调度器全景图:从 CPU 占用率说起
Linux 调度子系统技术文档系列 · 第 1 篇
大半夜,你的告警群里突然弹出一条消息:某台生产服务器的 CPU 持续 100% 超过 5 分钟。你打开终端,敲下 top,赫然看到某个 PID 的进程占据了整颗核心。你心里一紧——这个进程会不会把其他服务"饿死"?如果这是一台 48 核机器,情况可能没那么糟糕;但如果它是跑在容器里的单核 Pod,其他所有线程可能已经被阻塞到崩溃。
这个时候,大部分运维工程师会先 kill -9 保命。但如果你是一名内核开发者,你自然会追问一个问题:调度器在做什么?它为什么会允许某个进程霸占 CPU? 换句话说,当我们看到 CPU 100% 这个数字时,内核究竟经历了怎样的决策链?
答案不在 top 命令里,而在 kernel/sched/ 下的几千行 C 代码中。
调度器是什么?它有哪些职责?
Linux 调度器是内核中负责"谁用 CPU、用多久"的决策模块。它的核心职责可以概括为以下几点:
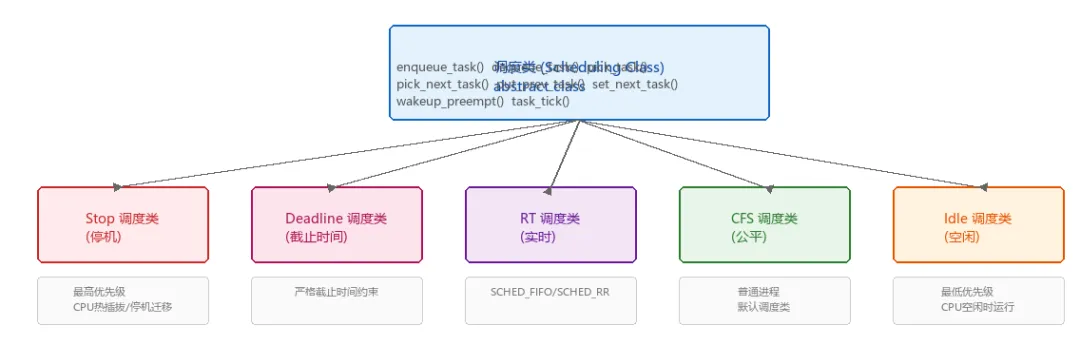
这些职责并不是由一段函数完成的。现代 Linux 调度器采用了一种分层调度类(Scheduling Class)的设计——每种调度策略被封装成一个独立的模块,按优先级串联在一起。
为什么要这样做?早期的 Linux 内核只有一个统一调度器,所有任务共用一套逻辑。随着实时任务、Deadline 任务、CFS 公平调度的需求涌入,单一调度器变成了巨大的 if-else 堆砌。2007 年,Ingo Molnar 在内核 2.6.23 中引入了 CFS,随后调度类分层架构逐渐成型。这种设计的本质是关注点分离:每一层只关心自己的任务类型,调度器主循环只需要"从上到下问一遍谁有活儿"。
调度类有哪些?它们的层次关系是什么?
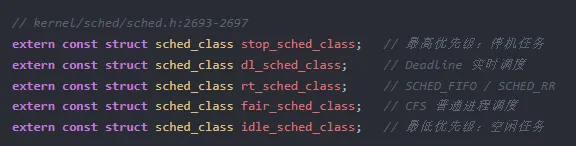
Linux 内核按优先级从高到低定义了五个调度类。优先级数字越小,级别越高——这不是随意约定的,它决定了调度器扫描的顺序:
- stop_sched_class(最高):用于 CPU 热插拔、停机迁移等关键操作
- dl_sched_class:Deadline 实时调度,为有严格截止时间约束的任务服务
- rt_sched_class:传统的 SCHED_FIFO / SCHED_RR 实时任务
- fair_sched_class
- idle_sched_class
每个调度类本质上是一个函数指针集合。内核通过 struct sched_class 将各种操作抽象成统一接口:
queue_mask:位掩码,标识该类在运行队列中是否有任务。stop=16、dl=8、rt=4、fair=2、idle=0enqueue_task / dequeue_taskpick_task / pick_next_taskput_prev_task / set_next_taskwakeup_preempttask_tick:周期性 tick 回调,用于时间片耗尽检测和统计
这里有一个关键的性能权衡:为什么 pick_task 和 pick_next_task 要分成两个接口?因为 pick_task 只需要"看看有没有",而 pick_next_task 需要完成 put_prev + set_next 的完整切换流程。在快路径(fast path)优化中,如果只需要判断某调度类是否可运行,直接调 pick_task 可以避免不必要的状态切换开销。
运行队列 struct rq 是什么?它有哪些核心成员?
