backtrace(四):Linux内核的 ORC Unwinder 与 SFrame 解析
- 2026-06-27 13:43:26
注意:以下的内容均为个人观点+在学习/实践中得出。
如果你看完后有不同的观点也没关系!请指出,我很乐意去学尝试积极的东西。
封面:
1. introduction
在前面一篇:backtrace(三):从 FP 到 DWARF :解析用户态回溯技术 讲了 FP 和 DWARF 的 CFI 实现 unwind 方法,但是如果再多搜索一下,你还会看到 Linux 内核里一个叫 ORC Unwinder 的东西[1]:

所以本文讲述 ORC Unwinder、SFrame 等内容。
2. Linux 的 ORC Unwinder
2.1 引入
如果单纯看 DWARF 里的 CFI,感觉已经万事大吉了,它和 FP 都是在解决如何恢复 previous state 的问题,区别只是 恢复规则存在哪里 和 恢复规则怎么执行。
那既然功能正确了,问题自然也解决了。了吗?
上面的工具似乎都是在调试用户空间的程序。
内核开发者往往想得更加深入(或许这才是工程上的真正考虑的问题):
功能正确 + 什么时候正确 + 在什么状态下正确 + 代价是多少
前面的 DWARF 做 unwind 的过程:基本就是查表,计算 CFA,恢复寄存器。
而这里有一个前提就是我的程序能够正确地解析规则,本质就是解释器解析各种字节码(
DW_CFA_xxx),有点像python脚本。这也很好理解,因为我们是在调出问题的用户程序,而 DWARF 生成的是外部调试信息(out-of-band(带外数据)),是给
GDB用的,那出问题的用户程序自然不会影响到我们的unwind。
但对于内核来说,kernel 都挂了(memory、stack可能坏了),还要在这个挂了的环境上跑个解释器?跑着跑着解释器挂了不是更离谱?而且最重要的是 DWARF 生成的信息似乎并不由内核所掌控(GCC 生成)。
所以我理解的 ORC Unwinder 更加重要的是应该是可靠性,而不是文档中所说的性能(simpler and faster),性能只是副产品。
这里插一句,以前我总是会怕表达自己对某个技术/文档的观点,总是会去想自己可能没想得到什么部分。但现在我觉得应该做的是:想确实没错,但更应该说出来让别人批判,要敢于犯错。
比如开发会遇到的各种问题:
Kernel Panic
Memory Corruption
Double Fault
Interrupt Nesting
...
所以在这样的极端环境下,我要的就是这个 Call Trace快速、可靠地工作,而不是像 DWARF 的 CFI 那样整个信息的表达有多全面(配个虚拟机啥的)。下图来源:[2]
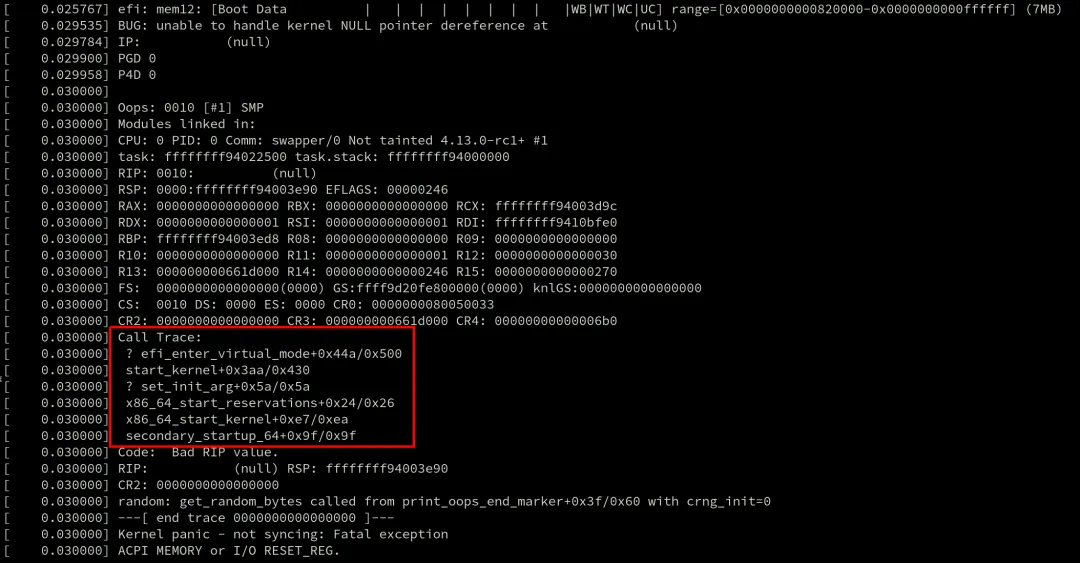
此时这里可以回去想一个内容,那对于用户程序来说,
FP那种方法肯定是not reliable(在中断和异常处理的情况下);DWARF 的CFI由于是在外部存调用信息,可以说是reliable的[2]?
Linus 也确实对上面的一些现象发表过评价:
Linus was clear that no DWARF unwinder would be allowed in the kernel: “Because from the last time we had fancy unwindoers [sic], and all the problems it caused for oops handling with absolutely zero_ upsides ever, I do not ever again want to see fancy unwinders with complex state machine handling used by the oopsing code.”
