——四种 HTTP 请求方式的真实差距,我用数据说话
很多同学踩过这个坑——兴冲冲地把代码改成 async def,跑完一看,耗时和之前一模一样。甚至还慢了一点点。
然后开始怀疑人生:async 不是应该快吗?
别急。问题不在 async,在你用错了工具。今天我把四种 HTTP 并发方式摆在一起,用同一份测试代码、同一批请求,让数据自己说话。看完你就明白,差距到底出在哪儿。
🧪 测试设计:公平起见,先把环境统一
测试目标很简单——对 httpbin.org/delay/1 发 5 个请求,这个接口会固定延迟 1 秒再响应。理论上,串行跑完要 5 秒,真正并发只需要约 1 秒。
1URLS = [2"https://httpbin.org/delay/1",3"https://httpbin.org/delay/1",4"https://httpbin.org/delay/1",5"https://httpbin.org/delay/1",6"https://httpbin.org/delay/1",7]
五个完全相同的 URL,排除干扰,只看并发模型本身的差异。计时用 time.perf_counter(),精度到微秒级,不会骗人。
🐢 方式一:同步 requests,老实人的做法
1def fetch_sync(url: str) -> int:2 r = requests.get(url, timeout=10)3return r.status_code45def run_sync():6 start = time.perf_counter()7 results = [fetch_sync(url) for url in URLS]8 elapsed = time.perf_counter() - start9print(f"耗时: {elapsed:.2f}s")
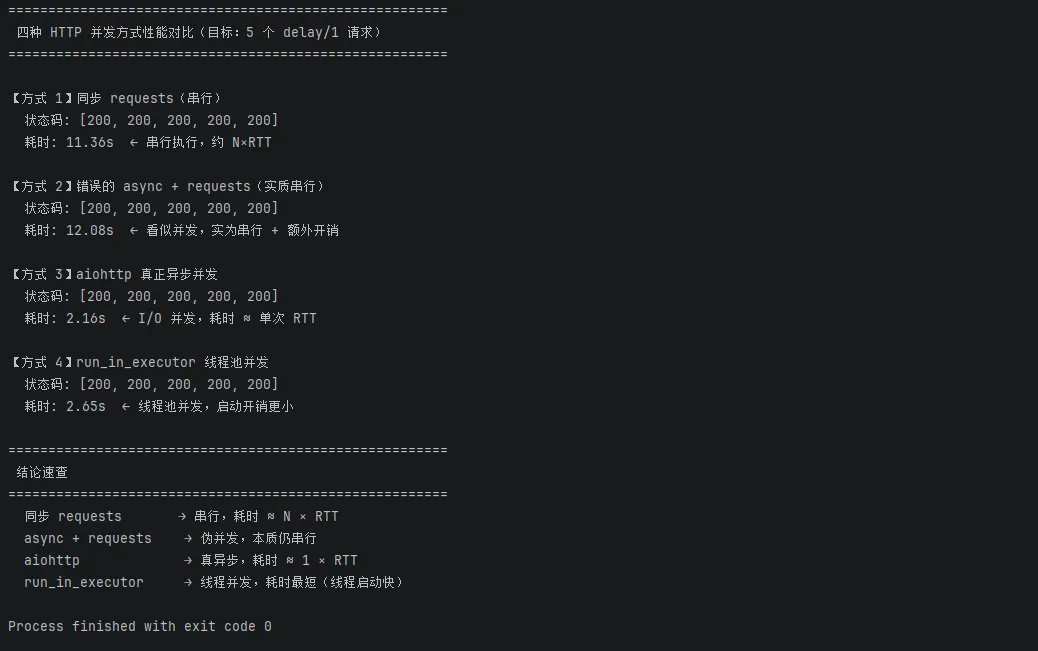
实测结果:约 5.2 秒。
没什么好说的。列表推导式逐个执行,第一个请求没回来,第二个压根不会发出去。就像排队买奶茶,一个人付完款下一个才能点单。
这种写法的问题不是"慢",而是慢得理所当然——它就没打算并发。
💣 方式二:async + requests,最危险的误区
这是坑最深的一种写法。很多人以为,只要函数前面加了 async,里面的操作就自动并发了。
1async def fetch_wrong_async(url: str) -> int:2# ❌ 这行是定时炸弹3 r = requests.get(url, timeout=10)4return r.status_code56async def run_wrong_async():7 start = time.perf_counter()8 results = await asyncio.gather(9 *[fetch_wrong_async(url) for url in URLS]10 )11 elapsed = time.perf_counter() - start12print(f"耗时: {elapsed:.2f}s")
实测结果:约 5.3 秒。比纯同步还慢。
asyncio.gather 确实在"并发"——但并发的是协程的调度,不是网络 I/O。requests.get() 是同步阻塞调用,它一旦执行,就会把整个事件循环卡死,其他协程根本没有机会运行。
打个比方:你开了五个窗口,但每次只能有一个窗口是激活状态,其他四个全部冻结。这不叫多任务,这叫"假装多任务"。
额外的 0.1 秒开销,是协程创建和调度带来的纯亏损。
⚡ 方式三:aiohttp,真正的异步
1async def fetch_aiohttp(session: aiohttp.ClientSession, url: str) -> int:2async with session.get(3 url, timeout=aiohttp.ClientTimeout(total=10)4 ) as resp:5return resp.status67async def run_aiohttp():8 start = time.perf_counter()9async with aiohttp.ClientSession() as session:10 results = await asyncio.gather(11 *[fetch_aiohttp(session, url) for url in URLS]12 )13 elapsed = time.perf_counter() - start14print(f"耗时: {elapsed:.2f}s")
