引言
数据分析初学者最容易卡住的地方不是写代码,而是不知道该按什么顺序做事。拿到一个数据集,上来就画图,画出来发现数据没洗干净;先做统计分析,发现缺失值还留着结果全偏了。这些问题的根源都一样——缺少一条清晰的执行路线图。
数据分析本质上是一条数据管道,每个环节的输出就是下一个环节的输入。按顺序走下来,每一步都知道自己为什么做这件事,做完心里就有数。这条管道大致分为四个阶段:拿到数据 → 清洗数据 → 计算指标 → 画图展示。把这条管道走通,就是一次完整的数据分析了。
下面把每个阶段具体要做什么、用哪些代码、画出什么样的图,一次讲清楚。
一、数据来源与获取
数据是分析的基础。从哪里拿数据取决于你要分析什么问题。常见的数据获取途径包括:
- 公开数据集平台:如 Kaggle、阿里云天池、百度飞桨 AI Studio、UC Irvine Machine Learning Repository 等,提供大量标注好的数据集,适合学习和快速验证想法。
- 数据交易平台:提供经过清洗和标注的商业数据,通常需要付费购买。
- 网络指数:如百度指数、谷歌趋势等,反映公众对特定关键词的关注度。
- 网络采集器:使用可视化工具(如八爪鱼、火车头)抓取网页数据,无需编程。
- 网络爬虫:编写程序(如 Python 的 Scrapy、Requests 库)自动抓取和解析网页数据,灵活度高。
- 数据导航网站
此外,业务系统导出的 Excel/CSV 文件、开放的 API 接口也是常见的数据来源。
不管数据从哪里来,进入 Python 的第一步都是用 pandas 把它读进内存:
import pandas as pd# CSV 文件df = pd.read_csv("dataset.csv")# Excel 文件df = pd.read_excel("data.xlsx")# 快速预览前 5 行df.head()# 查看数据结构:行列数、列名、数据类型、缺失情况df.info()
df.info() 输出的信息非常关键——Non-Null Count 这一列直接告诉你每一列有没有缺失值,Dtype 列告诉你数据类型是否读对了。比如一列数字读出来是 object,说明里面混入了文本,需要在下一步清洗时处理。
做完这一步,存一份原始数据的备份:
df.to_csv("raw_backup.csv", index=False)
后面清洗错了可以回头重来,不用重新读源文件。
二、数据预处理
原始数据很少能直接拿来分析。缺失值、异常值、量纲不统一、分类变量需要转换——这些是每次分析都绕不开的。这个阶段通常占据整个分析过程一半以上的时间,也是决定分析质量最关键的一环。
2.1 缺失值处理
先弄清楚每一列缺了多少:
df.isnull().sum() # 每列缺失数量df.isnull().sum() / len(df) * 100 # 缺失比例
根据缺失比例和数据类型,选择的处理方法不同。从简单到复杂,常见的数据补全方法包括:
- 均值/中位数/众数填充
- 回归填补法:利用其他字段建立回归模型预测缺失值,适合字段间存在线性关系的情况
- KNN 填充:找到与该样本最相似的 K 个邻居,用它们的均值或投票结果填补
- 高斯混合模型(GMM)补全:假设数据服从多个高斯分布,用期望最大化(EM)算法迭代估计缺失值
- C 均值补全
- 决策树填补法
具体选择哪种方法取决于数据规模和缺失模式:
# 数值列中位数填充(快速方案)df['col'].fillna(df['col'].median(), inplace=True)# 分类列众数填充df['category'].fillna(df['category'].mode()[0], inplace=True)
填充后建议做一次断言,确认没有遗漏:
assert df['col'].isnull().sum() == 0
2.2 异常值检测
数值列的异常值可以用箱线图方法来定位。箱线图的内限将数据分为四个区间,落在上下边缘之外的点就是异常值候选:
