本次实战采用 DrissionPage 抓包监听方案抓取小红书单篇笔记全部评论,不用 XPath 解析 DOM,直接拿到后端 JSON 结构化数据,自动时间格式转换、持久存入表格,上手门槛极低。
可采集字段
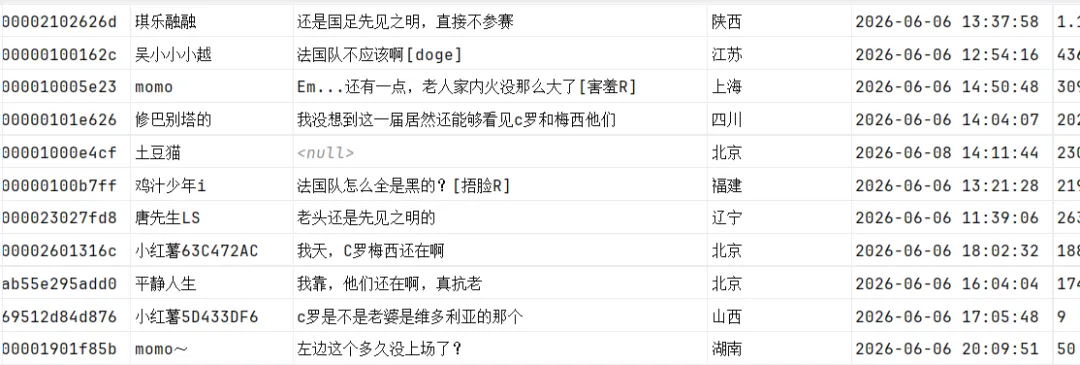
用户 ID、昵称、评论文本、发布属地、精确发布时间、点赞数、二级评论数量,全部字段自动写入 csv,Excel 可直接打开做舆情分析。
核心代码分段讲解(只讲关键逻辑)
1. 初始化 CSV 存储结构
采用 DictWriter 字典写入方式,提前定义好表头,每条评论直接打包字典一键入库,无需手动拼接列表。
csv_writer = csv.DictWriter(f, fieldnames=['用户ID','昵称','评论','发布地区','发布时间','点赞数','子评论数'])csv_writer.writeheader()
2. 开启接口监听,直达评论 API(核心亮点)
精准监听评论分页请求comment/page,跳过繁琐网页元素定位,直接捕获接口返回完整评论数据包。
dp = ChromiumPage()dp.listen.start('comment/page')dp.get('目标小红书笔记链接')
3. 时间戳标准化转换
接口返回毫秒时间戳,一行代码转为年月日时分秒可读格式,不用额外数据清洗。
datetime.fromtimestamp(index['create_time'] / 1000).strftime("%Y-%m-%d%H:%M:%S")
4. 自动滚动分页持续爬取
提取分页游标 cursor,定位最新评论节点自动下滑加载下一页,无限循环采集,无评论时自动终止程序。
cursor = json_data['data']['cursor']next_page = dp.ele(f'css:comment-{cursor}')dp.scroll.to_see(next_page)
重要提示
本代码仅限 Python 技术学习研究使用,禁止高频批量抓取大量笔记数据,遵守平台用户协议与爬虫规范。