Linus 明确表示,绝不允许任何复杂的异常处理机制被引入内核中:“因为上一次我们使用了那些复杂的异常处理机制后,不仅给错误处理带来了诸多问题,而且没有任何好处。我再也不想看到那种需要复杂状态机来处理的异常处理机制被用于错误处理代码中了。”
而且有一点在内核很重要的是:汇编。
DWARF 依赖编译器生成 .eh_frame,但内核中有大量的手写汇编代码(估计也有几万行了)。编译器无法为汇编生成 CFI 信息,必须手动标注 .cfi_* 伪指令——这在历史上被证明是不可维护的。
"asm annotations were tried in the past and were found to be unmaintainable. They were often incorrect/incomplete and mde the code harder to read and keep updated."[1]
2.2 如何解决/设计
AI 总结的 DWARF 的问题:
太复杂(相当于跑虚拟机): DWARF 的 CFI规则本质上是一种字节码。解析它需要在内核里跑一个微型的状态机引擎。在 Panic 的废墟上跑虚拟机,极易引发二次崩溃(Double Fault),导致连崩溃日志都打印不出来。太慢: DWARF 的规则是增量式的(每一行只记录相对于上一行的变化),为了知道当前 PC 的恢复规则,解析器往往需要从函数开头的规则一路模拟计算过来,耗时极长。 不可靠的代码补丁: 内核经常使用汇编手写底层逻辑(如异常向量表、上下文切换),而手写汇编很难完美维护复杂的 DWARF 注释。
针对上面的种种问题,对于
x86-64平台,Josh Poimboeuf 在社区讨论开发过程中提出了一种新的unwinder和调试信息格式,就是 ORC Unwinder。该方案利用
objtool工具以及现有的堆栈验证机制,创建了一种全新的自定义调试信息格式。与 DWARF 格式相比,ORC 格式的体积更小、结构更简单。因此,在解析调试信息时,无需使用复杂的状态机来处理数据。
但是,我觉得上面还漏了一个点:少了 OS 内核非常重要的中断/异常处理,这在用户态都没有嘛,而且绝大多数崩溃也是在中断异常处理的时候呀。
我们知道,Linux 中每一个进程都会有各自的用户栈和内核栈,对于那些通过系统调用/中断/异常等方式进入到内核态的时候,就需要保存对应到上下文(也就是那个巨大的 pt_regs),所以这部分也是需要处理的。
2.2.1 自己理解
按照我常用的“程序是个状态机”的理论,来理解上面的 ORC Unwinder。
从 first principle 来看,DWARF CFI 是怎么做的?
由编译器编译器对应源文件,生成 .eh_frame存储对应恢复call stack的规则(就是那个CFI)GDB运行时去执行规则(.eh_frame),获取当前PC,获取 CFA 计算公式,计算 CFA,恢复上一层寄存器(LR/FP/SP)。
我们可以看到,这里本质上 GDB 还是在做运行时计算的,那熟悉 C++/性能优化的人,自然也能想到去用编译时计算来做。
所以 ORC 的核心思想,我理解的是,干脆在编译内核的时候,就让 GCC 直接把结果算好,然后结果全部摊平,构成一张查找表,之后用到就直接去查标记可。
这样子,我就不需要 DWARF 那种复杂的字节码(DW_CFA_xxx),但还是和我在第三篇的思想类似:仍然按照 PC 去查找 CFA。
当然,还有一些别的细节,比如编译构造这张表的时候就已经按
PC排好序,任何给定的PC,通过一次简单的二分查找,就能直接得到CFA和上一层栈帧的具体偏移。
所以你看,本质上 ORC 只是把 DWARF CFI 从 DWARF 中搬出来了,不需要这么 DWARF 里重型的”解释器/虚拟机“。
当然此时我觉得理解为状态机更好点,因为突然也意识到 DWARF 描述的是每条指令执行时的寄存器状态。
所以思想还是:backtrace(三):从 FP 到 DWARF :解析用户态回溯技术 中写到的很罗嗦的那一部分。
当然 ORC unwinder还有很多细节(其中我觉得最有意思的是怎么
objtool对于逆向 GCC 代码生成流程 +UNWIND_HINT_REGS的内容),还是推荐阅读:
内核文档:[1]:ORC unwinder:https://www.kernel.org/doc/html/latest/arch/x86/orc-unwinder.html
依旧是 MaskRay 大佬的文章:Stack unwinding:https://maskray.me/blog/2020-11-08-stack-unwinding
去看看深入的细节
哦对还有一个有意思的,来自内核文档的对于ORC的词源[1]:

9.6. 词源
兽人(Orcs),中世纪民间传说中的可怕生物,是矮人(Dwarves)的天敌。同样,ORC unwinder 的诞生正是为了对抗 DWARF 的复杂与缓慢。
“尽管兽人很少考虑问题的多种解决方案,但他们确实擅长把事情做成,因为他们是行动的生物,而非思考的生物。”类似地,与深奥的 DWARF unwinder 不同,求真务实的 ORC unwinder 不会浪费任何时间或硅基精力去解码那些基于状态机的、变长零扩展无符号整数字节编码的调试信息条目。
就像兽人经常挫败对手精心策划的计划一样,ORC unwinder 也经常以残酷、不屈不挠的效率展开栈回溯。
ORC 代表 Oops Rewind Capability(Oops 回退能力)。
2.4 自己实现
按照我的风格,肯定要自己弄一个ORC玩玩看啦。
代码在:https://github.com/JAILuo/wechat-demos/tree/main/debug-inside/di-04-backtrace/03-backtrace/03-orc
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
// 1. 模拟处理器上下文
// 注意:相比 DWARF 需要维护数十个寄存器,ORC 只关心 3 个核心寄存器
typedef struct {