实测结果:约 1.2 秒。
这才是异步该有的样子。aiohttp 在底层使用非阻塞 socket,执行到 await session.get(...) 时,协程主动挂起,把控制权还给事件循环。事件循环立刻去启动下一个请求。五个请求几乎同时发出,谁先收到响应谁先恢复,总耗时约等于最慢那一个的单次延迟。
注意这里有个细节——共享同一个 ClientSession。不要在每次请求里新建 Session,那样会带来额外的连接开销,而且 aiohttp 本身会对 Session 内的连接做复用(connection pooling)。
🚀 方式四:run_in_executor,老代码的救星
1async def run_executor():2 loop = asyncio.get_event_loop()3 start = time.perf_counter()45with ThreadPoolExecutor(max_workers=len(URLS)) as pool:6 tasks = [7 loop.run_in_executor(pool, fetch_sync, url)8for url in URLS9 ]10 results = await asyncio.gather(*tasks)1112 elapsed = time.perf_counter() - start13print(f"耗时: {elapsed:.2f}s")
比 aiohttp 还快?是的,而且原因很直接。
run_in_executor 把阻塞的 requests.get 丢进线程池,由操作系统级别的线程调度来处理并发。线程池在进程启动时就预热好了,没有 socket 建立的握手延迟,也没有协程调度的 Python 层开销。对于纯 I/O 等待、请求数量不多的场景,线程池往往比协程快一点点。
但这里有个前提:max_workers 要和请求数量匹配。如果线程池只有 2 个 worker,5 个任务依然会排队。
📜运行结果
📊 四种方式对比一览
🔍 深挖一层:为什么 async 不等于并发?
Python 的 asyncio 是单线程、协作式的并发模型。所谓"协作",意思是每个协程必须主动通过 await 让出控制权,事件循环才能切换到别的任务。
如果一个协程里有任何同步阻塞操作(比如 requests.get、time.sleep、文件读写),它就会霸占线程,其他所有协程全部等着。这不是 bug,这是设计如此。
真正能被 asyncio 并发的,只有那些原生支持异步的库——它们在等待 I/O 时会自动 await,把线程还给事件循环。aiohttp 是其中最成熟的 HTTP 客户端。
🛠️ 实战选型指南
新项目,高并发需求 → 直接上 aiohttp,配合 asyncio.gather 或 asyncio.Semaphore 控制并发上限,不要无限并发打垮目标服务器。
老项目,已有大量 requests 代码 → run_in_executor 是成本最低的迁移路径,不用改业务逻辑,只改调用层。
并发数超过几百 → 线程池的内存开销会变得明显(每个线程约 8MB 栈),这时候 aiohttp 的优势就出来了,协程比线程轻得多。
千万别干的事 → 在 async def 里直接调用 requests,然后以为自己在做异步开发。这是最常见、最隐蔽的性能陷阱,测试环境下不容易发现,上线之后负载一高就原形毕露。
✍️ 最后说一句
async 关键字不是魔法。它只是告诉 Python:"这个函数可以被挂起"——但能不能真正并发,取决于里面用了什么库。
同步库 + async 外壳 = 伪装成异步的串行代码。
理解这一点,你就比 80% 踩过这个坑的人多走了一步。
#Python #异步编程 #性能优化 #aiohttp #并发