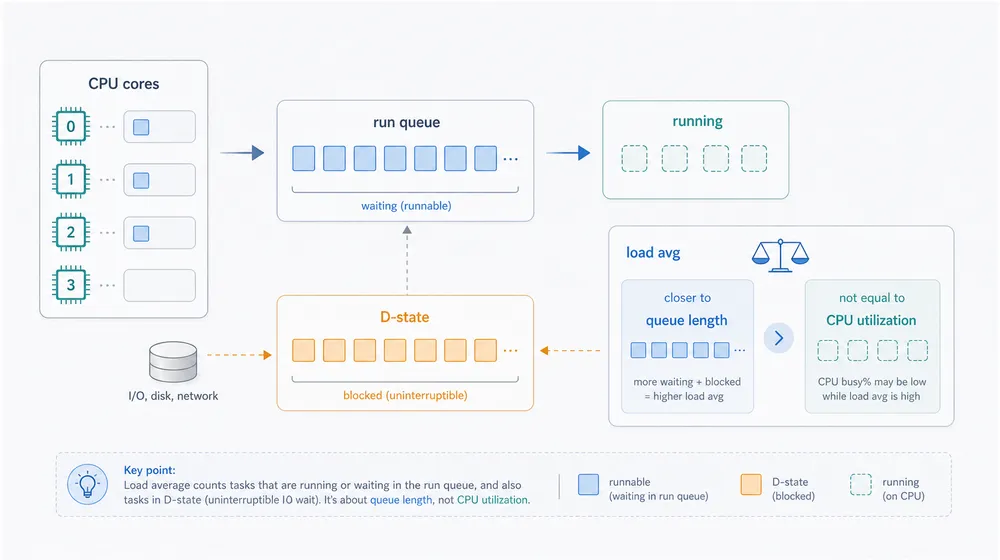
三、Load 像门口排队的人数
Load Average 更接近任务排队长度,要结合 CPU 核数、运行队列和 D 状态判断CPU 排查里另一个容易被误会的东西,是 load average。
很多人看到:
load average: 16.2, 14.7, 11.3
第一反应是:CPU 1600%?
不是。
load average 应该翻译为一段时间里“有多少任务在系统里排队或挂住”。它和 CPU 有关系,但不是 CPU 使用率。
准确地说,它统计的是可运行任务,以及一部分不可中断睡眠任务。
所以 load 高有两种完全不同的可能。
一种是 CPU 真排队。
比如 4 核机器,load 长期 20,vmstat 里 r 很高,CPU idle 很低。这大概率就是可运行任务太多,CPU 调度不过来。
另一种是任务被 IO 或内核等待挂住。
你会看到 load 很高,但 CPU idle 还有不少,wa 或 b 很明显,甚至有一堆 D 状态进程。
这时候说“CPU 不够”就容易错。可以这样来排查:
uptimenprocvmstat 1ps -eo state,pid,comm,wchan:32 | awk '$1 ~ /D/ {print}' | head
nproc 提供核心数信息,uptime 提供 load 信息,vmstat 里的 r 和 b 分别提醒你可运行队列和阻塞队列。
我更喜欢把 load 当成“门口排队的人数”。
门口人多,有可能是柜台不够,也有可能是里面某个流程卡住了。
CPU 核数就是柜台数。
r 高,像是大家真的在等柜台办理。
b 高或 D 状态多,像是柜台后面的系统卡了,人只能站着等。
这个比喻不严谨,但排障时挺好用。
四、最像 CPU 问题的,有时候是 IO 问题
iowait 它出现在 CPU 统计里,所以很多人天然觉得它属于 CPU。但它经常把你带到 IO。
我遇到过一类故障:业务延迟突然上升,CPU 图看起来也不太对,大家开始找哪个进程吃 CPU。找了一圈,没找到特别夸张的进程。
后来把 vmstat 和 iostat 放在一起看,才发现 wa 高,磁盘延迟也高。
vmstat 1iostat -xz 1pidstat -d 1
这时候 CPU 不是主犯。
它更像站在旁边等消息的人。
应用线程发起 IO,磁盘或远端存储迟迟不回来,线程继续不了。系统里如果没有别的可运行任务,CPU 就把这段时间记成 iowait。
所以 iowait 高的时候,优先问:
- 是同步日志、数据库刷盘、临时文件、备份任务,还是容器日志拖住
- 是本地盘、云盘、NFS、对象存储挂载,还是文件系统元数据
如果只盯 CPU,你会很想加核。