uintptr_t pc;
uintptr_t sp;
} regs_t;
// 2. ORC 表结构 (极致压缩:摒弃了 DWARF 虚拟机)
// 内核只需要知道 "SP/FP/RA 在哪里",不需要通用表达式求值
typedef struct {
uintptr_t pc; // 指令地址(实际存储为 PC-relative 压缩值)
int16_t sp_offset; // SP 恢复:直接加法,无字节码解析
int16_t bp_offset; // FP 恢复:直接加法
uint8_t sp_reg:4; // 基址寄存器:SP/FP/PREV_SP/UNDEFINED
uint8_t type:2; // 0=CALL, 1=REGS(中断上下文 pt_regs)
} orc_entry_t;
// 按 PC 严格排序的 ORC 表 (编译期生成,运行时只读)
// 相比 DWARF 的 CIE/FDE 嵌套结构,这是纯扁平数组,极致缓存友好
static const orc_entry_t mock_orc_table[] = {
// sys_read: 普通函数调用,SP 偏移 16,FP 在 CFA-16
{ .pc = 0x1000, .sp_offset = 16, .bp_offset = -16, .sp_reg = 0, .type = 0 },
// do_IRQ: 中断帧!type=1 表示栈上保存了 256 字节的 pt_regs
// 这是 ORC 相比 DWARF 的关键优化:直接识别中断上下文
// 注意是:256(pt_regs)/中断 + 32(局部栈帧) = 288
{ .pc = 0x2000, .sp_offset = 288, .bp_offset = -16, .sp_reg = 0, .type = 1 },
// driver_bug: 底层驱动函数
{ .pc = 0x3000, .sp_offset = 32, .bp_offset = -16, .sp_reg = 0, .type = 0 },
};
#define ORC_TABLE_SIZE (sizeof(mock_orc_table) / sizeof(mock_orc_table[0]))
// ================= 内核符号表模拟 =================
typedef struct {
uintptr_t addr_start;
uintptr_t addr_end;
const char *func_name;
} symbol_t;
static const symbol_t mock_symtab[] = {
{ 0x1000, 0x1050, "sys_read" },
{ 0x2000, 0x2050, "do_IRQ" },
{ 0x3000, 0x3050, "driver_bug" }
};
const char* resolve_symbol(uintptr_t pc, uintptr_t *offset) {
for (size_t i = 0; i < sizeof(mock_symtab)/sizeof(mock_symtab[0]); i++) {
if (pc >= mock_symtab[i].addr_start && pc <= mock_symtab[i].addr_end) {
*offset = pc - mock_symtab[i].addr_start;
return mock_symtab[i].func_name;
}
}
*offset = 0;
return "<unknown_symbol>";
}
// ===================================================
// O(log N) 极速二分查找:在不触发任何虚拟机指令的情况下定位规则
// 对比 DWARF:需要解析 CIE/FDE 头,执行 CFA 程序字节码
const orc_entry_t* orc_find_entry(uintptr_t pc) {
int left = 0, right = ORC_TABLE_SIZE - 1;
const orc_entry_t *found = NULL;
while (left <= right) {
int mid = left + (right - left) / 2;
// ORC 的查找逻辑:纯整数比较,无变长编码解析
if (mock_orc_table[mid].pc <= pc) {
found = &mock_orc_table[mid]; // 命中最后一个小于等于当前 PC 的规则
left = mid + 1;
} else {
right = mid - 1;
}
}
return found;
}
// 带有 ASCII 树状渲染的内核 ORC Unwinder
void do_orc_unwind(regs_t *regs) {
printf("\n[Kernel Panic] Initiating ORC Extreme-Speed Unwinder...\n");
printf("==================================================================\n");
int depth = 0;
while (depth < 5 && regs->pc != 0) {
uintptr_t offset = 0;
const char *func_name = resolve_symbol(regs->pc, &offset);
const orc_entry_t *entry = orc_find_entry(regs->pc);
// 渲染树状缩进
for (int i = 0; i < depth; i++) printf(" │ ");
if (depth > 0) printf("\n");
for (int i = 0; i < depth; i++) printf(" │ ");
// 【核心视觉高亮】:检测到中断帧!