Q1 = df['col'].quantile(0.25)Q3 = df['col'].quantile(0.75)IQR = Q3 - Q1outliers = df[(df['col'] < Q1 - 1.5 * IQR) | (df['col'] > Q3 + 1.5 * IQR)]
异常值不一定要删除。先判断原因:如果是录入错误就修正或删除,如果是真实的极端情况(比如某天的销售额特别高),在分析报告中注明即可。
2.3 数据归一化
当数据中各列的量纲不一致时——比如一列是 0-100 的分数,另一列是几千元的收入——直接放一起计算会导致数值大的列主导结果。需要用归一化把它们拉到同一尺度:
# Z-score 标准化(均值为 0,标准差为 1)df['z_score'] = (df['col'] - df['col'].mean()) / df['col'].std()# Min-Max 归一化(映射到 [0, 1])df['min_max'] = (df['col'] - df['col'].min()) / (df['col'].max() - df['col'].min())# 中值归一化(映射到 [-1, 1] 附近,抗极端值干扰)df['median_norm'] = (df['col'] - df['col'].median()) / (df['col'].max() - df['col'].min())
Z-score 适用于数据近似正态分布的情况;Min-Max 简单直观但容易被极端值拉偏;中值归一化用中位数代替均值,对极端值更稳健。
2.4 分类变量编码
分类数据(如"地区"、“类型”)需要转换成数值才能参与计算。最常用的是 One-Hot 编码:
pd.get_dummies(df, columns=['category'])
如果分类取值超过 20 个,One-Hot 会让矩阵变得过于稀疏,此时可以考虑频率编码或目标编码。
2.5 数据均衡处理
在实际数据中,类别分布不均的情况很常见——比如信用卡欺诈检测中,正常交易和欺诈交易的比例可能高达 50:1。直接在这种不均衡数据上建模,模型会偏向多数类,少数类的预测效果会很差。这时就需要对数据进行均衡化处理:
- 欠采样:从多数类中随机丢弃一部分样本,使各类数量接近。优点是简单,缺点是可能丢失多数类中有价值的信息
- 过采样:增加少数类的采样频率,直接复制少数类样本。优点是保留了全部数据,缺点是在少数类上容易过拟合
- SMOTE(合成少数类过采样技术):在少数类样本之间插值合成新样本,而不是简单复制。它在两个邻近的少数类样本之间随机生成新样本点,有效缓解了直接复制带来的过拟合问题
from imblearn.over_sampling import SMOTEsmote = SMOTE(random_state=42)X_resampled, y_resampled = smote.fit_resample(X, y)
在数据分析项目中,如果发现目标变量的类别分布严重倾斜,数据均衡处理能显著提升模型在少数类上的表现。
数据预处理做完之后,数据的质量就有了基本保证。接下来就可以进入统计分析和可视化阶段了。把这一步做扎实,后面的分析和图表都会顺畅很多。
三、数据分析说明
数据洗干净之后,先别急着画图,先用统计指标摸清数据的基本面貌。这一步的作用是:用数字描述数据,让你知道每一列的分布特征、各列之间的关系,以及哪些变量值得深入分析。
3.1 描述性统计
对数值列统一计算基本统计量:
输出的表格包括计数、均值、标准差、最小值、25% 分位数、中位数、75% 分位数和最大值。看这张表时重点关注三个信号:
- 均值与中位数的差距:差距越大,数据偏斜越严重。均值远大于中位数说明数据右偏,少数大值拉高了整体
- 标准差相对均值的大小
- 四分位间距(IQR = Q3 - Q1)
分类列用频数统计:
df['category'].value_counts()
3.2 分组分析
绝大多数分析都需要对比不同组别之间的差异。比如对比不同地区的销售额、不同年份的通过率。分组聚合是这类问题的标准解法:
df.groupby('group')['value'].agg(['mean', 'std', 'count'])
分组计算后的结果最好紧接着做可视化——分组柱状图或箱线图能让数字对比一目了然。
