一、单选题(每题2分,共30分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
答案 | D | C | D | D | A | C | D | C | D | C | D | D | A | A | D |
第1题 有关下列Python代码的说法,错误的是( )。
A.执行SORTED({1:1,2:4,3:9})不会报错
B.执行SORTED(range(10))不会报错
C.执行SORTED([1,20,3], Reverse = True)[::-1]不会报错
D.执行SORTED([1,None,'123'])不会报错
答案:D
知识点:Python中不同数据类型(字典、range、列表)的可排序性,以及不同类型元素混合时的排序限制(整数、None、字符串无法直接比较)。
解析:A选项,字典转换为列表时取键值,可正常排序;B选项,range对象可转换为列表排序;C选项,排序后反转列表语法正确;D选项,列表中包含整数、None和字符串,这些类型之间无法直接比较,排序时会抛出TypeError,故该说法错误。
第2题 下列Python代码用于判断一个正整数是否是质数(素数),相关说法中正确的是( )。
A.代码存在错误,比如5是质数,但因为5 % 5余数是0返回了False
B. finish_number的值应该是N // 2,当前写法将导致错误
C.当前while循环正确的前提是:所有大于3的质数都符合6k±1形式
D. while循环修改如下,其执行效果与执行时间相同。

答案:C
知识点:质数判断算法,大于3 的质数的数学特征(6k±1形式),质数判断的优化(只需检查到平方根)。
解析:A错误,代码中N==5直接返回True,不会执行后续取余判断;B错误,判断质数只需检查到sqrt(N)即可,无需到N//2;C正确,大于3的质数均符合6k±1形式(循环中i按7,11,13,17...递增);D错误,修改后的循环会检查更多数字(如4,6等),执行时间更长,效果不同。
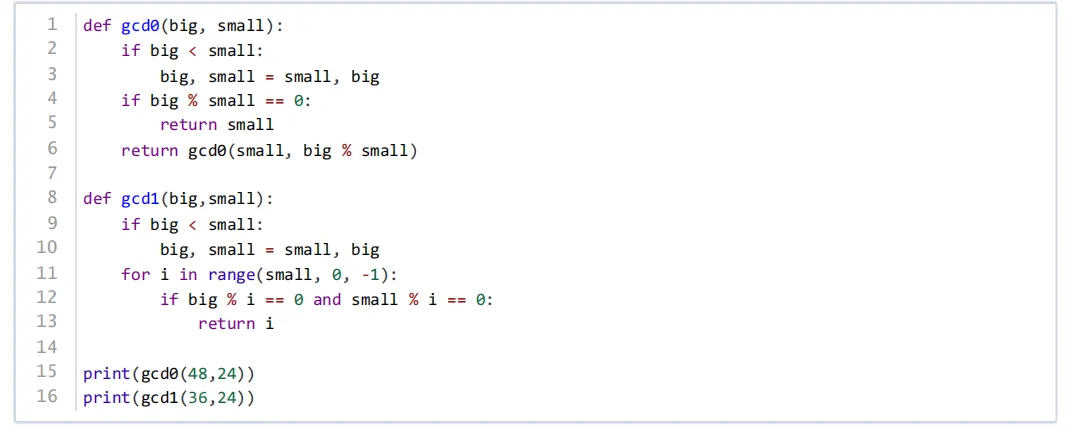
第3题 下列Python代码用于求解两个正整数的最大公约数,相关说法中错误的是( )。
A. gcd0()函数的时间复杂度为O(logN)
B. gcd1()函数的时间复杂度为O(N)
C.一般说来,gcd0()的效率高于gcd1()
D. gcd1()中的代码range(small, 0, -1)应该修改为range(small, 1, -1)
答案:D
知识点:最大公约数求解算法(辗转相除法、枚举法),两种算法的时间复杂度对比(O (logN) 与 O (N)),枚举法中边界值的重要性(需包含1)。
解析:A正确,gcd0是辗转相除法,时间复杂度为对数级;B正确,gcd1是枚举法,时间复杂度为线性级;C正确,辗转相除法效率高于枚举法;D错误,range(small, 0, -1)包含1,而1是所有整数的公约数,若修改为range(small, 1, -1)会漏掉1的判断,导致错误。
第4题 在Python中,可以用字典模拟单向或双向链表的实现。下面的代码模拟单向链表,和链表对象相比,有关其缺点的说法,错误的是( )。
A.类型安全差,易出错。比如:node1["NEXT"] = node2不会报错,导致逻辑错误
B.内存开销大。字典需要保存键名称以及哈希表
C.无法封装方法,如insert()插入函数较为常用,但其代码需要分散在外部
D.重复存储,难以保证一致性。如在node1['next'] = node2代码中,node1['next']的值为node2,而node2自身也将保存一份
答案:D
知识点:用字典模拟单向链表的缺点(类型安全、内存开销、方法封装),以及引用与复制的区别(字典中存储的是引用而非重复数据)。
解析:A正确,字典键名大小写错误不会报错,导致逻辑问题;B正确,字典比自定义对象内存开销大;C正确,字典无法像类一样封装方法;D错误,node1['next']存储的是node2的引用,而非复制,不存在重复存储问题。
第5题 基于上题代码,模拟单向链表实现插入新节点函数insertNode()的代码如下,横线处应填入的代码是( )。
A. 