// ORC 的 type 字段直接区分中断上下文,无需像 DWARF 那样解析复杂的状态
if (entry && entry->type == 1) {
printf(" ├─> [Level %d] %s + 0x%lx <-- [⚠️ INTERRUPT: pt_regs Detected!]\n", depth, func_name, offset);
} else {
printf(" ├─> [Level %d] %s + 0x%lx\n", depth, func_name, offset);
}
for (int i = 0; i < depth; i++) printf(" │ ");
printf(" │ (PC: 0x%lx | SP: 0x%lx)\n", regs->pc, regs->sp);
if (!entry) {
for (int i = 0; i < depth + 1; i++) printf(" │ ");
printf("\n");
for (int i = 0; i < depth + 1; i++) printf(" │ ");
printf(" [!] ORC Table miss at PC 0x%lx. System Halted.\n", regs->pc);
break;
}
// ORC 极简查表算法:只有加法,没有解析器
// 对比 DWARF 的 execute_cfa_program():无字节码循环,无状态机维护
uintptr_t cfa = regs->sp + entry->sp_offset;
for (int i = 0; i < depth; i++) printf(" │ ");
printf(" │ [ORC Hit] CFA = SP + %d => 0x%lx\n", entry->sp_offset, cfa);
uintptr_t next_pc;
// 【核心修复】:如果是中断帧,必须去 pt_regs 的深处把 PC 挖出来!
if (entry->type == 1) {
// 中断发生前,SP 位于 CFA。随后压入了 256 字节的 pt_regs。
// 按照我们的 setup 模拟,被打断的 PC 存在 pt_regs 的底部,即 (cfa - 256 - 8)
next_pc = *(uintptr_t*)(cfa - 256 - 8);
for (int i = 0; i < depth; i++) printf(" │ ");
printf(" │ [Hardware Magic] Decoding PC from pt_regs...\n");
} else {
// 普通函数,PC 存在 CFA - 8
next_pc = *(uintptr_t*)(cfa - 8);
}
uintptr_t next_sp = cfa;
// 状态机极速回退
regs->pc = next_pc;
regs->sp = next_sp;
depth++;
}
printf("==================================================================\n\n");
}
// 模拟极其复杂的内核崩溃现场(带有硬件中断介入)
uint8_t fake_kernel_stack[1024];
void setup_kernel_environment(regs_t *regs) {
uintptr_t stack_bottom = (uintptr_t)&fake_kernel_stack[1024];
// 1. 用户态发起系统调用,进入内核态的 sys_read
// 栈布局:RA | FP | 局部变量...
uintptr_t cfa_sys_read = stack_bottom;
*(uintptr_t*)(cfa_sys_read - 8) = 0x0;
// 2. 硬件中断突然打断了 sys_read!
// 内核将整个 CPU 上下文 (pt_regs) 压入栈中,消耗了 256 字节。进入 do_IRQ。
// 这是 ORC type=1(REGS)的场景:不是普通函数调用,而是中断保存
uintptr_t cfa_irq = cfa_sys_read - 256;
*(uintptr_t*)(cfa_irq - 8) = 0x1024; // 被打断的地址:落在 sys_read 范围内
// 3. do_IRQ 处理时,调用到了有 Bug 的底层驱动
uintptr_t cfa_bug = cfa_irq - 32;
*(uintptr_t*)(cfa_bug - 8) = 0x2018; // 返回地址:落在 do_IRQ 范围内
// 4. 当前崩溃定格在 driver_bug 内部的 0x3010
regs->pc = 0x3010;
regs->sp = cfa_bug - 32; // driver_bug 自身消耗了 32 字节
}
int main() {
regs_t crashed_regs;
setup_kernel_environment(&crashed_regs);
do_orc_unwind(&crashed_regs);