3.3 相关性分析
计算数值列之间的相关系数,判断变量间是否存在线性关联:
相关系数的绝对值:大于 0.7 为强相关,0.4~0.7 为中等相关,小于 0.4 为弱相关。一组强相关的变量在后续分析中可以合并处理或只保留其中一个。
到这里,我们已经完成了数据的统计描述和关系初探。下一步就是把这些数字结论转换成可视化的图表。
四、数据可视化
可视化是整个分析流程中最直观、也最能打动人的环节。但画图不是越多越好,关键是选对图表类型。下面按 Python 数据分析中常用的十一种图表逐一介绍,每种图表先说明"什么时候用它",再给出可运行的代码。
4.1 直方图(Histogram)
用途:查看单个数值变量的分布形态,比如分数分布、年龄分布、词频分布。
直方图把数据按值的大小分成若干个区间(bins),统计每个区间内的样本数量。通过直方图可以快速判断数据是否偏斜、是否呈现双峰或多峰分布。
import matplotlib.pyplot as pltplt.figure(figsize=(8, 5))plt.hist(df['value'], bins=20, edgecolor='white', color='steelblue')plt.xlabel('Value')plt.ylabel('Frequency')plt.tight_layout()plt.show()
bins 参数控制柱子数量,数据量大时适当增加到 20~30,找到最能反映数据分布特征的粒度。
4.2 柱状图(Bar Chart)
用途:对比不同类别的数值大小,比如各季度销售额、各题型的平均分、各城市人口。
柱状图的 X 轴是分类变量,Y 轴是数值变量。类别数量较多时建议取 Top N,其余的归入"其他"。
top10 = df.head(10)plt.figure(figsize=(10, 6))plt.bar(top10['category'], top10['value'])plt.xticks(rotation=45)plt.tight_layout()plt.show()
类别名较长时改用 plt.barh() 做横向柱状图,可读性更好。如果需要展示每个类别内部的分组情况,可以用堆叠柱状图或分组柱状图。
4.3 折线图(Line Chart)
用途:展示数据随时间或连续变量的变化趋势,比如股票价格走势、气温变化、累计覆盖率曲线。
折线图通过连接数据点来强调变化的连续性和趋势方向。画折线图的关键是 X 轴必须是有序的连续变量(通常是时间)。
plt.figure(figsize=(10, 5))plt.plot(df['date'], df['value'], marker='o', linewidth=1.5)plt.grid(alpha=0.3)plt.xticks(rotation=45)plt.tight_layout()plt.show()
一张图上折线不要超过 5 条,否则会互相遮挡难以辨认。多组数据需要对比时,可以用不同颜色和线型区分。
4.4 箱线图(Box Plot)
用途:对比多组数据的分布特征,同时暴露出各组的异常值和中位数差异。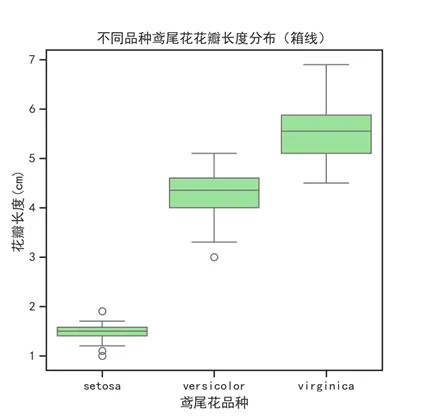
箱线图的构成从上到下依次为:上边缘(最大值)、上四分位(Q3)、中位数(Q2)、下四分位(Q1)、下边缘(最小值)。中位线的位置直接反映数据的偏斜方向——偏上表明数据左偏,偏下表明右偏。
import seaborn as snsplt.figure(figsize=(8, 6))sns.boxplot(data=df, x='group', y='value')plt.tight_layout()plt.show()
箱线图特别适合在做分组对比分析时使用——比看一列数字直观得多。
4.5 散点图(Scatter Plot)
用途:观察两个数值变量之间是否存在关联以及关联的形态,比如身高与体重的关系、广告投入与销售额的关系。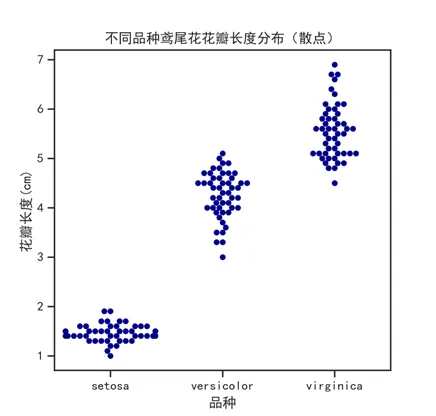
