少儿自学编程第44课:Python 用摄像头或图片实时识别手写数字(Sklearn版)
- 2026-06-27 17:45:20

第43课我们用TensorFlow训练了手写数字识别模型,本来打算第44课用它配合摄像头做实时识别。
但因为电脑CPU不支持AVX指令集,TensorFlow死活跑不起来,折腾了半天。
Tyree说:“难道就没办法了吗?有没有一种不需要装那么重的东西就能识别数字的方法?”
我说:“当然有。第41课我们用 `scikit-learn` 训练了一个数字识别模型,准确率也很高。而且它非常轻,不用装几百兆的库,运行也快。”
他很开心:“那我们就用那个吧!省得再跟TensorFlow较劲了。”
今天课程我们就用 `scikit-learn` 训练的SVM模型,配合OpenCV,实现图片和摄像头的手写数字实时识别。
不需要TensorFlow,不需要GPU,普通电脑就能跑。
01. 准备工作
1.1 安装必要的库
pip install opencv-python numpy scikit-learn joblib matplotlib
这些库体积小、安装快,而且不会遇到AVX兼容问题。
1.2 先训练一个SVM模型并保存
如果你在第41课已经训练过并保存了模型(`digits_model.pkl`),可以跳过这一步。否则,运行以下代码生成模型文件:
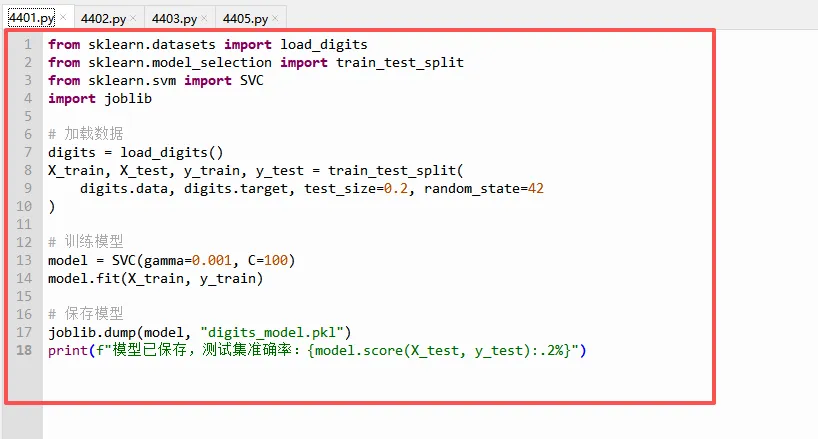
⭐重点讲解:
`load_digits()` 加载的是8x8像素的手写数字图片数据集,共1797张。
`train_test_split` 将数据分成训练集(80%)和测试集(20%),`random_state=42` 保证每次分割结果一样。
`SVC(gamma=0.001, C=100)` 是支持向量机分类器,这两个参数是常用的默认值,能取得不错的效果。
`joblib.dump()` 将训练好的模型保存为 `.pkl` 文件,以后加载时不需要重新训练,直接 `joblib.load()` 即可。
02. 从图片文件识别手写数字
2.1 准备一张手写数字图片
用手机在白纸上写一个数字,拍照后裁剪成正方形,保存为`test.png`。或者用画图工具画一个。
2.2 编写识别代码
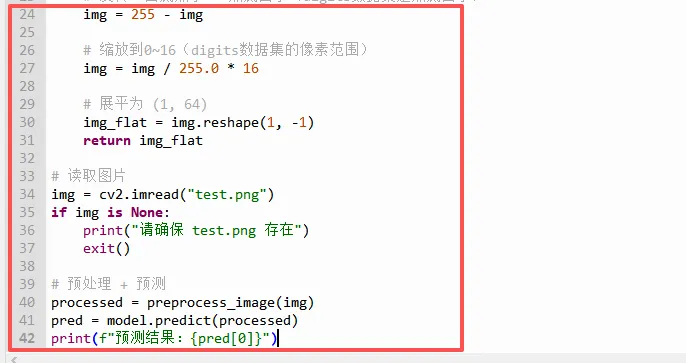

⭐重点讲解(逐段分析):
`joblib.load("digits_model.pkl")`:加载之前保存的模型文件。如果文件不存在或路径不对,会报 `FileNotFoundError`,所以要确保模型文件在代码同级目录下。
`def preprocess_image(img):` 这个函数是识别的核心,它把用户任意拍摄的图片转换成模型能理解的数字矩阵。
`if len(img.shape) == 3:` 判断图片是否彩色(三维数组)。
如果是,用 `cv2.cvtColor` 转为灰度图(二维),因为颜色信息对数字识别没有帮助,反而增加计算量。
`cv2.resize(img, (8, 8))`:将图片缩放到8×8像素。因为 `digits` 数据集中的图片就是8×8的,模型输入必须是64个像素。
