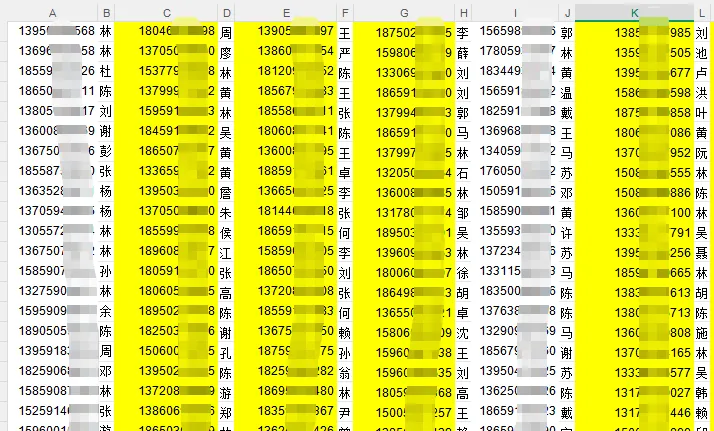
整天和excel打交道的朋友,一定有过面对大量数据时的那种崩溃心理,处理的方式步骤很简单,同样的操作需要重复N多次。一次又一次的重复不断挑战着内心的极限。近期就遇到同事的一个问题。excel表格里横向密密麻麻排列着多组数据,每两列为一组,一组有两列,一列为电话,一列为姓名。本以为是简单的复制、粘贴,可看到数据总量后发现,一共有44852个单元格需要处理,工作量瞬间陡增。如果手动复制粘贴并合并这4.48万数据,会是一件相当头疼的事情。今天就给大家分享一段极简代码,让你一键自动整理,结果秒出,效率刚刚的。import pandas as pdimport times_t = time.time()xlsx_path = r"E:\整理成两列.xlsx"df = pd.read_excel(xlsx_path,header=None)all_rows = []for col in range(0, df.shape[1], 2): group = df.iloc[:, [col, col + 1]].copy() group.columns = ["电话", "姓名"] group = group[["姓名", "电话"]] group = group.dropna(subset=["姓名", "电话"], how="all") all_rows.append(group)result = pd.concat(all_rows, ignore_index=True)result.to_excel(r"E:\合并结果.xlsx", index=False)print(f"排列完成,用时{time.time()-s_t:.2f}秒")
再看来代码解析:
1、读取数据。
df = pd.read_excel(xlsx_path,header=None)
header=None:表示没有标题行,适合第一行不是列名的情况。很多采集或导出的表格没有表头,这名代码可以完美兼容这种情形。for col in range(0, df.shape[1], 2):
这句的核心处理逻辑就是从第0列开始,2列为一组。这样做既不会错乱,也不会漏列,循环读取。group = df.iloc[:, [col, col + 1]].copy()
以dataframe的方式截取数据,df.iloc[:, [col, col + 1]]表示所有行和当前的两列。group.columns = ["电话", "姓名"]
原始表格没有列名,给新的数据添加列名。依次为电话、姓名。group = group[["姓名", "电话"]]
group = group.dropna(subset=["姓名", "电话"], how="all")
删除姓名、电话两列均为空白的行,how="all"表示自动删除整行空白的无效数据,让表格更干净,无需手动清理。result = pd.concat(all_rows, ignore_index=True)result.to_excel(r"E:\合并结果.xlsx", index=False)print(f"排列完成,用时{time.time()-s_t:.2f}秒")
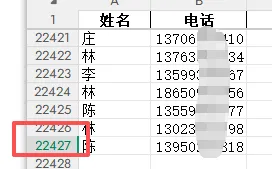
使用pd.concat()将所有分组数据纵向拼接成一张完整的两列表格;使用result.to_excel()将新的表格保存到指定路径,index=False表示不使用原索引。手动整理上万行数据,耗时又长,且容易串行漏数据,现在用Python,短短十几行数据,仅1秒多就处理完所有数据,数据还百分百准确,格式也统一规范。如果你也遇到类似的问题,请赶快收藏试试吧!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