plt.figure(figsize=(8, 6))plt.scatter(df['var1'], df['var2'], alpha=0.5)plt.xlabel('Variable 1')plt.ylabel('Variable 2')plt.tight_layout()plt.show()
数据点超过 500 个时务必设置 alpha 半透明参数,否则重叠的点会掩盖真实密度。也可以用 sns.lmplot() 在同一张图上叠加回归线,帮助判断线性趋势。
4.6 热力图(Heatmap)
用途:展示二维矩阵数据,最常见的应用是相关性矩阵和混淆矩阵。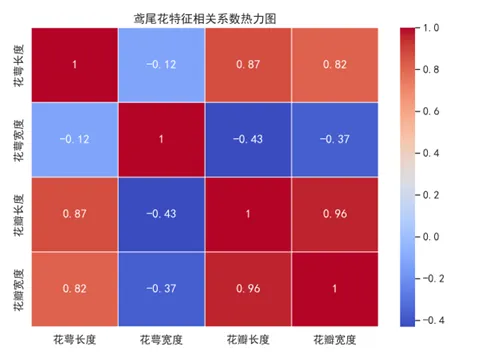
热力图用颜色深浅表示数值大小,配合数据标签可以让读者一眼看出哪些值高、哪些值低。
plt.figure(figsize=(8, 6))sns.heatmap(df.corr(), annot=True, cmap='coolwarm', fmt='.2f')plt.tight_layout()plt.show()
annot=True 在单元格内显示数值,cmap='coolwarm' 用冷暖色区分正负相关。如果行列数超过 20,建议先做聚类再画图,否则矩阵可读性会大幅下降。
4.7 饼图(Pie Chart)
用途:展示各部分占整体的比例关系,适合类别较少的组成结构分析。
饼图从 12 点方向开始,按数值从大到小顺时针排列。类别超过 5 个时建议改用柱状图,因为饼图的扇形角度对比不如柱状图的高度对比敏感。
plt.figure(figsize=(7, 7))df['category'].value_counts().plot.pie(autopct='%1.1f%%')plt.tight_layout()plt.show()
如果需要强调某个类别占据"半数以上"的效果,饼图会比柱状图更有视觉冲击力。
4.8 词云图(Word Cloud)
用途:从文本数据中提取高频关键词并做全景展示,适合做词频概览、文本主题快速定位。
词云图不是严格的统计图表,但它能直观传达"哪些词出现得最多"这一信息,很适合作为文本分析的开场视觉。
from wordcloud import WordCloudfrom collections import Counterword_freq = Counter(your_word_list)wc = WordCloud(width=800, height=500, background_color='white', max_words=200, colormap='viridis')wc.generate_from_frequencies(word_freq)plt.figure(figsize=(10, 7))plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.tight_layout()plt.show()
做词云之前务必要做停用词过滤(a, the, is 等高频但无意义的词),否则结果会被功能词淹没。还可以加词性过滤,只保留名词和动词,让词云更有信息量。
4.9 小提琴图(Violin Plot)
用途:结合箱线图与密度图的优点,展示多组数据的分布形态和概率密度。
小提琴图在箱线图的基础上,左右两侧对称绘制了核密度估计曲线,既能看到中位数、四分位距等统计量,又能看到数据分布的形状——是单峰、双峰还是平坦分布。
import seaborn as snsplt.figure(figsize=(8, 6))sns.violinplot(data=df, x='group', y='value')plt.tight_layout()plt.show()
当数据量较大且组数较多时,小提琴图比箱线图更能揭示分布内部的细节。如果只想看分布轮廓、不关心异常值点位,小提琴图是箱线图的理想替代方案。也可以叠加箱线图一起使用,兼顾统计量和分布形态。
4.10 雷达图(Radar Chart)
用途:多维度对比不同对象的各项指标,适合做综合能力评估、产品对比分析。
雷达图将多个指标均匀分布在圆周上,每个指标对应一条半径,将各维度的数值连接成封闭多边形。谁的"面积"越大,综合表现越好。
