本篇梳理机器学习代码中高频出现的 Python 语法点,按 10 个类别整理。每个语法点配 ML 场景的最小可运行示例。覆盖范围限于 scikit-learn 、 PyTorch 、 Pandas 三大库使用所需的语法子集。
不涉及:装饰器、元类、协程、 async/await 、多线程、 C 扩展。这些在 ML 工作流中出现频率低。
参考来源:Python 3 官方语言参考[1]、PEP 8 风格指南[2]、PEP 484 类型注解[3]。
一、变量与基础类型
Python 变量是对象的引用(指针),不存储数据本身。对象有标识号、类型、值三个属性,标识号创建后不变(Python 数据模型文档[4])。
x = 42 # inty = 3.14 # floatname = "linear" # strflag = True # boolnothing = None # NoneTypeprint(type(x)) # <class 'int'>print(id(x)) # 内存地址整数(CPython 实现为内存指针)
基础类型:
注解:== 比较值,is 比较标识号。比较 None 必须用 is None,不能用 == None。
二、数据结构
Python 内置四类复合数据结构,区别在可变性、有序性、是否允许重复元素。
features = [1.2, 3.4, 5.6]features.append(7.8)features[0] = 0.0shape = (3, 224, 224) # 张量维度,固定不变config = {"lr": 0.001, "epochs": 50, "batch_size": 32}vocab = {"apple", "banana", "cherry"}
注解: tuple 用于不可变结构(张量 shape 、坐标), dict 用于配置参数和模型 state_dict , list 用于数据集索引, set 用于去重。
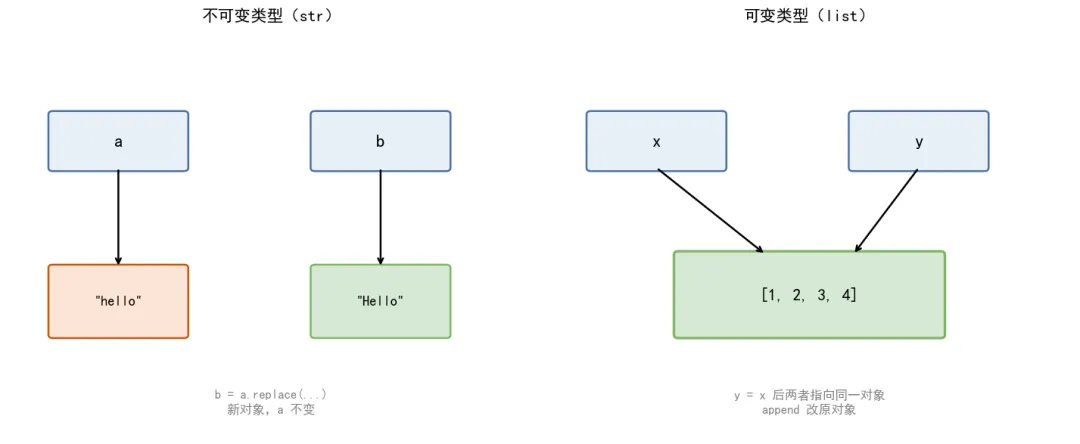
三、可变 vs 不可变
不可变类型( int 、 float 、 str 、 tuple )修改时新建对象;可变类型( list 、 dict 、 set )原地修改。
a = "hello"b = a.replace("h", "H") # a 不变,b 是新对象print(a, b) # hello Hellox = [1, 2, 3]y = xy.append(4)print(x) # [1, 2, 3, 4] x 也变了
注解:函数默认参数禁用可变对象。def f(items=[]): 的 list 在函数定义时创建一次,多次调用共享同一对象,会导致累积 bug 。正确写法:
def f(items=None): if items is None: items = [] items.append(1) return items
四、控制流
if accuracy > 0.95: print("good")elif accuracy > 0.80: print("ok")else: print("bad")for epoch in range(10): for batch in dataloader: loss = train(batch) if loss < threshold: break # 跳出内层循环 else: continue # for-else:循环正常结束才执行(不 break)while not converged: update_params()
注解: Python 没有 switch/case( 3.10 起有 match-case)。for-else 的 else 子句在循环未被 break 中断时执行,可用于搜索逻辑。
match activation: case "relu": return F.relu(x) case "gelu": return F.gelu(x) case _: raise ValueError(f"unknown activation: {activation}")
五、函数
def train(model, dataloader, epochs=10, lr=0.001): """训练循环""" for epoch in range(epochs): for batch in dataloader: loss = model.step(batch, lr) return modeldef plot(*args, **kwargs): print(args) # (1, 2, 3) print(kwargs) # {'color': 'red', 'label': 'train'}plot(1, 2, 3, color="red", label="train")square = lambda x: x ** 2print(square(5)) # 25def compute_loss(pred: torch.Tensor, target: torch.Tensor) -> torch.Tensor: return F.mse_loss(pred, target)
注解:默认参数必须用不可变对象( None 占位 + 内部初始化)。*args 在 ML 库中常见于灵活 API (plt.plot(*args, **kwargs))。
六、类
class MLP(nn.Module): def __init__(self, in_dim: int, hidden_dim: int, out_dim: int): super().__init__() self.fc1 = nn.Linear(in_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, out_dim) def forward(self, x: torch.Tensor) -> torch.Tensor: x = F.relu(self.fc1(x)) return self.fc2(x)model = MLP(784, 128, 10)print(model) # 打印网络结构
注解: PyTorch 中所有模型继承 nn.Module,必须实现 __init__(定义层)和 forward(前向传播)。super().__init__() 注册子模块。self 等价于 C++/Java 中的 this 指针。
class DropoutMLP(MLP): def __init__(self, *args, dropout=0.5, **kwargs): super().__init__(*args, **kwargs) self.dropout = nn.Dropout(dropout) def forward(self, x): x = F.relu(self.fc1(x)) x = self.dropout(x) return self.fc2(x)
