Python爬虫入门连载05:批量爬取网页图片,自动下载保存到本地文件夹
今天教你:用爬虫一键爬取整页所有图片,自动新建文件夹、批量下载、自动保存
一、爬图片核心思路
1.requests 访问网页,拿到源码
2.BeautifulSoup 找到所有 <img> 图片标签
3.提取图片地址 src 属性
4.自动新建存放图片的文件夹
5.循环逐个下载图片,保存到本地
二、必备知识点
·网页图片都在 <img> 标签里
·图片真实地址存在 src 里面
·有的是完整网址 https://xxx.jpg
·有的是相对路径,需要拼接主域名
三、完整可直接运行源码
四、代码逐段讲解
1. 自动建文件夹
2. 获取所有图片标签
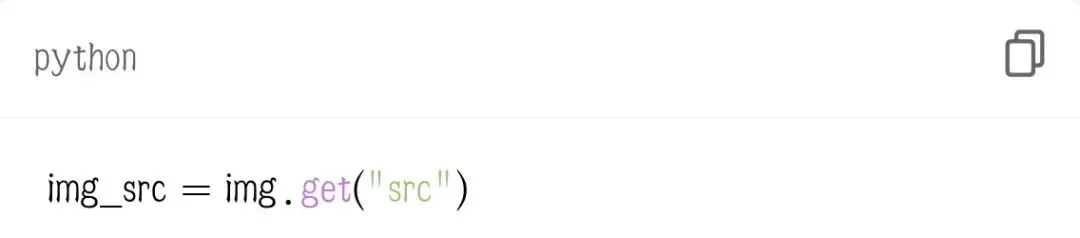
3. 提取图片地址
用 .get("src") 更安全,不会报错。4. 过滤非http链接
只下载完整网络图片地址,跳过无效相对路径。5. 下载并保存图片
图片是二进制文件,要用:
·.content 获取二进制内容
·保存模式用 wb 二进制写入
五、常见问题解决
1. 图片下载不全
网页很多图片是动态加载的,基础爬虫抓不到,后面进阶会教。2. 图片打不开
保存后缀统一用 .jpg 基本都能兼容。3. 被网站拦截
一定要带上 headers 里的 User-Agent 伪装浏览器。
六、本期小结
1.所有网页图片都在 <img> 标签 src 属性中
2.爬虫流程:拿源码 → 找img标签 → 提取链接 → 下载保存
3.自动新建文件夹,批量循环下载
4.图片下载用 .content、保存模式 wb
5.一键爬取整页图片,告别手动另存为
小作业
找一个壁纸网页,修改代码,批量爬下载一整页壁纸图片。
下期预告
Python爬虫连载06:分页爬取,自动翻页抓取多页新闻/图片数据不用手动点下一页,代码自动翻页,批量爬取几十页内容,超适合批量采集!


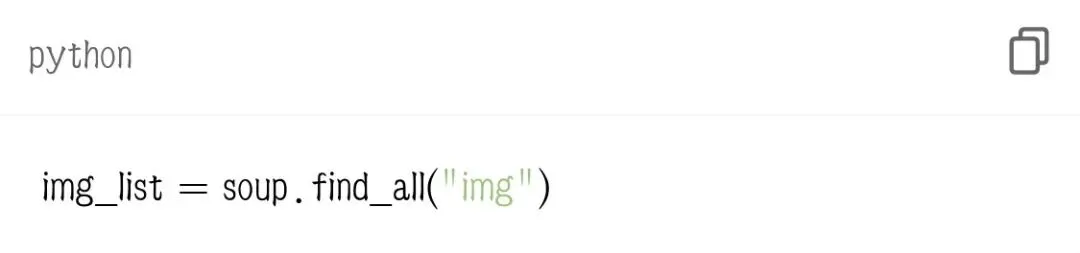
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