但真正该做的可能是拆盘、限速批任务、改日志策略、调整数据库刷盘、迁移热点目录,或者去找云盘/存储链路的问题。
这个时候 CPU 指标不是答案。它只是把另一个系统的痛,通过 wa 这种方式传了出来。
五、虚拟机和容器里,CPU 不是你看见多少就能拿到多少
宿主机有空闲,不代表容器没有被 cgroup CPU limit 限速物理机时代,上面介绍的 CPU 判断没什么大问题。机器有多少核,进程抢多少核,虽然也复杂,但边界大体清楚。
到了云主机和容器,事情就有点绕。
先说虚拟机。
如果 st 高,也就是 steal time 高,说明这台虚拟机想运行,但宿主机没有把物理 CPU 时间及时给它。
这类问题有点憋屈。
你在虚拟机里看,可能看不到哪个进程特别离谱;应用也可能没有把 us 打满。但请求还是慢,因为你以为属于你的 CPU 时间,其实被宿主机调度走了。
这时候要看云厂商监控、实例规格、宿主机争用、突发性能实例的 CPU credit,以及是不是该换规格或迁移。大部分的场景是超卖
再说容器。
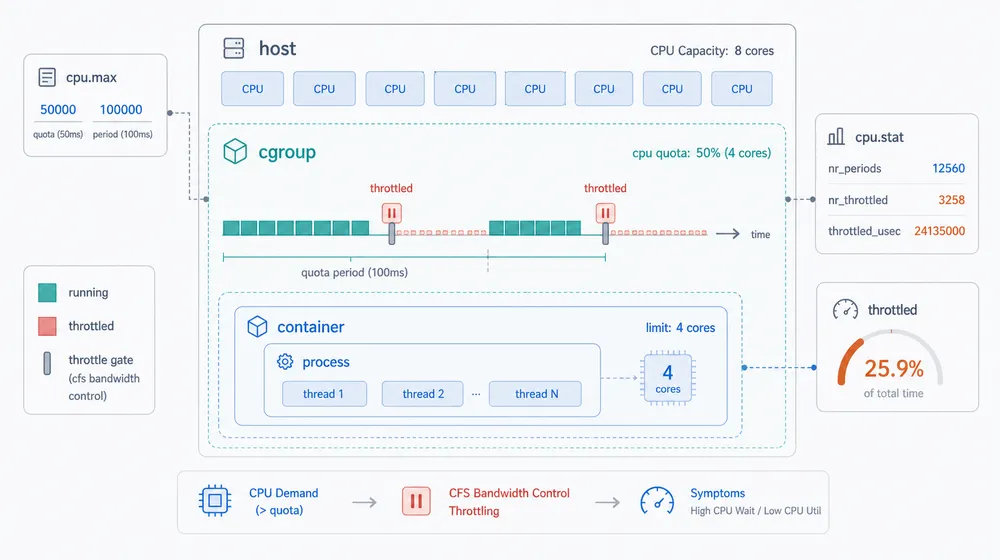
容器的坑更常见。宿主机明明有空闲,容器里的服务却慢。原因可能是它被自己的 CPU limit 卡住了。
cgroup v2 里可以看:
cat /sys/fs/cgroup/<group>/cpu.maxcat /sys/fs/cgroup/<group>/cpu.stat
cpu.max 是 quota 和 period。
cpu.stat 里的 nr_throttled、throttled_usec 会告诉你有没有被限速,以及被限了多久。
Kubernetes 里,如果给容器设了 CPU limit,本质上也会落到这类限制上。
对在线服务来说,throttling 不是“平均少一点 CPU”这么温柔。
它可能是在某个调度周期里 CPU 时间片用完了,容器必须等下一个周期。对 P99、P999 这种尾延迟指标来说,这种等待很明显。
尤其是 JVM、Go、Node.js、数据库、代理这些服务,本来就有自己的线程、GC、事件循环或 runtime 调度。再被 cgroup 限一下,症状就会变得很像“偶发抖动”。
六、系统态和软中断高时,CPU 可能被杂活磨掉了
还有些场景 CPU 高,不是业务代码在算,也不是 IO 在等,而是系统在做大量“杂活”。
最常见的是系统态和软中断。
系统态高时,特别留意几类东西:
- 容器网络、iptables、conntrack、sidecar 是否带来额外成本
软中断高时,先关注网络上:
mpstat -P ALL 1cat /proc/softirqssar -n DEV,TCP,ETCP 1
如果某几个核的软中断特别高,就继续看网卡队列、中断亲和性、RSS/RPS、丢包、重传、conntrack、代理层指标。