如果原图太大或太小,缩放后数字可能会变形,但只要数字居中且清晰,模型通常能正确识别。
`cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)` 进行二值化:大于127的像素变为255(纯白),小于等于127的变为0(纯黑)。
这样可以去除背景噪点,突出数字形状。阈值 `127` 是经验值,如果图片偏暗或偏亮,可以适当调整。
`img = 255 - img`:反转颜色。因为我们平时拍照是白纸黑字(数字是黑色,背景白色),而 `digits` 数据集是黑底白字(数字白色,背景黑色)。如果不反转,模型会把背景当作数字,完全认不出来。
`img = img / 255.0 * 16`:将像素值从0~255缩放到0~16,因为 `digits` 数据集的像素值范围是0~16(浮点数)。这一步归一化后,像素值分布与训练时一致,模型预测更稳定。
`img.reshape(1, -1)`:将8×8的二维数组展平成一维数组(64个像素),并变成形状 `(1, 64)`,因为模型要求输入是“样本数 × 特征数”的形式,这里1张图片,64个特征。
`model.predict(processed)` 返回一个数组,如 `[5]`,表示预测的数字是5。`pred[0]` 取出这个值。
Tyree第一次运行时报错 `ValueError: Expected 2D array, got 1D array instead`,是因为他忘记 `reshape` 了。加上后就好了。
03. 从摄像头实时识别
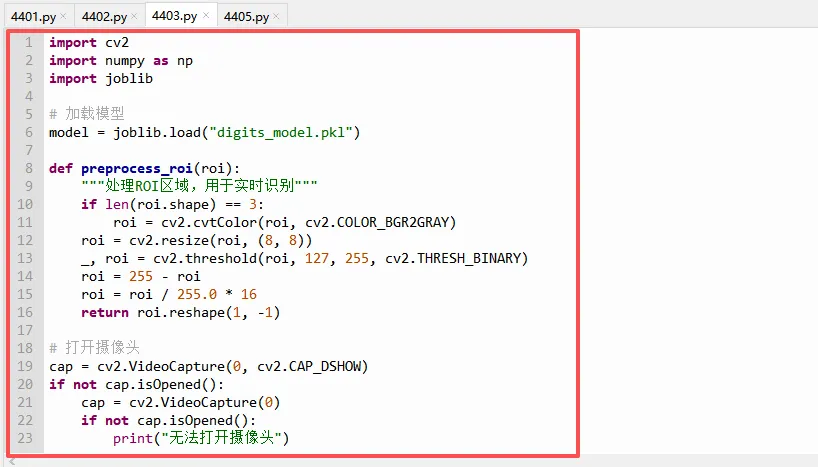
3.1 编写摄像头识别代码

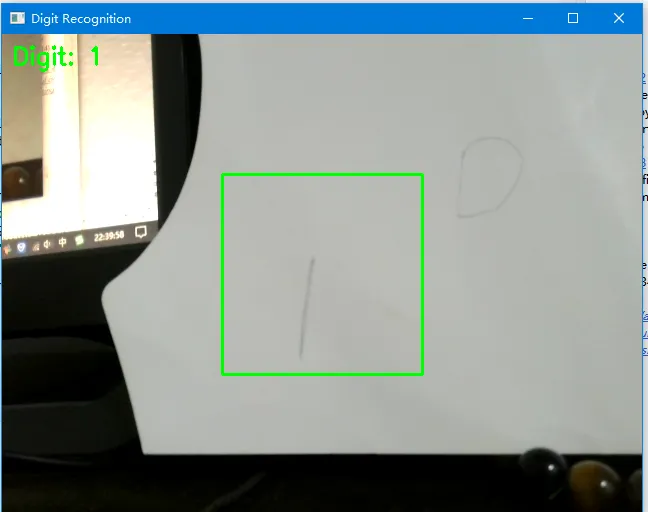
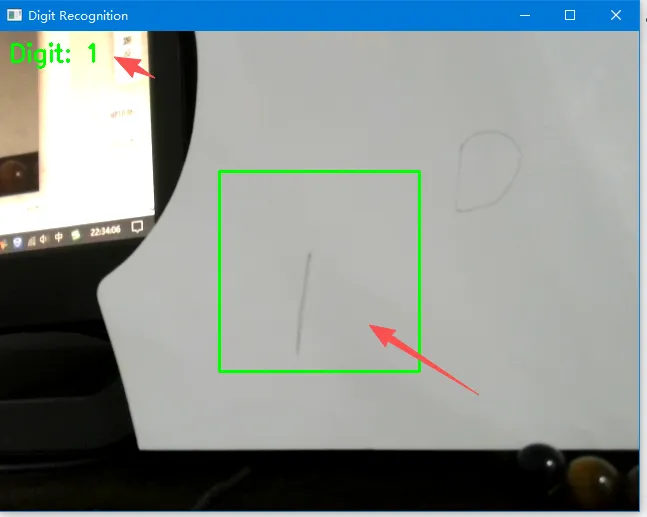
下面是运行后的画面:
⭐重点讲解(逐段分析):
`cv2.VideoCapture(0, cv2.CAP_DSHOW)` 打开摄像头,`0` 是设备编号(通常第一个摄像头)。
`cv2.CAP_DSHOW`
指定使用 DirectShow 后端(Windows下更稳定)。
如果打不开,可以去掉
`cv2.CAP_DSHOW` 试试。
`cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)` 设置采集分辨率,降低分辨率可以提高帧率。如果摄像头不支持,会静默失败。
ROI(感兴趣区域)用 `roi_size = 200`,表示取200×200像素的正方形区域,位于画面正中央(`roi_x` 和 `roi_y` 计算居中)。
用户把写有数字的纸放在画面中央,程序就能提取这个区域进行识别。
`roi = frame[roi_y:roi_y+roi_size, roi_x:roi_x+roi_size]` 是数组切片,提取矩形区域。
注意 OpenCV 中坐标顺序是 `(列, 行)`,但切片索引是 `[行, 列]`,所以先 `y` 后 `x`。
`preprocess_roi(roi)` 与图片处理的函数类似,将ROI区域转化为模型输入。
