一、为什么 select 和 poll 性能不行
在讲 epoll 之前,我们先搞清楚为什么 select 和 poll 支撑不了高并发:1. select 的三大硬伤
最大连接数限制:select 默认最大支持 1024 个文件描述符,虽然可以修改内核参数重新编译,但本质上是用数组存储 fd,连接数越大性能越差
全量拷贝:每次调用 select 都要把 fd 集合从用户态拷贝到内核态,连接数多了拷贝开销极大
全量遍历:每次有事件发生,都要遍历所有传入的 fd,才能知道哪个 fd 有事件,O (n) 的时间复杂度,连接越多越慢
2. poll 的改进与不足
poll 用链表存储 fd,去掉了 1024 的连接数限制,但全量拷贝和全量遍历这两个核心问题完全没解决,所以高并发下性能还是很差。二、epoll 的核心设计:解决了什么问题
epoll 针对 select/poll 的三个硬伤,做了三个核心改进:1. 红黑树存储 fd
epoll 在内核里用红黑树存储所有监听的 fd,增删改查都是 O (logn),没有最大连接数限制,一台普通服务器轻松支持几十万连接。2. 只拷贝一次
调用 epoll_ctl 添加 fd 的时候,就把 fd 拷贝到内核里了,不需要每次 epoll_wait 都全量拷贝,只需要拷贝有事件的 fd 即可。3. 就绪链表 + 回调机制
每个 fd 上有事件发生时,内核会自动把这个 fd 加入就绪链表,epoll_wait 只需要返回就绪链表里的 fd 就行,不需要遍历所有 fd,时间复杂度是 O (1),不管有多少连接,性能都不会下降。三、epoll 三个核心函数详解
1. epoll_create:创建 epoll 实例
size:早期内核用来告诉内核要监听多少个 fd,现在内核用红黑树,这个参数已经没用了,只要填大于 0 的数就行
返回值:epoll 实例的文件描述符,用完要 close
2. epoll_ctl:管理 fd
epfd:epoll_create 返回的 fd
op:操作类型,三个可选值:
fd:要操作的文件描述符
event:要监听的事件,常用事件:
3. epoll_wait:等待事件
events:输出参数,用来存放有事件发生的 fd
maxevents:最多返回多少个事件,不能大于 epoll_create 时的 size
timeout:超时时间,-1 表示无限等待,0 表示不阻塞立即返回
返回值:有事件发生的 fd 数量
四、epoll 两种工作模式:LT vs ET 彻底讲透
1. 水平触发(Level Trigger,LT,默认模式)
触发规则:只要 fd 上还有未处理的数据,epoll_wait 就会一直通知你,直到你把数据处理完。举个例子:客户端发了 1000 字节数据,你第一次只 read 了 500 字节,LT 模式下,下一次 epoll_wait 还会通知你这个 fd 可读,直到你把剩下的 500 字节读完。编程简单,和 select/poll 行为完全一致
不容易丢数据,就算一次没读完,下次还会通知
出 bug 概率低,大部分开源项目默认用 LT
事件通知次数多,高并发下会有一定的性能开销
2. 边缘触发(Edge Trigger,ET)
触发规则:只有 fd 的状态发生变化的那一刻才通知一次,不管数据有没有读完,之后不会再通知了。举个例子:客户端发了 1000 字节数据,epoll 通知你一次,如果你只 read 了 500 字节,剩下的 500 字节不会再通知你,数据就丢了。事件通知次数少,高并发下性能更高
减少了 epoll_wait 的调用次数,吞吐量更高
编程复杂,非常容易丢数据
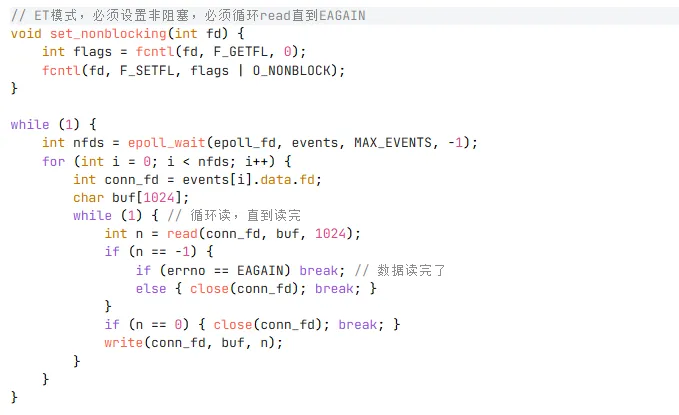
必须搭配非阻塞 IO,必须循环 read 直到 EAGAIN
3. 两种模式完整代码对比
LT 模式服务器(简单不易错)
踩坑点
ET 模式必须用非阻塞 IO:如果用阻塞 IO,read 会一直等数据,整个服务器就卡住了
ET 模式必须循环 read/write:只读一次一定会丢数据,这是 90% 的人都会犯的错
优先用 LT 模式:除非你确定要极致性能,否则 LT 模式足够用,出 bug 概率低很多
五、总结
select/poll 的硬伤:连接数限制、全量拷贝、全量遍历
epoll 的三大核心改进:红黑树、只拷贝一次、就绪链表回调
epoll 三个核心函数的参数与用法
LT 和 ET 两种模式的原理、优缺点、代码对比、踩坑点epoll 是网络编程的核心,也是后端面试的必考点,一定要亲手写代码跑一遍,理解两种模式的区别。
下一期用 epoll 实现一个完整的 HTTP 服务器。
大家有任何不懂的地方,或者敲代码遇到了 bug,都可以在评论区留言,我都会一一回复。如果这篇内容对你有帮助,别忘了点赞、在看、转发给身边同样在学 C 语言的朋友。我们下期见。