2025年09月
一、单选题(每题2分,共30分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
答案 | B | C | A | B | B | D | A | B | B | C | D | D | B | C | A |
1、以下哪种情况使用链表比数组更合适?
A.数据量固定且读多写少
B.需要频繁在中间或开头插入、删除元素
C.需要高效随机访问元素
D.存储空间必须连续
【答案】B
【考纲知识点】链表vs数组知识点
【解析】数组:适合读多写少、随机访问频繁、数据量固定的场景
链表:适合频繁插入删除、数据量变化大的场景。
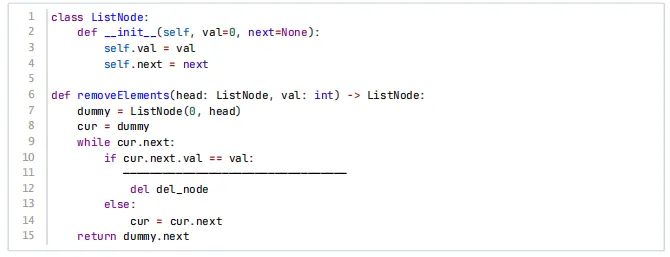
2、下面的python代码实现给定单链表头结点head和一个整数val,删除链表中所有结点值等于val的节点,并返回新的头结点,则横线处填写( )。
A.
B.
C.
D.
【答案】C
【考纲知识点】链表知识点
【解析】代码逻辑
1、使用虚拟头节点dummy,这样即使要删除的节点是原head也可以统一处理。
2、cur从dummy开始,检查cur.next是否等于val。
3、如果等于,则删除cur.next,但不移动cur(因为新的cur.next可能还要删除)。
4、如果不等于,cur才移动到cur.next。
删除操作步骤
1、用del_node记录cur.next(要删除的节点)
2、将cur.next指向del_node.next(跳过该节点)
3、删除del_node(Python中del只是减少引用,可选)
所以:
A.语法错误
B.cur不应该移动,否则会跳过检查新节点
C.标准删除操作
D.这会让cur.next指向要删除的节点,没有删除效果
3、下列python代码用Floyd判断一个单链表中是否存在环 ,链表的头节点为 head,即用两个指针在链表上前进:slow 每次走1步,fast 每次走2步,若存在环,fast 终会追上slow(相遇);若无环,fast 会先到达nullptr。横线上应填写( )。
A.
B.
C.
D.
【答案】A
【考纲知识点】Floyd链表
【解析】移动指针的正确方式
slow移动1步:slow = slow.next
fast移动2步:fast = fast.next.next
A.符合算法要求。
B.slow.next = slow 会破坏链表结构,不是移动指针,而是让slow指向自己。
C.fast.next = fast.next.next 会修改链表结构,不是移动fast指针。
D.fast只移动1步,这样slow 和fast速度相同,无法在环中相遇(除非一开始就相遇)。
4、下列代码用于判断一个数是否为完全数(即等于它的真因子之和的数 ,如6= 1+2+3) ,哪个选项是正确的实现?