B. 
C.
D. 答案:A
答案:A
知识点:单向链表的节点插入逻辑(新节点next 指向原节点next,原节点next 指向新节点)。
解析:插入节点时,新节点的next应指向原节点的next,再将原节点的next指向新节点,这样才能正确插入链表中间。选项A符合单向链表插入逻辑,选项B会丢失原节点后续的链表节点。
第 6 题 下面的Python代码用于实现双向链表。is_empty()函数用于判断链表是否为空,如为空返回True,否则False。横线处不能填入的代码是( )。
A. self.tail is None
B. self._size == 0
C. self == None
D. self.head is None
答案:C知识点:双向链表的空链表判断条件,链表对象与节点指针的区别
解析:链表为空时,head和tail均为None,_size为0,故 A、B、D均正确。self == None判断的是链表对象本身是否为空,而链表对象始终存在,该判断恒为假,因此不能填入。
第7 题 基于上题代码正确的前提下,填入相应代码完善append()函数,用于在尾部增加新节点( )。
A.
B. 
C. 
D. 
答案:D知识点:双向链表的尾部插入操作,节点指针的正确调整顺序
解析:尾部添加节点需三步:新节点prev指向原尾节点、原尾节点next指向新节点、更新tail为新节点。A缺少后两步,B未更新tail,C顺序错误(先更新tail导致指针错误),故D 正确。
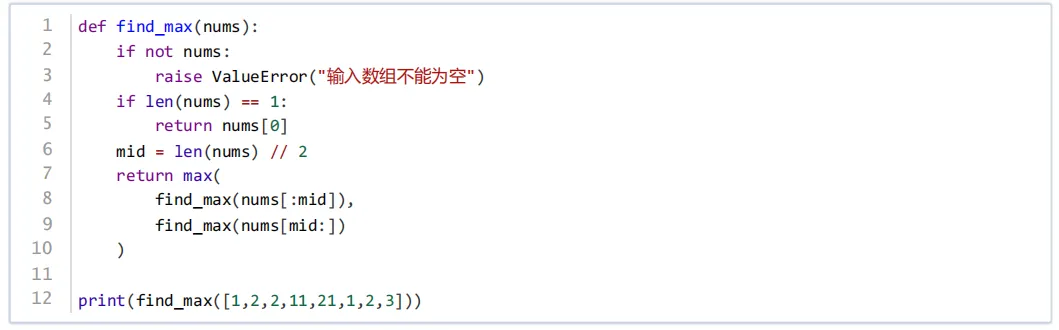
第8题 下面的Python代码用于求一系列数据中的最大值,有关其算法说法错误的是( )。
A.该算法采用分治算法
B.该算法是递归实现
C.该算法采用贪心算法
D.该算法不是递推算法
答案:C
知识点:分治算法的特征,递归与分治的关系,贪心算法、递推算法的区别。
解析:该算法将数组分成两半,分别求最大值后取较大者,属于分治算法(A正确);通过递归调用自身实现(B正确);贪心算法是做出局部最优选择,与该算法逻辑不符(C错误);递推是迭代实现,该算法是递归,故不是递推算法(D正确)。
第9题 基于上题的find_max()实现,下面的说法错误的是( )。
A. find_max()适用于str
B. find_max()适用于list
C. find_max()适用于tuple
D. find_max()适用于dict
答案:D
知识点:不同数据类型(str、list、tuple、dict)的索引访问特性(dict不支持索引访问)。
解析:str、list、tuple均支持通过索引访问元素且可迭代,而dict在该函数中无法通过索引访问(nums[left]会报错),故find_max()不适用于dict。
第10题 下面的Python代码,用于求一系列数据中的最大值。有关其算法说法错误的是( )。
A.算法采用分治思想
B.递归过程中会产生新的列表
C.时间复杂度为O(n log n)
D.空间复杂度为O(1)
答案:D
知识点:分治算法在求最大值中的应用,递归过程中列表切片的影响(产生新列表),时间复杂度与空间复杂度分析。
解析:A正确,算法分治思想明显;B正确,切片操作nums[:mid]会产生新列表;C正确,每次递归处理一半数据,时间复杂度为O(n log n);D错误,递归调用栈和切片产生的新列表会占用O(n log n)空间,空间复杂度不是O(1)。
第11题 下面的Python代码,用于求一系列数据中的最大值。有关其算法说法错误的是( )。
A.本题find_max()函数的实现是递推(迭代)算法
B.本题find_max()函数的时间复杂度为O(n)
C.和前面题的find_max()相比,因为没有递归,所以也就没有栈的创建和销毁开销,因此不会有与递归相关的栈溢出错误