import numpy as npimport matplotlib.pyplot as pltcategories = ['指标A', '指标B', '指标C', '指标D', '指标E']values = [85, 70, 90, 60, 75]angles = np.linspace(0, 2 * np.pi, len(categories), endpoint=False).tolist()values += values[:1]angles += angles[:1]fig, ax = plt.subplots(figsize=(7, 7), subplot_kw=dict(polar=True))ax.fill(angles, values, alpha=0.25)ax.plot(angles, values, linewidth=2)ax.set_xticks(angles[:-1])ax.set_xticklabels(categories)plt.tight_layout()plt.show()
雷达图对指标数量比较敏感,维度控制在 5~8 个最佳。超过 8 个时图形会变得过于密集,难以分辨。另外要确保各维度的量纲一致(或已归一化),否则数值大的维度会主导图形视觉效果。
4.11 分面图 / 散点图矩阵(Pairplot)
用途:在多变量数据集中同时观察每两个变量之间的关系,快速发现潜在关联和分组规律。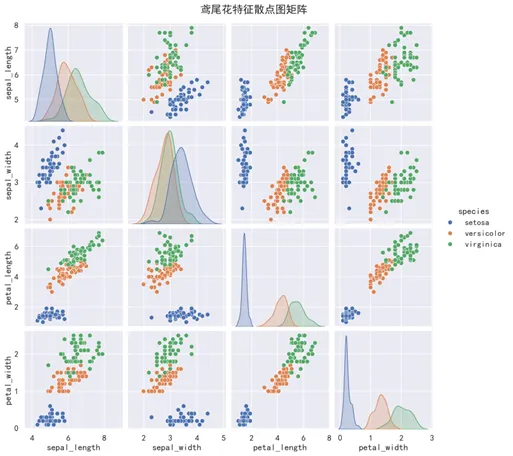
Pairplot 将数据集中的数值列两两配对,对角线画直方图或密度图,非对角线画散点图,并且可以根据分类变量着色。在数据探索阶段,一张 pairplot 顶得上十几张单独散点图。
import seaborn as sns# hue 按分类变量着色,快速观察组间差异sns.pairplot(df[['var1', 'var2', 'var3', 'group']], hue='group')plt.tight_layout()plt.show()
变量数量超过 6 个时建议先做筛选,只保留最核心的数值列,否则矩阵规模过大(n 个变量产生 n×n 个子图)将难以阅读。Pairplot 非常适合在完成相关性分析之后使用,把相关系数表中的数字关系变成可视化的图形。除此之外,sns.FacetGrid 还可以实现更灵活的分面功能,按一个或多个分类变量拆分子图,在每个子图上绘制不同维度的分布或趋势。
图表类型选择速查:
五、总结与工具推荐
数据分析流程是一条从数据到结论的完整管道:获取数据 → 清洗预处理 → 统计计算 → 可视化展示。每个环节都有明确的目标和产出,跳过一个环节往前赶,最终还是要回来补。把这条管道走顺了,以后拿到任何数据集都知道该从哪里下手、每一步做什么。
对于初学者来说,建议先从 pandas 入手把数据处理基本功打扎实,然后掌握 Matplotlib 和 Seaborn 这两套可视化工具:
- Matplotlib:Python 可视化的底层框架,所有图表的基础,灵活度高但默认样式偏保守
- Seaborn:基于 Matplotlib 的统计专用库,默认配色和样式更美观,适合快速出图
- Plotly:交互式图表库,适合需要鼠标悬停提示、缩放查看的 Web 场景
- Pyecharts:ECharts 的 Python 封装,图表类型丰富,适合中文展示场景
日常课程作业和实验报告,推荐 Seaborn + Matplotlib 组合;项目展示或网页嵌入,考虑 Plotly 或 Pyecharts。
做数据分析不追求一次性全部做对。在实践中不断遇到问题、解决问题,才是最好的学习方式。
本文数据分析流程部分参考 GB/T 37721-2019《信息技术 大数据 分析系统功能要求》和 GB/T 38673-2020《信息技术 大数据 大数据系统基本要求》。
免责声明:本文内容仅供数据分析流程学习交流使用。文章中涉及标准流程等信息均来自公开资料,如有侵权行为,请联系作者删除相关内容。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