A. if i != n / i :
B. if i != n // i :
C. if i = n // i :
D. if i == n // i :
【答案】B
【考纲知识点】语法知识点
【解析】原代码问题
当前代码在找到因子i时,会同时加上i和n // i,但如果i == n // i(即i * i == n),那么i和n // i 是同一个因子,就会重复加两次。
例如:n=4,因子2会被加两次(2和4//2=2),导致结果错误。
因此需要判断i != n // i 才加第二个因子。
A.在 Python中,n / i 返回浮点数,比较可能因浮点精度问题出错,不推荐。
B.整数除法,精确比较,避免重复加同一个因子。
C.语法错误,这是赋值不是比较。
D.这是判断是否相等,但我们想要的是不相等时才加第二个因子。
5、以下代码计算两个数的最大公约数(GCD),横线上应填写( )。
A.b
B.a
C.temp
D.a+b
【答案】B
【考纲知识点】辗转相除法
【解析】代码步骤
如果a < b,交换a和b,确保a >= b。
使用辗转相除法(欧几里得算法):
temp = a % b
a = b
b = temp
循环直到b == 0。
当b == 0 时,a就是最大公约数。
A.此时b=0,错误
B.正确
C.temp → 最后一次temp=0,错误
D.a+b → 等于a,但逻辑上不直接
6、下面的代码实现埃拉托斯特尼筛法(埃氏筛),横线处应填入( )。
A.i
B.i+1
C.i*2
D.i*i
【答案】D
【考纲知识点】素数筛法
【解析】埃氏筛逻辑
1、从2开始,如果is_prime[i]是True,则i是素数。
2、把i的所有倍数标记为合数(False)。
3、优化:标记倍数时,可以从i*i开始,因为i*2, i*3, ..., i*(i-1) 已经被更小的素数标记过了。
所以选D,最优效率
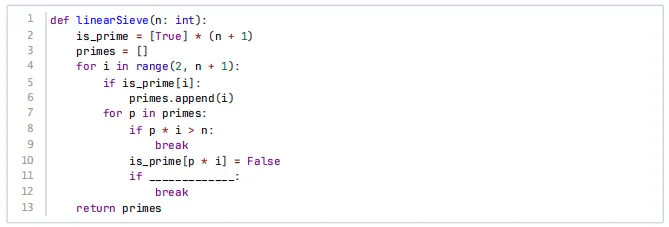
7、下面的代码实现线性筛法(欧拉筛),横线处应填入( )。
A. i % p == 0
B. p % i == 0
C. i == p
D. i * p == n
【答案】A
【考纲知识点】素数筛法
【解析】线性筛的关键
每个合数只被它的最小质因子筛掉一次。
当i % p == 0 时,说明p是i的最小质因子,那么对于更大的质数p',i * p' 的最小质因子应该是p而不是p',所以应该停止继续用更大的质数去筛,避免重复。
所以选A,保证每个合数只被最小质因子筛一次
B.p是质数且p≤i,这只会发生在p==i时,不合理
C.这样会过早break,漏筛一些数
D.与n无关
8、线性筛算法中有语句if p * i > n break; ,其目的是( )。
A.降低常数但复杂度仍是O(nlogn)
B.保证每个合数只被其最小质因子筛到一次 ,从而O(n)
C.提高缓存命中率,复杂度仍O(nloglogn)
D.不重要,是否break 都一样
【答案】B
【考纲知识点】素数筛法
【解析】作用
这个判断主要是提前终止内层循环,减少不必要的计算,但它不改变算法的线性复杂度O(n),因为每个合数仍然只被标记一次,只是提前剪枝。
它主要降低常数因子,但复杂度类不变。
A.错误,线性筛复杂度是O(n),不是O(n log n)
B.正确
C.复杂度错(线性筛是 O(n)),且缓存命中率不是主要目的
D.不加这个break会做很多超出n的计算,效率低
9、唯一分解定理描述的是( )。
A.每个整数都能表⽰为任意素数的乘积
B.每个大于1的整数能唯一分解为素数幂乘积(忽略顺序)
C.合数不能分解为素数乘积
D.素数只有两个因子:1和自身
【答案】B
【考纲知识点】算术基本定理
【解析】唯一分解定理(算术基本定理)的内容是:
每个大于1的整数,都可以唯一地写成素数的乘积(素数按从小到大排列时,写法唯一)。
A.错误,“任意素数”不对,必须是特定的素数,且负整数和0、1不适用。
B.正确
C.错误,合数正需要分解为素数乘积。
D.这是素数的定义,不是唯一分解定理。
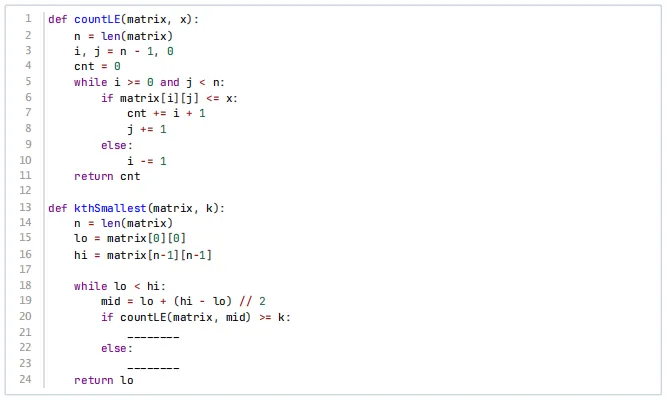
10、给定一个n x n 的矩阵matrix ,矩阵的每一行和每一列都按升序排列 。下面代码返回矩阵中第k小的元素,则两处横线上应分别填写( )。
A.