D.本题的find_max()函数支持dict类型,因为dict也支持for-in循环。
答案:D
知识点:迭代算法的特征,时间复杂度计算(O (n)),递归与迭代的区别(栈开销、栈溢出风险),字典在for-in 循环中的遍历对象(键而非值)。
解析:。选项A 该函数使用for循环遍历列表元素,通过迭代更新最大值,属于递推(迭代)算法。选项B函数需要遍历列表中所有n个元素,每次循环的操作(比较和更新最大值)都是常数时间O(1),因此总时间复杂度为O(n),B说法正确。选项 C递归实现的find_max会因函数调用产生栈开销,且递归深度过深可能导致栈溢出;而该函数采用迭代(循环)实现,无递归调用,因此没有栈的创建/ 销毁开销,也不会有递归相关的栈溢出问题,C说法正确。选项 D Python的dict在for-in循环中遍历的是键(key),而非值(value)。若传入dict类型,函数会将键作为比较对象,而非字典中的值,导致逻辑错误。例如,find_max({1: 10, 2: 20})会比较键1和2,返回2,而非预期的最大值20。因此该函数不支持dict类型,D说法错误。
第12题 下面的代码用于列出求1到N之间的所有质数,错误的说法是( )。
A.埃氏筛算法相对于上面的代码效率更高
B.线性筛算法相对于上面的代码效率更高
C.上面的代码,有很多重复计算,因为不是判断单个数是否为质数,故而导致筛选出连续数中质数的效率不高
D.相对而言,埃氏筛算法比上面代码以及线性筛算法效率都高
答案:D
知识点:质数筛选算法(逐个判断、埃氏筛、线性筛)的效率对比,线性筛效率高于埃氏筛。
解析:A、B正确,埃氏筛和线性筛均通过标记法减少重复计算,效率高于逐个判断;C正确,该代码对每个数单独判断,存在重复计算;D错误,线性筛算法时间复杂度为O(n),效率高于埃氏筛的O(n log log n),故D说法错误。
第13题 硬币找零,要求找给客户最少的硬币。第一行输入硬币规格且空格间隔,单位为角,规格假设都小于10角,且一定有1角规格。硬币规格不一定是标准的货币系统,可能出现4角、2角等规格。第二行输入找零金额,约定必须为1角的整数倍。输出为每种规格及其数量,按规格从大到小输出,如果某种规格不必要,则输出为0。下面是其实现代码,相关说法正确的是( )。
A.上述代码采用贪心算法实现
B.上述代码总能找到本题目要求的最优解
C.上述代码采用枚举算法实现
D.上述代码采用分治算法
答案:A
知识点:贪心算法的特征(优先选择最大面额硬币),贪心算法在非标准货币系统中可能无法得到最优解。
解析:该代码总是优先使用最大面额硬币,符合贪心算法思想(A正确);对于非标准货币系统(如硬币为[4,3,1],金额为6),贪心算法可能无法得到最优解(B错误);代码未使用枚举或分治思想(C、D错误)。
第14题 下面Python代码用于在升序lst(list类型)中查找目标值target最后一次出现的位置。相关说法,正确的是( )。
A.当lst中存在重复的target时,该函数总能返回最后一个target的位置,即便lst全由相同元素组成
B.当target小于lst中所有元素时,该函数会返回0
C.循环条件改为while low <= high程序执行效果相同,且能提高准确性
D.将代码中(low + high + 1) // 2修改为(low + high) // 2效果相同
答案:A
知识点:二分查找的变种(查找目标值最后一次出现的位置),向上取整在二分查找中的作用,循环条件对结果的影响。
解析:A正确,代码通过向上取整的二分查找,能准确定位最后一个target的位置;B错误,target小于所有元素时,最终low=0,但lst[0]≠target,返回None;C错误,循环条件修改后会导致死循环;D错误,修改为向下取整会导致无法定位最后一个目标位置。