return 0;
}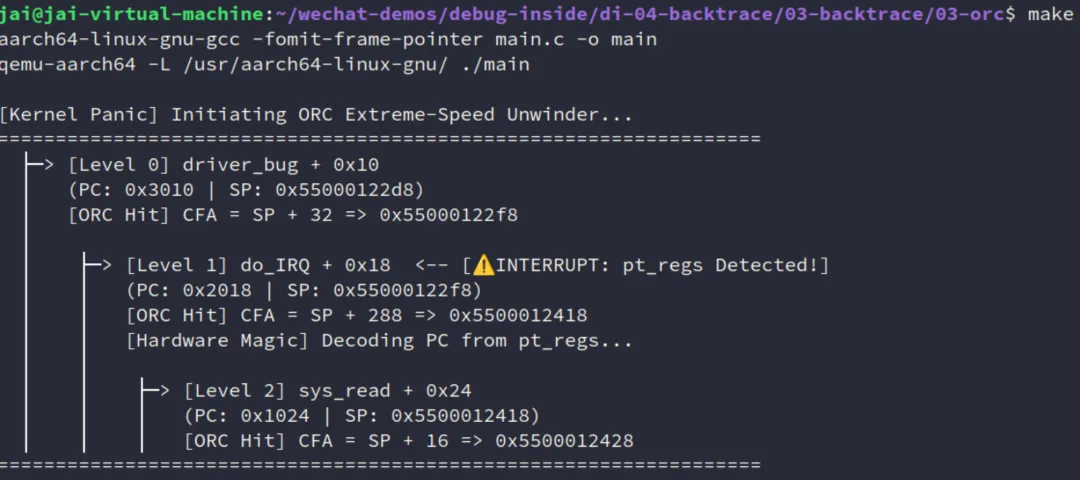
上面只是模拟的触发中断处理之后回溯的内容,具体 objtool 怎么生成这张表(特别是怎么处理中断上下文的回溯的)得具体看看。
AI 总结:
ORC 表由 objtool 反汇编分析生成;中断上下文通过 type=1 直接标记为 pt_regs 帧,运行时跳过普通 RA 寻址,从 pt_regs 结构里取回被打断的 PC——这是把 DWARF 的复杂状态机拍扁成一张只读数组的关键设计。
type=0) | type=1) | |
|---|---|---|
| 栈上保存了什么 | pt_regs(整个 CPU 上下文,x86-64 上 168~256 字节) | |
| RA 位置 | CFA - 8 | pt_regs 结构深处,需按架构偏移量去取 |
| objtool 怎么识别 | call 指令后的正常栈调整 | ENTRY()/ENDPROC() 标注的入口代码,或 UNWIND_HINT_REGS 等手工 hint |
内核入口代码(如 do_IRQ、entry_SYSCALL_64)在 asm 里用UNWIND_HINT_REGS宏(或等效标注)告诉objtool:"这里不是普通函数调用,硬件会自动压入 pt_regs" 。objtool分析到这些标注后,生成type = ORC_TYPE_REGS的条目,sp_offset覆盖pt_regs大小 + 函数自身栈帧。运行时 unwinder 看到 type == 1,就知道不能按普通CFA-8去取返回地址,而要去pt_regs结构里按固定偏移把被打断的 PC 挖出来。

2.5 reliable stacktrace
如果你前面仔细阅读了 ORC 的内容 ,你会发现,ORC Unwinder 的核心,是前面的 objtool。objtool 是 Linux 内核源码树中的一个编译时工具(位于 tools/objtool/)。
主要做的就是静态分析所有代码,然后生成 unwind metadata( .orc_unwind 和 .orc_unwind_ip),然后在链接时合并所有 ORC section → 启动时排序/后处理,最后给到内核 unwinder 使用。
为什么内核社区要费这么大劲搞这套庞大且复杂的静态分析机制?如果在内核社区的讨论中再上升一个抽象层次,我理解这么搞的目标其实是:Reliable Stacktrace(绝对可靠的栈回溯)。
是不是想到了我们前面是不是说的中断/异常处理对
unwind的影响?
下面的内容,由 AI 总结,他总结得挺好的,因为我总感觉自己好像没有特别懂文档这里的内容[3]。

按照内核文档的定义,普通的栈回溯往往是“尽力而为(best-effort)”的,这用来辅助调试打印 Oops 没问题。但在诸如 Livepatching(内核热补丁) 这样的场景下,系统必须 100% 确信当前没有任何任务停留在即将被替换的函数中。
这就要求 Stacktrace 必须做到:要么完美无缺地回溯出所有调用栈,要么明确报错说“我遇到了无法解析的脏状态(返回非 0)”,绝不能给出错误的猜测。
要做到这种可靠,文档指出了几个极其棘手的挑战(也是普通 unwinder 容易翻车的地方):
跨越中断与异常(Interrupts and Exceptions)
当函数正在执行 Prologue(压栈)或 Epilogue(弹栈)时,如果突然来了一个中断,此时的栈指针和帧指针是处于“中间不一致状态”的。普通的 unwinder 在这里极其容易迷失,而 Reliable Stacktrace 必须能精准识别出这种边界状态并决定是继续回溯还是安全拒绝(文档 4.3 节)。
返回地址被篡改(Rewriting of return addresses)
内核里有很多黑魔法,比如
ftrace(函数追踪)或kprobes(动态探测)。它们会用“蹦床(Trampoline)”技术把原本存在栈上的返回地址临时替换掉,等执行完探测代码再跳回去。这就导致 unwinder 在栈上找不到真实的返回地址(文档 4.4 节)。架构特有的寄存器二义性(Link Register Unreliability)
在 x86 上,
call指令会自动把返回地址压栈;但在 ARM64 等 RISC 架构上,
BL(函数调用)指令是把返回地址放到 LR (Link Register, X30) 寄存器中,而不是马上压栈。在函数执行的过程中,返回地址可能仅存在于 LR 中,也可能刚被压入栈中,甚至可能因为某些汇编优化被覆盖。如果仅仅依赖运行时去猜,很容易出现同一个函数在 Call Trace 中出现两次,或者层级颠倒的错误(文档 4.6 节)。
这就解释了为什么 x86 的 ORC 能成功: 面对上面这些变态的场景,x86 依靠 objtool 这个苦力,在编译时就把所有这些黑魔法、中断上下文和栈变化情况全部分析得一清二楚,做成一张绝对可靠的表。运行时查表,自然就实现了 Reliable Stacktrace。
3. SFram
3.1 introduction
你会发现,ORC 似乎还只是给 x86-64 用的,2026年了,arm64 似乎都没有 ORC?