B.
C.
D.
【答案】C
【考纲知识点】二分查找知识点
【解析】二分查找逻辑
lo和hi是矩阵最小值和最大值
mid是猜测值
如果countLE(matrix, mid) >= k,说明第k小的元素≤mid,所以答案在[lo, mid] 中
如果countLE(matrix, mid) < k,说明第k小的元素> mid,所以答案在[mid+1, hi] 中
边界更新规则
当countLE(matrix, mid) >= k 时,hi = mid(保留mid作为候选)
当countLE(matrix, mid) < k 时,lo = mid + 1(mid不可能是答案)
这样循环结束时lo就是第k小的元素。
A.错误,可能跳过正确答案
B.错误,可能死循环
C.正确
D.错误,范围更新不对
11、下述python代码实现了快速排序算法,下面说法错误的是( )。
A. 快速排序平均情况下比归并排序的比较、赋值、交换等操作的总数量少 ,所以命名为“快速”。
B. 在平均情况下 ,划分的递归层数为logn,每层中的总循环数为n,总时间为O(nlogn)。
C. 在最差情况下 ,每轮划分操作都将长度为n的数组划分为长度为0和n 1 的两个子数组 ,此时递归层数达到n,每层中的循环数为n,总时间为o (n2) 。
D. 划分函数中“从右往左查找”与“从左往右查找” 的顺序可以互换。
【答案】D
【考纲知识点】快速排序
【解析】A、说“快速排序平均情况下比归并排序的比较、赋值、交换等操作的总数量少,所以命名为‘快速’”
1、命名“快速”是因为平均情况下它比当时其他O(n²)排序(如冒泡、插入)快很多,而不是专门和归并排序比较。
2、实际上归并排序的比较次数在平均和最坏情况下都是O(n log n),快排平均也是O(n log n),但常数因子通常比归并小,不过归并稳定且最坏O(n log n)。
3、严格说这个说法不准确,因为命名原因并非是和归并比较。
B、平均情况下,递归层数log n,每层O(n),总时间O(n log n)
→ 正确
C、最差情况(如数组已排序),划分成0和n-1,递归深度n,每层O(n),总时间O(n²)
→ 正确(虽然它写的小写o(n²)不太规范,但意思对)
D、划分函数中“从右往左查找”与“从左往右查找”的顺序可以互换
1、如果互换,需要调整判断条件,否则可能出错。但理论上顺序可以调整,只要逻辑正确。
2、不过原代码里先右后左是为了最后交换时arr[i]是小于基准的值,如果先左后右,最后交换的可能是大于基准的值,会出错。
3、所以不能简单互换顺序而不改逻辑,因此这个说法错误。
错误选项
A和D都有问题,但A是历史/命名原因描述不准确,D是算法逻辑上错误(直接互换顺序会错)。