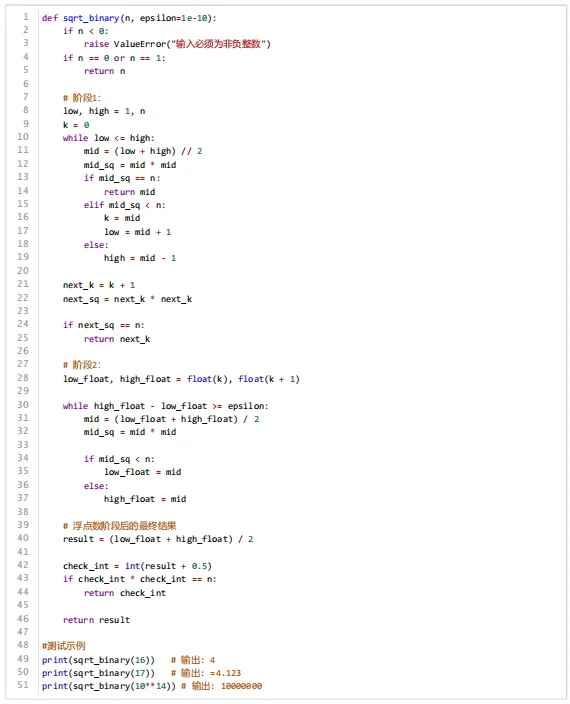
第15题 有关下面Python代码的说法,错误的是( )。
A. “阶段1”的目标是寻找正整数n可能的正完全平方根
B. “阶段2”的目标是如果正整数n没有正完全平方根,则在可能产生完全平方根附近寻找带小数点的平方根
C.代码check_int = (long long)(result + 0.5)是检查因浮点误差是否为正完全平方根
D.阶段2的二分法中high_d - low_d >= epsilon 不能用于浮点数比较,会进入死循环
答案:D
知识点:二分法在求平方根中的应用(整数阶段查找完全平方根,浮点阶段求近似值),浮点数比较在二分法中的可行性。
解析:A正确,阶段1通过整数二分查找完全平方数;B正确,阶段2在整数区间内用浮点二分求近似值;C正确,+0.5是四舍五入,用于处理浮点误差;D错误,浮点数比较high_float - low_float >= epsilon是可行的(当精度满足时退出),不会死循环。
二、判断题(每题2分,共20分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
答案 | √ | √ | × | × | × | √ | × | × | √ | √ |
第1题 下面Python代码是用欧几里得算法(辗转相除法)求两个大于0的正整数的最大公约数,a大于b还是小于b都适用。( )
答案:√
知识点:欧几里得算法(辗转相除法)的特性(无需考虑两数大小关系)。
解析:辗转相除法中,若a < b,第一次循环会将a和b交换(a = b, b = a % b,此时a % b = a),因此无论a和b的大小关系如何,代码都能正确计算最大公约数。
第2题 假设函数gcd()函数能正确求两个正整数的最大公约数,则下面的lcm()函数能求相应两数的最小公倍数。( )
答案:√
知识点:最小公倍数与最大公约数的数学关系(lcm (a,b) = a*b //gcd (a,b))。
解析:数学上,两数的最小公倍数等于两数乘积除以最大公约数(lcm (a,b) = a*b //gcd (a,b)),因此在gcd正确的前提下,该函数正确。
第3题 在下面的Python代码中,for-in每次循环都将执行n ** 0.5,并取整后加上1。( )
答案:×
知识点:range函数参数的计算时机(循环开始前计算一次,而非每次循环)。
解析:range的结束参数在循环开始前计算一次,而非每次循环都计算。因此int(n**0.5) + 1只执行一次,并非每次循环都执行。
第4题 下面的Python代码用于输出每个数对应的质因数列表,输出形如:{5: [5], 6: [2, 3], 7: [7], 8: [2, 2, 2]}。( )
答案:×
知识点:列表操作错误(列表与整数直接相加),质因数列表的正确构建方法(append ())。
解析:代码中prime_factor[i] = prime_factor.get(i,[]) + j是错误的,列表不能与整数直接相加,正确写法应为prime_factor[i].append(j)(需先初始化列表)。因此代码无法正确输出质因数列表。
第5题 下面Python代码执行后输出是15。( )
答案:×
知识点:递归函数的执行过程与结果计算。
解析:函数递归过程为:
func(5) → 4 + func(4)
func(4) → 3 + func(3)
func(3) → 2 + func(2)
func(2) → 1 + func(1)
func(1) → 0 + func(0)
func(0) → 0总和为4+3+2+1+0=10,故输出为10,而非15。