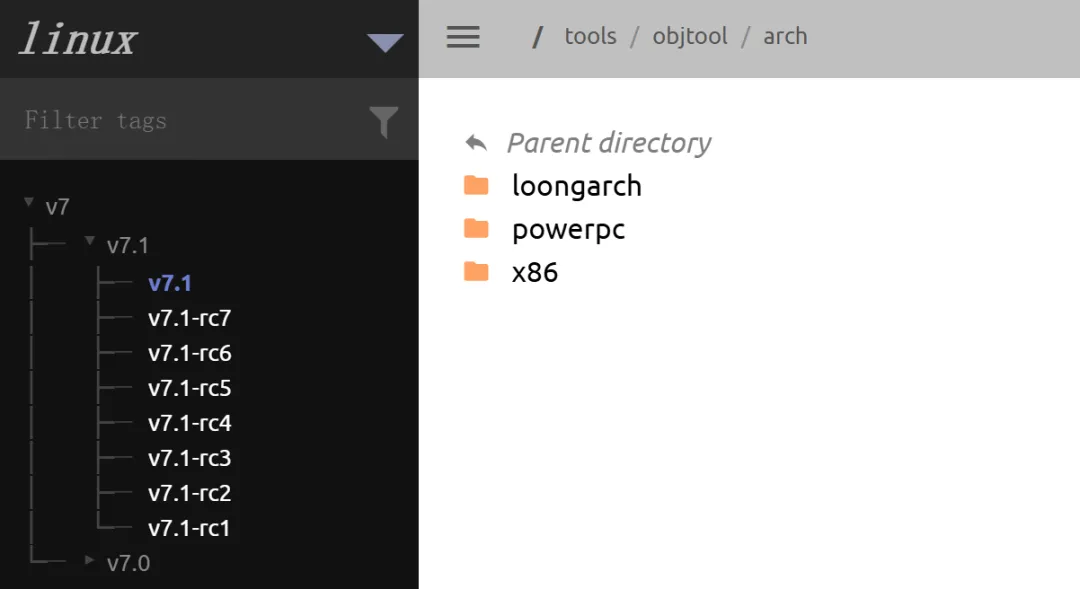
尽管 Linux 社区这几年也一直有在做 objtool → arm64[4](虽然看上去就只有 objtool 的作者 Josh Poimboeu 自己在弄),patch 也有,但 ORC metadata format 还就是没正式进入 arm64 主线。
为啥呢?arm64 社区在关心另一个方向:SFrame。
或许你会说,既然有个这么好用的 ORC Unwinder,reliable stacktrace 不也做的OK嘛?
为啥不用呢?开发者也不是没想到,他们的起初的做法[5]:
Proposed a “dynamic” form of frame pointer validation
The frame pointer on the stack is validated against the frame pointer offset pulled from the ORC table If the calculated FP does not match the expected one, the unwind is considered unreliable Involved substantial reorganization of the objtool/ORC code to separate the architecture-generic vs architecture-specific components
提出了一种“动态”形式的帧指针验 堆栈上的帧指针根据从ORC表中提取的帧指针偏移进行验证 如果计算出的FP与预期不符,则认为解卷不可靠 涉及对objtool/ORC代码进行实质性重组,以将架构通用组件与架构特定组件分开
但是社区给的回复,ORC 强依赖 objtool,非常脆弱[5]:
逆向控制流的问题: objtool的本质是去逆向工程(Reverse-engineer)编译器生成的二进制控制流。一旦遇到复杂的边界情况(例如跳转表 Jump tables),这种事后推导非常容易失败。(本质就是一种hack)维护成本:编译器的代码生成策略是不断演进的。只要编译器一改动, objtool就必须被动地跟进维护去适配新的指令排列,这种打补丁式的方案在长远来看是不可持续的。

例子 A:尾调用优化(Tail Call Optimization) 正常函数结束,汇编是这样的:
恢复栈底 pop %rbp返回上一层 retobjtool一看这套连招,就知道:“哦,函数结束了,栈状态安全。”但突然有一天,GCC 编译器升级了,变得更聪明了。它发现你的函数在最后一行调用了另一个函数。为了省事,GCC 直接不用
call和ret了,直接生成一条jmp(无条件跳转)跳到下一个函数。 这下objtool又傻眼了:“说好的ret结尾呢?这个jmp到底是函数内部的代码跳转,还是函数结束的标志?” 于是,内核开发者只能赶紧去改objtool的 C 代码,给它打个补丁:“如果遇到某某情况的jmp,你要把它当成函数返回来处理。”
例子 B:安全漏洞的终极折磨(如 Spectre 漏洞的 Retpoline 补丁) 当年爆出 CPU 幽灵漏洞(Spectre)时,为了防止黑客利用“间接跳转”预测执行,编译器发明了一种极其反人类的黑魔法叫 Retpoline。 它故意用一套