每个 CPU 都拥有一个独立的运行队列 struct rq。这是调度器最重要的数据结构之一——所有的调度决策都围绕着它展开。
queue_mask:与 sched_class->queue_mask 对应,标记当前 CPU 上哪些调度类有可运行任务。调度器在选择下一个任务时,先看这个掩码来决定要不要跳过某一层cfs / rt / dl:三种主要调度类的子队列。CFS 使用红黑树维护虚拟运行时间(vruntime),RT 使用 FIFO 数组,DL 使用 Earliest Deadline First 算法curr(或 donor):指向当前正在 CPU 上运行的 task_struct 指针。调度器每次选择新任务后,会把这个指针指向新的任务clock:调度器的时间基准。每次 pick_next_task 都会先更新这个时钟,确保时间片计算准确
为什么要每个 CPU 一个独立队列?想象一下,如果所有 CPU 共享一个全局队列,每次入队、出队都需要加同一把锁。在 64 核系统上,64 个核同时竞争一把锁,调度延迟会直接飙升到毫秒级。独立队列将锁粒度缩小到单核级别,代价是负载均衡变得复杂——但这是一个值得的交换。
从 schedule() 到 pick_next_task():一次完整的调度流程
当用户态程序调用 sched_yield()、或者等待 I/O 进入睡眠、或者时间片耗尽被中断触发时,最终都会走到同一个入口:schedule()。
__schedule_loop 是一个 do-while 循环。它先禁止内核抢占,调用 __schedule() 执行核心调度逻辑,然后重新打开抢占。循环条件 need_resched() 检查当前任务是否被设置了重调度标志——如果有,说明在刚刚的调度过程中又有更高优先级的任务被唤醒了,需要再跑一轮。
真正的选择逻辑在 __schedule() 内部,它最终会调用 pick_next_task():
这段代码揭示了一个非常重要的设计:快路径 vs 慢路径。在生产环境中,99% 以上的调度场景只有 CFS 任务(普通进程),所以内核在入口处做了一个短路判断——如果当前运行队列全是 CFS 任务,直接调 pick_next_task_fair,跳过 stop/dl/rt 三层检查。这个优化将调度路径从多次函数调用缩减为一次直接跳转。
当存在实时任务时,才会走慢路径:for_each_active_class 从 stop_sched_class 开始逐层向下询问,一旦某一层返回了非空任务,就立刻返回。这就是为什么一个 SCHED_FIFO 任务可以完全"饿死"普通进程——只要它不主动让出 CPU,for_each_active_class 永远在 RT 层就返回了,根本轮不到 CFS 层。
现在回到文章开头的问题:为什么某个进程能霸占 CPU? 三种可能的根因:
- RT 任务死循环:SCHED_FIFO 任务没有阻塞点,调度器永远不会强制抢占
- CFS 权重失衡:一个 nice=-20 的进程获得的 CPU 时间是 nice=19 的 1024 倍,在极端情况下低优先级进程可能几乎得不到调度
- 自旋锁忙等待:用户态程序在自旋锁上忙等,虽然它是 CFS 任务,但调度器会按时间片分配 CPU,而忙等待会持续消耗整个时间片
要排查这类问题,top 只能告诉你"谁在跑",而 perf sched 或者 /proc/sched_debug 才能告诉你"为什么它一直在跑"。
架构哲学
Linux 调度器的分层架构可以概括为三句话:
- 高优先级必须能抢占低优先级——这通过
for_each_active_class 的从上到下扫描顺序保证 - 快路径要够快,慢路径要够全
- 每一层只管自己的事
这种设计的代价是代码量庞大,好处是每一种调度策略都可以独立演进。SchedExt(eBPF 扩展调度器)能在 6.12 内核中被合并,正是得益于调度类接口的开放性。
思考题
- 如果一个 SCHED_FIFO 实时任务在单核机器上执行死循环,会发生什么?系统还有救吗?
top 命令显示的 %CPU 列,和内核中的 rq->nr_running 有什么关系?- 在
__pick_next_task 的快路径中,为什么需要检查 !sched_class_above(prev->sched_class, &fair_sched_class)?这个条件不满足时会发生什么?
欢迎在评论区分享你的调试经验和思考。
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