`model.predict(processed)[0]` 预测并取出结果。
`cv2.rectangle`
绘制绿色方框,`cv2.putText` 在左上角显示识别出的数字。
`cv2.waitKey(1) & 0xFF == ord('q')` 检测是否按下 `q` 键,按 `q` 退出循环。
Tyree第一次运行时发现识别率很低,他调整了二值化阈值从127降到100,并且让数字写得大一点、居中一些,识别率明显提升。
预处理参数需要根据实际图像调整,不能一成不变。
04. 图像预处理详解
灰度化,去掉颜色信息,数字识别只需要形状,颜色反而增加干扰
缩放8x8:匹配digits数据集尺寸,模型输入必须是64个像素
二值化:转为纯黑白,消除灰度噪声,突出数字轮廓
反转:白底黑字→黑底白字,digits数据集是黑底白字
归一化:像素值0~16,digits数据集像素范围是0~16
展平:8x8 → 64维向量,模型输入必须是一维向量
05. 完整代码
下面写把完整的代码整出来运行:

06. 今天学到了什么
sklearn模型保存与加载:
`joblib.dump()` 和 `joblib.load()` 比TensorFlow更轻量。
digits数据集规格:8x8像素,像素值0~16。
图像预处理流水线:灰度化、缩放、二值化、反转、归一化、展平。
实时摄像头识别:逐帧读取、提取ROI、预测、绘制结果。
Tyree最终用轻量级的方案成功实现了摄像头识别手写数字,不用TensorFlow,运行流畅,而且准确率也有90%以上。
他说原来不用TensorFlow也能做AI,还更快!
好了,今天课程就讲到这里。
下一课内容:语音识别入门——让电脑听懂你说的话,做一个简单的语音助手雏形。
————热门推荐————
少儿自学编程第40课:打包游戏成exe文件——把你用Python做的作品发给朋友
少儿自学编程第43课:用Python,MNIST手写数字识别——亲手训练一个AI
自学编程第7课:turtle画图入门(画一个正方形,五角形,螺旋形,三角形)
自学编程第2课:用input让电脑问你名字(做一个打招呼程序)
自学编程第一步:安装Python和Thonny(零基础图文教程)
(本系列教程每天更新,欢迎关注收藏)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux/Windows 双系统引导修复(下)——boot-repair 与手动修复进阶
- Python数据分析可视化连载01:开篇介绍 + 环境准备 + 能做什么
- 为什么Linux这么好用,那么普通人为啥不用呢?
- 【整整400集】别再走弯路!自学Python教程
- Linux 用户磁盘配额、资源限制与监控审计实战
- Linux环境下Wireshark抓包分析与OpsnSSH实战指南
- 某PHP电商平台代码审计
- 2026年星芒算法挑战赛(Python中学组)—预选赛—1~10题解题思路
- 双非本985研二,主攻机器人 Linux 应用开发,现阶段该重点提升什么?
- 我们是否还需要一个python的ggplot2?