call、pause、改写栈上返回地址的魔改汇编,把 CPU 的预测器骗得团团转。 连 CPU 都被骗了,负责静态分析汇编的objtool直接原地爆炸。为了让objtool能看懂这种为了防漏洞而故意写得乱七八糟的汇编,内核维护者被迫在objtool里写了成百上千行的“特例判断代码”。
所有:与其用外部工具在事后辛苦地去“猜”控制流,更理想的方案应该是直接使用由编译器(Compiler)原生生成的数据[5]。
3.2 引入SFrame
可以说:
与其让外部工具去猜编译器做了什么,不如直接让编译器把答案留下来。
这便是 SFrame 的核心思想。
实际上 SFrame 做的事情非常直接,也和 ORC 很像,但是它只保留堆栈跟踪所需的最少必要信息[6],unwind 的时候直接查表即可(FRE),关键还是下面这些信息:
FP 在哪里
RA 在哪里
CFA 怎么算
但是,和 ORC 最大一点的区别是:
ORC→ 编译后计算SFrame→ 编译器直接生成结果
或者引入 objtool 说的更准确一点的,就是不用 hack 了:Similar to ORC, but avoids reverse-engineering the binary[5]:
ORCCompiler → Binary → objtool → ORC TableSFrameCompiler → SFrame
一个事后分析,一个原生生成看着就不错。
而且,我觉得更为重要的是 SFrame 还能在用户态上跑,因为它从设计之初就是GNU Binutils 标准格式[6],而非内核专属(ORC 要用内核的工具 objtool),比如以下对比:
.sframe | .orc_unwind | |
PT_GNU_SFRAME | ||
SHT_GNU_SFRAME | ||
任何 ELF 可执行文件都可以携带 .sframe段内核加载器( fs/binfmt_elf.c)通过标准PT_GNU_SFRAME识别并映射perf/BPF 可以像访问 .text一样访问.sframe
可以具体看 wiki[6]:
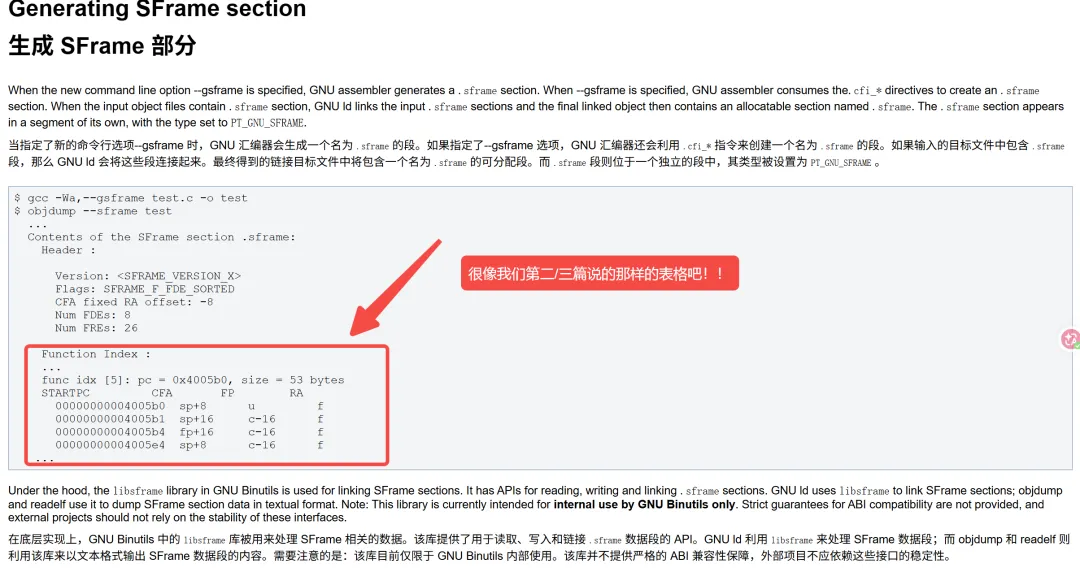
当然了,这个特性还是在比较新的 binutils 里支持的:
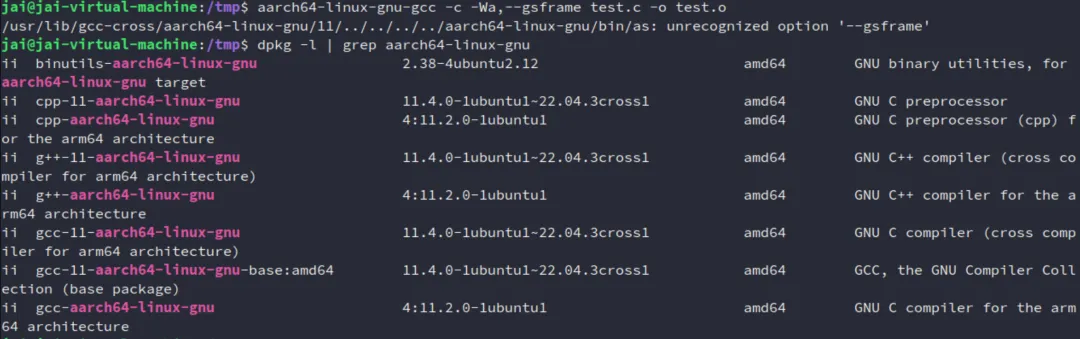
我的 Ubuntu22.04 就不支持:
3.3 现状
上面说了一堆的优点,但 SFrame 还是有很大争议的:
Peter Zijlstra (x86 ORC 开发者) 认为:x86_64 不会采用 SFrame,ORC 已足够好[7] MaskRay (LLVM 开发者) 质疑: .sframe体积比.eh_frame大 10%,用户态 adoption 不现实[7]但 ARM64 社区 认为:这是 ARM64 获得 reliable stacktrace 的最可行路径[8]
还有就是用户态 SFrame 有一个致命的安全问题:
问题:perf 采样发生在中断/NMI 上下文,此时:
用户态页表可能未映射 .sframe段可能被 swap out直接读取用户态内存会导致 page fault
在中断上下文中触发 page fault 是致命的——内核无法处理(没有可切换的任务上下文),只能 panic。
解决方案:Deferred Stacktrace
传统 perf 采样流程:
NMI/IRQ ──► 读取 PC/SP ──► 立即 unwind ──► 输出调用链
↑
└── 此时读用户态 .sframe 可能 page fault!