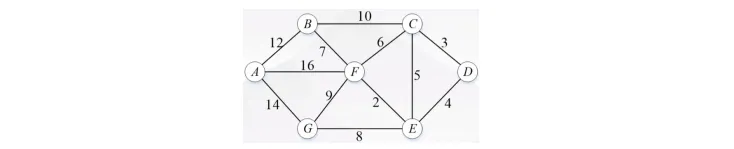
第6题 求解下图中A点到D点最短路径,其中A到B之间的12可以理解为距离。求解这样的问题,常用Dijkstra算法,其思路是通过逐步选择当前距离起点最近的节点来求解非负权重图(如距离不能为负值)单源最短路径的算法。从该算法的描述可以看出,Dijkstra算法是贪心算法。( )
答案:√
知识点:Dijkstra算法的本质(贪心算法,通过局部最优选择求解单源最短路径)。
解析:Dijkstra算法每次选择当前距离起点最近的节点加入已访问集合,并更新相邻节点的距离,符合贪心算法“局部最优选择”的特点,因此是贪心算法。
第7题 下面的Python代码用于归并排序(merge sort),已测试执行正确。假如整体交换merge()和merge_sort()两个函数的先后位置,则程序执行将触发异常。( )
答案:×
知识点:Python函数定义顺序对调用的影响(调用时函数已定义即可,与定义顺序无关)。
解析:Python函数定义顺序不影响调用,只要调用时函数已定义即可。merge_sort()在内部调用merge(),交换两个函数的定义顺序后,merge_sort()定义时merge()尚未定义,但merge_sort()实际调用merge()是在函数执行时,此时merge()已定义,因此程序可正常执行,不会触发异常。
第8题 基于上一题的Python代码。上题代码在执行时,将输出一次HERE字符串,因为merge_sort()递归调用在print("HERE")之前,因此merge()函数仅被调用一次。( )
答案:×
知识点:归并排序的递归过程与merge () 函数的调用次数(与数组长度相关,非一次)。
解析:归并排序的递归过程会将数组不断二分,直到子数组长度为1,然后逐步合并。对于长度为7的数组,merge()函数的调用次数为6次(每次合并两个子数组),因此print("HERE")会执行6次,而非1次。
第9题 基于上上题的Python代码。代码片段left_arr = merge_sort(arr[:mid])和right_arr = merge_sort(arr[mid:])因为切片,将产生的新的list,对于大容量list的排序,将需要大量额外存储空间,可以优化为就地(implace)排序。( )
答案:√
知识点:归并排序中列表切片的内存开销,就地排序的优化意义。
解析:Python的列表切片会创建新列表,归并排序过程中会产生多个中间列表,占用额外存储空间。通过设计就地排序的归并算法(如使用索引操作原列表),可以减少内存开销,因此该说法正确。
第10题 下面的Python代码实现如果对一维list【形如:[32,12,32,13,42,1],而不是[(1,3),(3,1),(321,321),(32,13)]】进行快速排序,该排序是稳定排序。( )
答案:√
知识点:稳定排序的定义(相等元素相对顺序不变),快速排序变种的稳定性判断。
解析:稳定排序是指相等元素的相对顺序在排序后保持不变。该代码中,相等元素被放入middle列表,其相对顺序与原数组一致,因此对于一维列表的排序是稳定的。
三、编程题(每题25分,共50分)
编程题1奖品兑换
题目描述:
班主任给上课专心听讲、认真完成作业的同学们分别发放了若干张课堂优秀券和作业优秀券。同学们可以使用这两种券找班主任兑换奖品。具体来说,可以使用a张课堂优秀券和b张作业优秀券兑换一份奖品,或者使用b张课堂优秀券和a张作业优秀券兑换一份奖品。
现在小A有n张课堂优秀券和m张作业优秀券,他最多能兑换多少份奖品呢?输入格式:
第一行,两个正整数n,m,分别表示小A持有的课堂优秀券和作业优秀券的数量。