七、字符串与 f-string
epoch = 10loss = 0.0234msg = f"Epoch {epoch:3d}, loss {loss:.4f}"print(msg) # Epoch 10, loss 0.0234docstring = """Compute mean squared loss.Args: pred: predicted tensor target: ground truth tensor"""acc = 0.9567print(f"{acc:.2%}") # 95.67%(百分比格式)print(f"{1000 * 1024:,}") # 1,024,000(千分位)
注解: f-string 比 % 或 .format() 快约 2 倍,可读性最高。 ML 训练日志几乎全部用 f-string 。
八、解包语法
a, b, c = 1, 2, 3first, *rest = [1, 2, 3, 4, 5] # first=1, rest=[2,3,4,5]def returns_three(): return 1, "two", 3.0num, word, flt = returns_three()config = {"lr": 0.001, "epochs": 10}train(**config) # 等价于 train(lr=0.001, epochs=10)for x, y in zip(train_x, train_y): passfor i, (x, y) in enumerate(zip(train_x, train_y)): if i % 100 == 0: print(f"step {i}")
注解:*rest 收集剩余元素为 list ,**dict 展开字典为关键字参数。 PyTorch DataLoader 输出 (inputs, targets) 二元组,循环里常用 for inputs, targets in loader:。
九、上下文管理器
withopen("data.csv", "r") as f: lines = f.readlines()with torch.no_grad(): pred = model(x_test)with torch.cuda.device(0): a = torch.randn(1000, 1000, device="cuda")
注解:with 调用对象的 __enter__ 和 __exit__ 方法。torch.no_grad() 关闭梯度计算,推理时减少内存占用约 60%。torch.cuda.device(n) 指定 GPU 编号。
十、生成器与迭代器
def data_stream(path: str, batch_size: int = 32): with open(path) as f: batch = [] for line in f: batch.append(process(line)) if len(batch) == batch_size: yield batch # 暂停并返回 batch = [] if batch: yield batchtotal = sum(x ** 2 for x in range(1000000))
注解:生成器用 yield 暂停函数并返回值,下次调用从暂停处继续。处理大数据集( GB 级)时避免一次性加载, PyTorch DataLoader 内部基于生成器协议。
十一、海象运算符(:=)
Python 3.8 引入,赋值表达式。在 while/if 条件中赋值并使用。
while (line := input()) != "": process(line)losses = [ (y := compute_loss(x), y.item()) for x in batch]
注解:海象运算符减少重复计算。y := compute_loss(x) 先计算并赋值,再在后续表达式复用。
十二、模块与导入
import numpy as npimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom sklearn.model_selection import train_test_splitfrom typing import List, Dict, Optional, Tuplefrom .layers import MLPfrom ..utils import logger
注解:行业惯例:numpy as np、pandas as pd、matplotlib.pyplot as plt、torch.nn as nn、torch.nn.functional as F。这些缩写写进 PEP 8 建议遵守。
十三、错误处理
try: result = 1 / 0except ZeroDivisionError as e: print(f"caught: {e}")except (TypeError, ValueError) as e: print(f"type/value error: {e}")else: print("no exception")finally: print("always runs")def load_data(path): if not os.path.exists(path): raise FileNotFoundError(f"{path} not found") ...
注解:异常类型按具体到宽泛的顺序捕获。finally 块用于资源释放(关闭文件、释放 CUDA 显存)。
十四、列表推导 vs 生成器表达式
squares = [x ** 2 for x in range(10)]evens = [x for x in range(100) if x % 2 == 0]flat = [x for row in matrix for x in row]idx2token = {i: tok for i, tok in enumerate(vocab)}sq_gen = (x ** 2 for x in range(1000000))
注解:列表推导占 O(n) 内存,生成器表达式占 O(1)。处理百万级数据时用生成器;需要索引访问或多次迭代时用列表。
参考链接
[1] Python 3 官方语言参考: https://docs.python.org/zh-cn/3/reference/
[2] PEP 8 风格指南: https://peps.python.org/pep-0008/
[3] PEP 484 类型注解: https://peps.python.org/pep-0484/
[4] Python 数据模型文档: https://docs.python.org/zh-cn/3/reference/datamodel.html

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