Deferred Stacktrace 流程:
NMI/IRQ ──► 读取 PC/SP ──► 存入 perf ring buffer ──► 返回
↓
进程返回用户态时(syscall exit)────────────► 读取 .sframe ──► unwind
↑
└── 此时用户态内存安全可访问
但这带来了新的问题:
BPF 无法实时 unwind:BPF 程序在中断上下文中不能延迟处理 可能丢栈:如果采样发生在 syscall 末尾,进程可能在下一次采样前退出,导致栈丢失
还有一个性能悖论:
SFrame 的目标是省略 frame pointer 以节省寄存器,但:
FP unwind:2-3 次内存访问,极快 SFrame unwind:二分查找 + 内存访问 + 计算,更慢
如果 omit-fp 节省的性能被 unwind 开销抵消,得不偿失。
总而言之,该特性仍在发展当中,说不定未来呢?
4. 拓展
在这一篇:你的技术想象力,受限于你的信息边界 中:
“(我觉得)在这个时代的下,你们最需要的就是有一个清晰的概念什么事情是能办到的,因为人没有办法做自己想象不到的东西,而扩展你的想象力的方式就是去看别人想到了什么。“
所以,在今后的文章中,考虑篇幅合适的情况下,我都会用以上类似的
prompt+ 本文前面几章的总结 +xxx官方手册,去和 AI 聊,让 AI 帮我看看有什么冷门但重要的东西值得去看看的!下面写我觉得有意思的。
4.1 livepatch 和 OTA
经过前文的理解,我们一般看的普通的 backtrace,其实做的是:尽量恢复(Best Effort)。
而 ORC 的终极目标不是 ORC,而是:Reliable Stacktrace(要么完全正确/要么明确失败)
因为普通的 Oops 栈回溯哪怕错了一层,顶多是开发者看日志时骂一句。
但热补丁场景(比如给底层的存储驱动 sd_mod 或文件系统打补丁),系统必须 100% 确认:
当前没有任何一个休眠的线程正停留在准备被替换的旧函数中。
如果有,热替换一旦执行,线程醒来后执行的控制流就会全部错乱。
对 livepatch 感兴趣的还是阅读:参考 [3]
除此之外,如果有人熟悉 OTA 的话,可能会混淆(我没做过OTA,我只知道是远程更新,下面有误请指出)。
实际上 OTA 应该不需要这个的,OTA 本质是:
旧镜像 → 重启 → 新镜像
就比如:slot_a/slot_b 的 A/B 升级。
所以所以 OTA 不关心当前线程在哪里,因为所有线程都死了,直接重启即可。
所以不要弄混了?
但是如果你完全可以继续追问,为什么自己的手机好像是无感的OTA呢?怎么做到的?我不懂,问了AI后给我了一个名词:RoR(Resume-on-Reboot)
传统 OTA 更新流程中,重启后会遇到一个问题:
Android 的 Credential Encrypted(CE)存储 在每次重启后都会被锁定,必须等用户输入 PIN/密码/图案后才能解锁。
而 OTA 更新后,系统需要重建 Dalvik 缓存(显示为 "Android is upgrading..."),这个操作需要访问 CE 存储中的 App 数据。如果用户不在场手动解锁,更新流程就会卡在那里,设备无法真正完成启动。
RoR的思路是:在 OTA 安装前,安全地临时保存用户的锁屏凭证(PIN/密码/图案),重启后自动用这些凭证解锁 CE 存储,让系统可以在无人值守的情况下完成 Dalvik 缓存重建等收尾工作。
所以还是挺有意思的!
4.2 性能
观测者的困境:eBPF 与性能剖析(Profiling)
观测系统本身的开销,不能改变被观测系统的状态(海森堡测不准原理的软件版)。
概念速览:在做底层性能分析时(比如用 eBPF 追踪中断延迟或块设备 I/O),我们需要高频地抓取调用栈。如果像 SFrame 那样存在用户态 Page Fault 的风险,或者像 DWARF 那样耗时太长,观测工具自己就会成为系统的性能瓶颈,甚至引发崩溃。这也是为什么 eBPF 社区对快速的、基于 BPF 内部实现的 unwinder 需求极其旺盛的原因。
这部分我懂得不多,所以不展开讲啦,但是我知道 profile 和 Observability 对于 Call Stack 确实很重要。
perf、eBPF、ftrace
本质都依赖:Call Stack,因为普通的 PC 只能告诉你现在在哪,而 Call Stack 能告诉你为什么在这。
参考
[1] 9. ORC unwinder — The Linux Kernel documentation:https://www.kernel.org/doc/html/latest/arch/x86/orc-unwinder.html
[2] The Linux x86 ORC Stack Unwinder:https://www.codeblueprint.co.uk/2017/07/31/the-orc-unwinder.html
[3] Reliable Stacktrace — The Linux Kernel documentation:https://docs.kernel.org/livepatch/reliable-stacktrace.html
[4] objtool/arm64: Port klp-build to arm64:https://lwn.net/Articles/1072616/
[5] Arm64 SFrame for Reliable Stacktrace:https://lpc.events/event/19/contributions/2077/attachments/1874/4018/Arm64%20SFrame%20for%20Reliable%20Stacktrace%20--%20LPC%202025.pdf
[6] sframe - BINUTILS Wiki:https://sourceware.org/binutils/wiki/sframe#What_is_SFrame.3F
[7] LKML: Fangrui Song: Re: Concerns about SFrame viability for userspace stack walking:https://lkml.org/lkml/2025/10/30/1959
[8] [RFC] Adding SFrame support to llvm - Code Generation - LLVM Discussion Forums:https://discourse.llvm.org/t/rfc-adding-sframe-support-to-llvm/86900/6

