3秒看懂它是什么
如果你做过 OCR,一定经历过这些问题:
- • PaddleOCR / Tesseract 配置复杂
而这次这个工具的思路很直接:
不用Python,不用环境配置,直接一个64位单文件跑OCR,是基于最新paddleocr v6模型的开源离线文字识别小工具
它到底是什么
这是一款:
核心目标只有一个:
把 OCR 做成“拿来就能用”的工具,而不是一套开发环境

和传统OCR工具的差异
简单对比一下更直观:
一句话总结:
从“开发项目”变成“直接用工具”
核心能力一览
1. 图片OCR识别
支持常规图片输入:
识别流程是直接输入图片 → 输出文本
2. 截图识别(重点能力)
这是比较实用的一点:
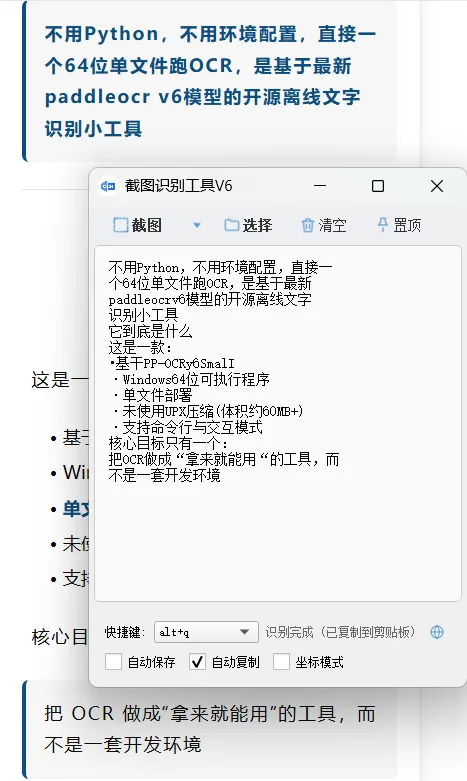
例如:
3. 图片上传识别
支持直接拖拽/上传图片进行识别处理。
更接近传统OCR软件体验,但没有安装负担。
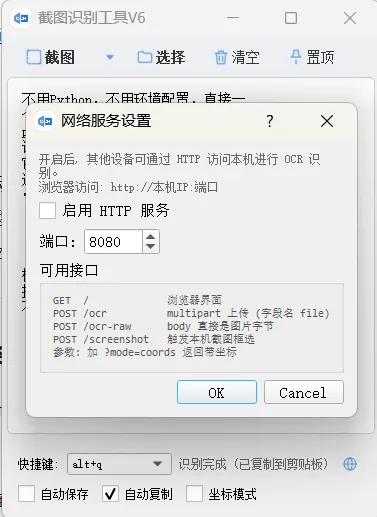
4. 远程网络访问
支持通过网络方式获取图片资源进行识别。
适合:
5. 命令行模式(CLI)
支持命令行调用,这是它工程化能力的关键:
适合:
6. -h帮助信息
提供参数说明,但有一个细节:
- •
-h 在部分 CMD 环境下可能不显示完整内容
完整参数需要参考随附说明文件
技术特点(重点)
1. PP-OCRv6 Small模型
使用的是轻量化OCR模型:
2. C++全量重写
相比Python版本:
本质是:
从“脚本OCR”升级为“工程级工具”
3. 单文件设计
整个程序只有一个可执行文件:
复制即可使用
4. 未UPX压缩(约60MB)
作者没有做二次压缩,意味着:
适合谁用
这类工具更偏“实用型用户”,不是研究型:
不适合谁
也需要明确边界:
使用方式概览
基本流程非常简单:
没有安装步骤,没有依赖配置。
下载地址
完整文件与源码:
- • https://wwbhj.lanzouu.com/b002vywawd
- • https://pan.baidu.com/s/15D84msnpOROwZ0ujrAYBJQ
一个更现实的评价
这类工具的意义不在“功能多强”,而在于:
把 OCR 从“开发问题”变成“使用问题”
也就是说:
以前你要考虑:
现在只剩一句话:
这个文件能不能直接跑
总结
这款基于 PP-OCRv6 Small 的 C++ OCR 工具,本质特点可以概括为:
它不试图做“最强OCR”,而是做“最省事OCR”。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