第二行,两个正整数a,b,表示兑换一份奖品所需的两种券的数量。
输出格式:
输出共一行,一个整数,表示最多能兑换的奖品份数。
输入样例1:

输出样例1:
输入样例2:
输出样例2:
数据范围:
对于60% 的测试点,保证1≤a,b≤100,1≤n,m≤500。
对于所有测试点,保证1≤a,b≤104,1≤n,m≤109。
【解析】
1.问题分析:兑换奖品有两种方式:(a张课堂券+ b张作业券)或(b张课堂券+ a张作业券)。需找到最大份数v,使得总消耗不超过小A持有的n 张课堂券和m 张作业券。
2.核心思路:
由于两种兑换方式可灵活选择,可通过二分查找确定最大可行份数v。
对每个候选v,验证是否存在合理的两种兑换方式组合(设t 份用第二种方式,v-t份用第一种方式),使得总消耗满足:a*(v-t) + b*t ≤n(课堂券)b*(v-t) + a*t ≤m(作业券)
简化验证逻辑:通过调整t 使消耗尽可能匹配持有量,最终判断是否存在有效t。
3.算法步骤:
预处理:交换n 与m、a与b,确保n ≤m 且a ≤b,减少分支判断。
二分查找:范围[0, 1e9],对中点mid 调用check 函数验证可行性。
check函数:计算理论消耗,调整t 使作业券消耗不超m,再检查课堂券是否足够。
4.时间复杂度:
二分查找迭代次数约30 次,每次check 函数为O(1),总复杂度O(log(1e9)),适用于所有数据范围。
知识点:二分查找的应用(最大化可行解),灵活调整变量组合验证约束条件,边界情况处理
参考程序
编程题2:最大公因数
题目描述:
对于两个正整数a,b,它们的最大公因数记为gcd(a,b)。对于k≥3个正整数c1,c2,…,ck,它们的最大公因数为:
gcd(c1,c2,…,ck)= gcd(gcd(c1,c2,…,ck-1),ck)
给定n个正整数a1,a2,…,an以及q组询问。对于第i(1≤i≤q)组询问,请求岀a1+i,a2+i,...,an+i的最大公因数,也即gcd(a1+i,a2+i,...,an+i)。
输入格式:
第一行,两个正整数n,q,分别表示给定正整数的数量,以及询问组数。
第二行,几个正整数a1,a2,...an。
输出格式:
输出共q行,第i行包含一个正整数,表示a1+i,a2+i,...,an+i的最大公因数。
输入样例1:
输出样例1:
输入样例2:
输出样例2:
数据范围:1 ≤ n,q ≤ 105,1 ≤ ai≤ 1000
对于60%的测试点,保证1≤n≤ 103,1≤q≤ 10。
对于所有测试点,保证1≤n≤ 105,1≤q≤105,1 ≤ ai≤ 1000。
【解析】
1.核心思路:对于一组数a1+i,a2+i,...,an+i,它们的最大公因数(gcd)可通过以下推导简化计算:
设d是该组数据的gcd,则d能整除任意两个数的差,即d|(aj+i)-(ak+i)=aj-ak(j≠k)。
因此,d必须是所有aj-ak的gcd的约数。进一步,所有差的gcd与a1+i的gcd即为结果。
2.算法步骤:
先对数组a排序,计算相邻元素的差,再求这些差的gcd(记为g)。
对于第i组询问(i从1到q),结果为gcd(g,a0+i)(a0是排序后数组的第一个元素)。
3.时间复杂度:
排序数组:O(nlogn)。
计算相邻差的gcd:O(n)。
处理q组询问:O(qlogmax(a))(每次gcd计算为对数级)。整体复杂度为O(nlogn+qlogmax(a)),适用于n,q≤105的数据范围。
知识点:最大公因数的性质(gcd对差的整除性),欧几里得算法的应用,多组询问的批量处理优化
参考程序


































 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