通常这类题选算法逻辑错误的,所以选D。
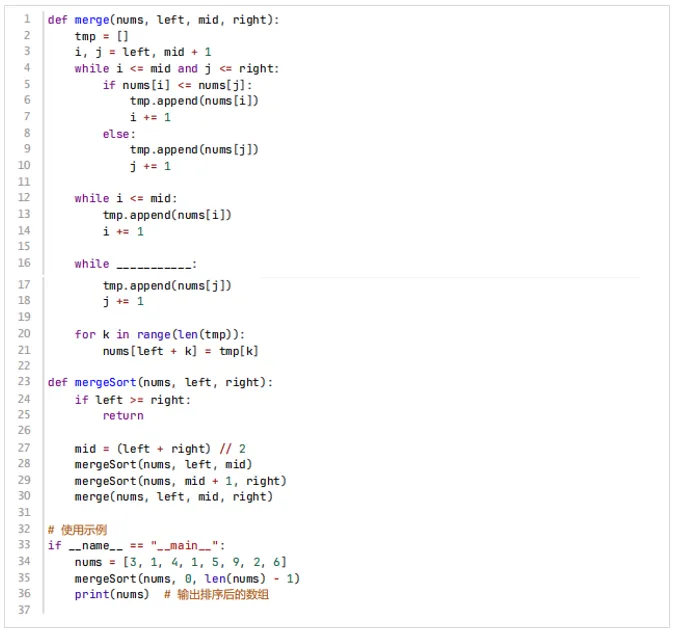
12、下述python代码实现了归并排序算法,则横线上应填写( )。
A. i < mid
B. j < right
C. i <= mid
D. j <= right
【答案】D
【考纲知识点】归并排序
【解析】已知
第一个循环:合并两个有序段[left, mid] 和[mid+1, right],直到其中一个用完
第二个循环:如果左半部分还有剩余,全部加入tmp
第三个循环:如果右半部分还有剩余,全部加入tmp
第三个循环的条件
在第一个循环结束后,如果j <= right,说明右半部分还有元素没加入,应该继续加入。
所以第三个循环的条件是j <= right。选D
13、假设你是一家电影院的排片经理,只有一个放映厅。你有一个电影列表 movies,其中movies[i ] = [start_i , end_i ] 表⽰第i部电影的开始和结束时间。请你找出最多能安排多少部不重叠的电影,则横线上应分别填写的代码为( )。
A.movies
B. lastEnd
C. movies[i][0]
D. movies[i][1]
【答案】B
【考纲知识点】贪心算法
【解析】代码逻辑
1、按结束时间排序
2、初始化count = 1(第一部电影)
3、记录上一部电影的结束时间lastEnd
4、遍历后续电影,如果当前电影的开始时间>= lastEnd,则选择它,并更新lastEnd为它的结束时间
横线处
显然需要初始化lastEnd为第一部电影的结束时间movies[0][1]。所以选B。
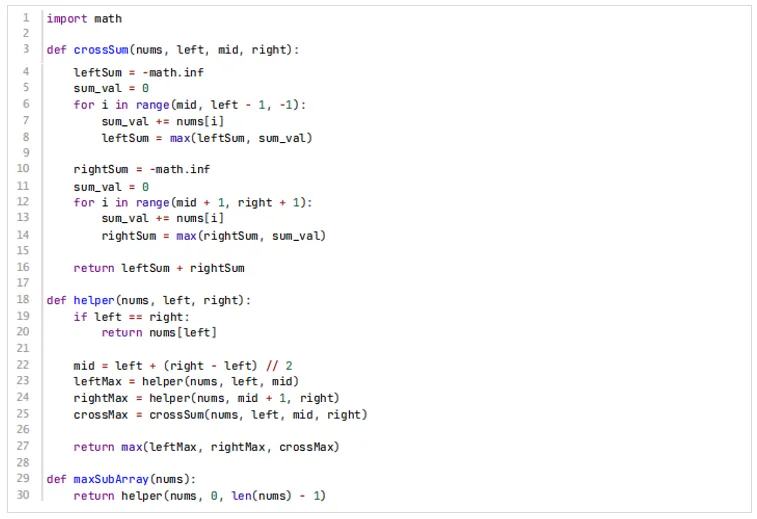
14、给定一个整数数组 nums,下面代码找到一个具有最大和的连续子数组,并返回其最大和。则下面说法错误的是( )。
A.上述代码采用分治算法实现
B.本题算法采用贪心算法
C.时间复杂度:O( log n)
D.由于采用递归方式实现,空间复杂度:O(log n)
【答案】B
【考纲知识点】分治
【解析】分治思想用到递归,执行过程就是每次将问题分解为两个子问题(规模减半)并执行O(n)的合并操作,递归深度为log n,总时间复杂度为O(n log n),这个代码未使用贪心思想
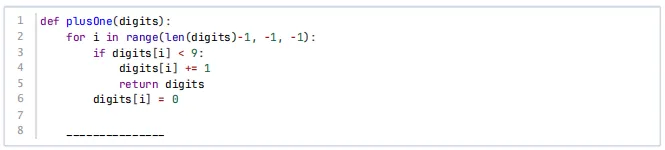
15、给定一个由非负整数组成的数组digits,表⽰一个非负整数的各位数字(最高位在数组首位)。下面代码对该整数执行+1操作,并返回结果数组,则横线上应填写( )。
A.
B.
C.
D.