这种问题最容易在网关类机器上出现。
平均 CPU 看起来还好,但某几个核很累;业务上看是延迟抖、丢包、连接异常;应用进程看起来又不像主要消耗者。
还有上下文切换。
vmstat 1pidstat -w 1
上下文切换不是坏事。Linux 本来就靠调度跑很多任务。
但如果 cs 异常升高,CPU 时间可能被花在线程切来切去上,而不是花在真正推进业务上。线程池过大、锁竞争、短任务太多、频繁唤醒、忙等、sidecar 抢占,都可能把 CPU 磨掉。
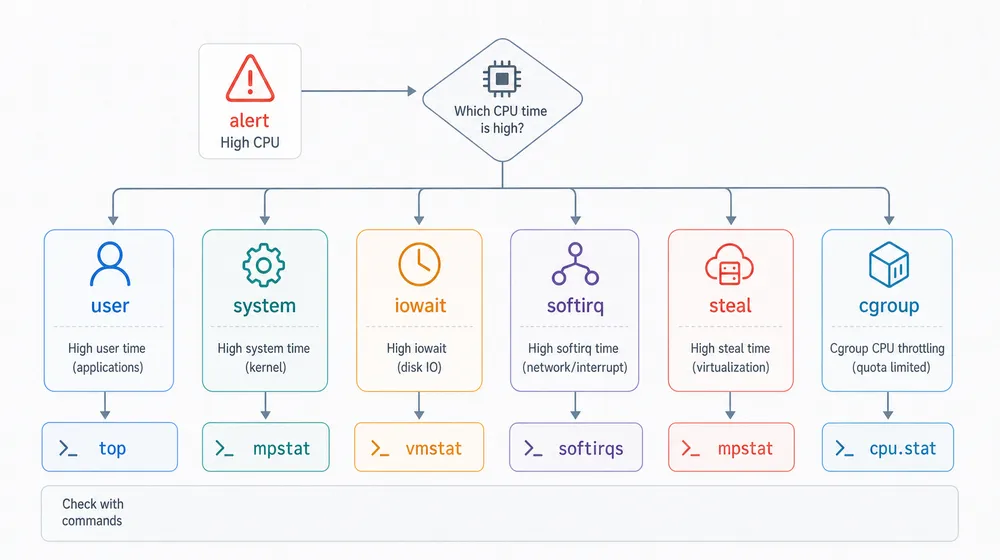
七、CPU 问题排查路径
CPU 排查要从使用率入口继续分流到用户态、系统态、IO、网络、虚拟化和 cgroup第一眼,看机器是不是在排队:
uptimenprocvmstat 1cat /proc/pressure/cpu
load 和核心数对一下,r、b 看一下,CPU PSI 看一下。
这一步的目标不是定位根因,而是判断有没有真实等待。
第二眼,看 CPU 时间去了哪里:
topmpstat -P ALL 1
us 高,往应用计算走。
sy 高,往内核路径和系统调用走。
wa 高,往 IO 走。
si 高,往网络和软中断走。
st 高,往虚拟化争用走。
第三眼,看进程和线程:
ps -eo pid,ppid,comm,%cpu,%mem --sort=-%cpu | headpidstat -u -t 1
如果是某个线程在烧,就别只看进程总量。很多问题藏在线程级别。
第四眼,按分支深入。
用户态高,进应用 profiler:Java 看 JFR、async-profiler,Go 看 pprof,Node.js 看 CPU profile 和 event loop delay。
系统态高,看 perf top、系统调用、网络栈、文件系统、容器网络、锁和线程数。
iowait 高,看 iostat -xz 1、pidstat -d 1、云盘和存储链路。
软中断高,看 /proc/softirqs、网卡队列、丢包、重传、conntrack。
steal 高,看云主机规格和宿主机争用。
容器服务慢,一定要检查下 cgroup:
cat /sys/fs/cgroup/<group>/cpu.maxcat /sys/fs/cgroup/<group>/cpu.stat
最后才决定动作。
有些场景确实该扩容。比如业务计算增长,所有核都忙,队列也起来了,应用 profile 也说明热点就是正常工作量,那扩容很合理。
但有些场景不该先扩:
CPU 不是仪表盘上的一个百分比。它更像一张时间账单。
你花掉的每一毫秒 CPU 时间,最好都能换来业务推进。
如果没有,就要弄清楚:它到底被谁拿走了,又是谁一直在等。