【答案】A
【考纲知识点】高精度运算技巧
【解析】代码逻辑
1、从最后一位开始向前遍历
2、如果某一位< 9,则加1并直接返回(没有进位了)
3、如果某一位== 9,则这一位置0,继续向前进位
4、如果循环结束还没有返回,说明所有位都是9(例如999),需要增加一位,变成1000
循环结束后
此时digits已经全部是0(因为每一位9都置0了),需要在最前面插入1,然后返回。
A.正确
B.插入位置和值不对
C.函数不会返回
D.插入位置不对
二、判断题(每题2分,共20分)
题号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
答案 | √ | × | × | √ | √ | √ | × | × | √ | × |
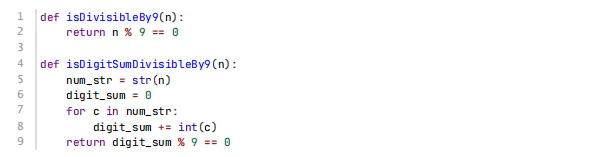
1、基于下面定义的函数,通过判断 isDivisibleBy9(n ) == isDigitSumDivisibleBy9(n ) 代码可验算如果一个数能被9整除 ,则它的各位数字之和能被9整除。
【答案】正确
【考纲知识点】数学知识
【解析】代码验证
1、isDivisibleBy9(n)直接检查n%9==0
2、isDigitSumDivisibleBy9(n)计算各位和并检查和的模9
3、根据上述数学原理,这两个函数的返回值总是相同结论
该判断语句isDivisibleBy9(n) == isDigitSumDivisibleBy9(n) 对所有非负整数n都会返回True。
2、假设函数gcd()函数能正确求两个正整数的最大公约数,则下面的findMusicalPattern(4,6)函数返回2。
【答案】错误
【考纲知识点】最大公约数
【解析】两个数的最小公倍数等于两个数的乘积除以两个数的最小公约数。
3、下面递归实现的斐波那契数列的时间复杂度为O(2n)。
【答案】错误
【考纲知识点】递归
【解析】本题代码是通过记忆化搜索实现斐波那契数列,不是朴素递归。朴素递归的时间复杂度是O( 2n),本题通过memo数组存储已经计算过的结果,不会重复计算,时间复杂度是O(n)
4、链表通过更改指针实现高效的节点插入与删除 ,但节点访问效率低、 占用内存较多 ,且对缓存利用不友好。( )
【答案】正确
【考纲知识点】链表
【解析】链表的插入删除效率高O(1),访问效率低O(n)。占用的内存较多,除了数据域,还要存储指针。结点内存不连续,对缓存利用不友好。
5、二分查找依赖数据的有序性 ,通过循环逐步缩减一半搜索区间来进行查找 ,且仅适用于数组或基于数组实现的数据结构。 ( )
【答案】正确
【考纲知识点】二分算法
【解析】二分查找需要待查找数据是有序的,且可以随机访问。
6、线性筛关键是“每个合数只会被最小质因子筛到一次”,因此为O(n)。( )
【答案】正确
【考纲知识点】素数筛法知识
【解析】线性筛(欧拉筛)原理
1、每个合数m只会被它的 最小质因子 筛掉
2、在代码中,当i % p == 0 时立即break,确保这一点
3、因此每个合数只被标记一次,时间复杂度O(n)
7、快速排序和归并排序都是稳定的排序算法。( )
【答案】错误
【考纲知识点】排序知识
【解析】快排不稳定。
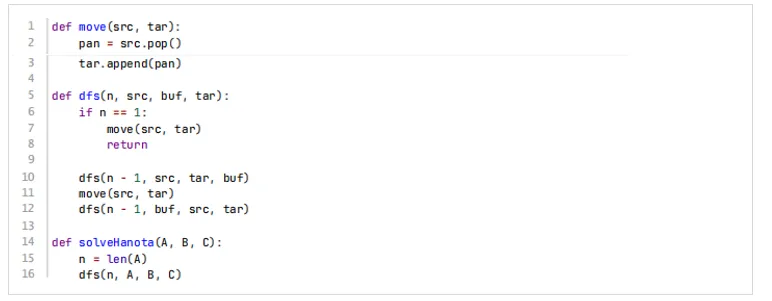
8、下面代码采用分治算法求解汉诺塔问题,时间复杂度为O(nlogn)。
【答案】错误
【考纲知识点】递归
【解析】汉诺塔的递归关系为T(n) = 2T(n-1) + 1, 时间复杂度为O(2n)
9、所有递归算法都可以转换为迭代算法。
【答案】正确
【考纲知识点】递归
【解析】递归和迭代在计算能力上是等价的,任何递归算法都可以通过使用显式的栈或队列来模拟递归调用过程,从而转换为迭代算法。
10、贪心算法总能得到全局最优解。 ( )
【答案】错误
【考纲知识点】算法知识
【解析】贪心算法不一定能得到全局最优解,只有在特定问题结构下才可以。
如:适用条件
贪心算法能获得全局最优解,必须满足以下条件之一:
1、贪心选择性质:局部最优选择能导致全局最优解
2、最优子结构:问题的最优解包含子问题的最优解
反例
1、硬币找零问题(硬币面额任意时):贪心(先选最大面额)不一定得到最少硬币数
例如:面额{1, 3, 4},要凑6元
贪心:4 + 1 + 1 = 3 枚
最优:3 + 3 = 2 枚
2、部分背包问题:贪心可以得到最优解
3、0-1背包问题:贪心不能保证最优解
三、编程题(每题25分,共50分)
1、数字选取
问题描述
给定正整数 n,现在有1, 2, …, n 共计n 个整数。你需要从这n个整数中选取一些整数,使得所选取的整数中任意两个不同的整数均互质(也就是说,这两个整数的最大公因数为1)。请你最大化所选取整数的数量。
例如,当 n = 9 时,可以选择1, 5, 7, 8, 9 共计5 个整数。可以验证不存在数量更多的选取整数的方案。
输入描述
一行,一个正整数n,表示给定的正整数。
输出描述
一行,一个正整数,表示所选取整数的最大数量。
样例输入 1
6
样例输出1
4
样例输入 2
9
样例输出2
5
数据规模
对于 40%的测试点,保证 1≤n≤ 1000。
对于所有测试点,保证1 ≤n ≤ 105。
【题目大意】从1到n这n个整数中,选出尽可能多的数,要求选出的数两两互质(任意两个数的最大公约数为1),求最多能选多少个。我们需要找到一个最大的子集,其中任意两个不同的整数互质。质数之间自然互质,且1与所有整数互质,因此包含所有质数和1的集合满足条件。
【考纲知识点】数论基础,贪心算法
【解题思路】任何合数都会与某个质数共享质因子,因此如果已经选择了所有质数,则无法再添加任何合数而不破坏互质条件。最大子集的大小为1加上不超过n的质数数量。
【参考程序】
2、有趣的数字和
问题描述
如果一个正整数的二进制表示包含奇数个1,那么小A 就会认为这个正整数是有趣的。
例如,7的二进制表示为(111)2,包含1 的个数为3 个,所以7 是有趣的。但是9 = (1001)2包含2 个1,所以9 不是有趣的。
给定正整数l, r,请你统计满足l ≤n ≤ r 的有趣的整数n 之和。
输入描述
一行,一个正整数,表示l, r 之间有趣的整数之和。
输出描述
一行,一个正整数,表示l, r 之间有趣的整数之和。
样例输入1
3 8
样例输出1
19
样例输入2
65 36248
样例输出2
328505490
数据规模
对于 40%的测试点,保证 1≤ l ≤r ≤104。
对于另外 30%的测试点,保证 l = 1 并且r = 2k - 1,其中k 是大于1 的正整数。
对于所有测试点,保证1 ≤l ≤ r ≤109。
提示
由于本题的数据范围较大,整数类型请使用long long。
【题目大意】定义“有趣的数”为:二进制表示中1 的个数为奇数。
给定区间[l,r],求所有“有趣的数”的和。数据范围:1≤l≤r≤109不能直接枚举。
【考纲知识点】二进制 位运算
【解题思路】在连续整数区间里,“有趣的数”是有规律的——它们差不多是每隔一个数出现一次,但并不是严格的交替,而是整体上一半的数是“有趣的”。我们可以通过找规律得出,对于区间[0,2k-1]中,“有趣的数”占一半,有2k-1个,而且它们的和等于总和的一半。本题我们要求的是[l-r]之间的“有趣的数“之和,我们可以利用前缀和的思想用[1 - r]的和减去[1 - l-1]的和
【参考程序】
策划:GESP技术委员会副主席 刘晓庆
技术支持:朱浩淼