| 软件名称:Python |
| 软件语言:简体中文 | 计算机语言 |
| 系统要求:Windows10或更高, 32/64位操作系统 |
| 硬件要求:CPU@2.5+GHz ,RAM@4G或更高 |
百度网盘链接https://pan.baidu.com/s/1d-qdsMRtdyjtbZTLR7k2GQ?pwd=8888
夸克网盘链接https://pan.quark.cn/s/be3c37357e79
123云盘链接https://www.123912.com/s/j5j1jv-8ddTH
备用网盘总链接(上面链接失效用这个)https://www.kdocs.cn/l/crQ0aQ7xud0q?from=docs
|
『下载方法』将链接复制到浏览器网址栏,输入提取码,点击【下载】。 『解压密码』公众号菜单栏点击解压密码,获取软件密码后,如果遇到安装问题,我们会有专业人员免费解决安装问题,直到安装成功! 如果您觉得有用,可以推荐给自己的朋友、同学,或者给我们点个右下角的“在看”,您的支持是我们做下去的动力! |
1、将下好的安装包进行解压
2、解压后得到一个文件夹,打开它
3、双击打开如下图文件夹
4、以管理员身份运行
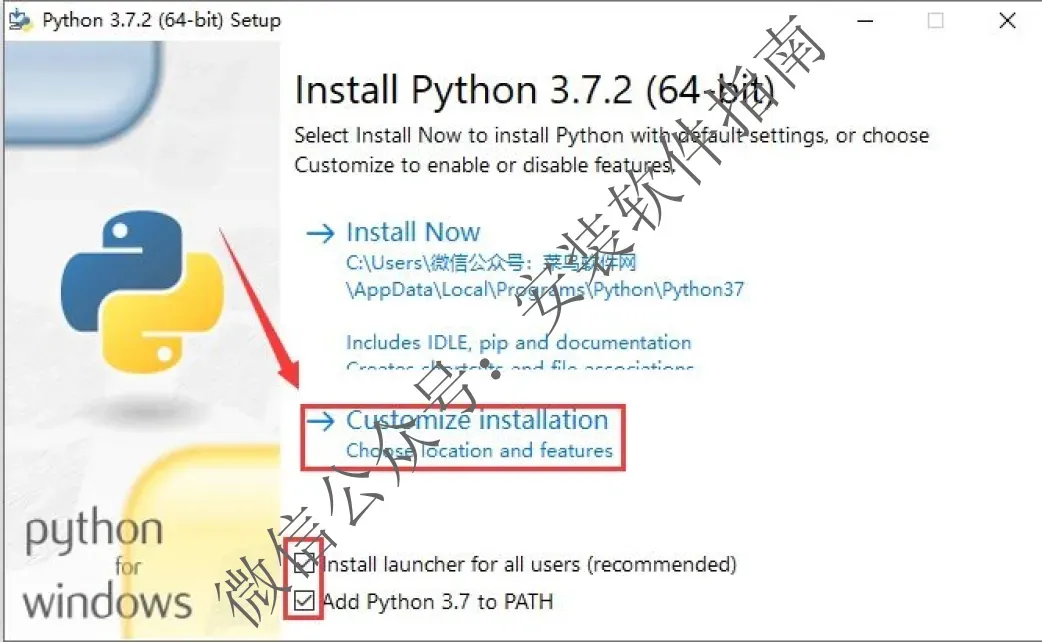
5、全部勾选,点【Customize installation】
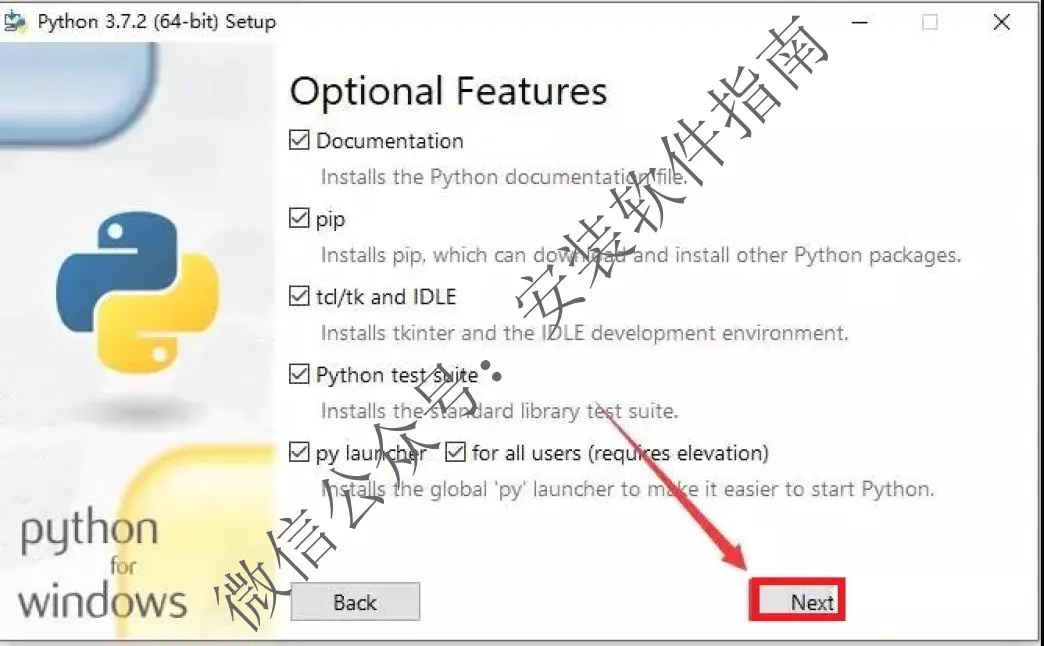
6、点Next
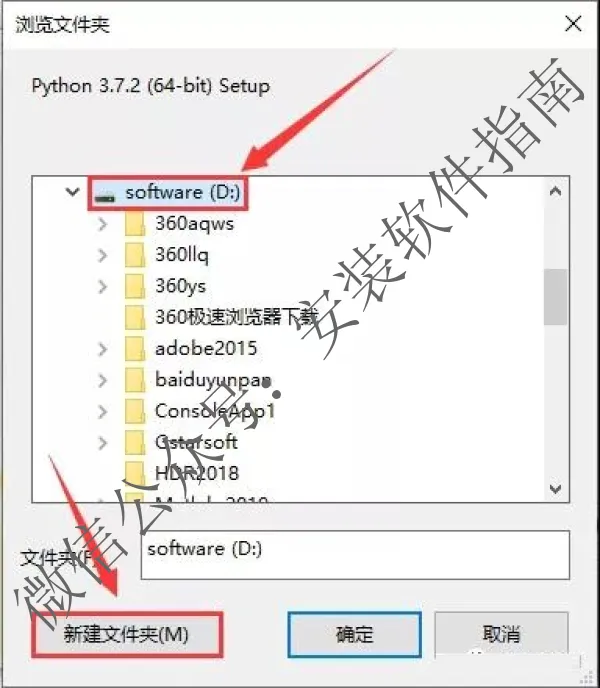
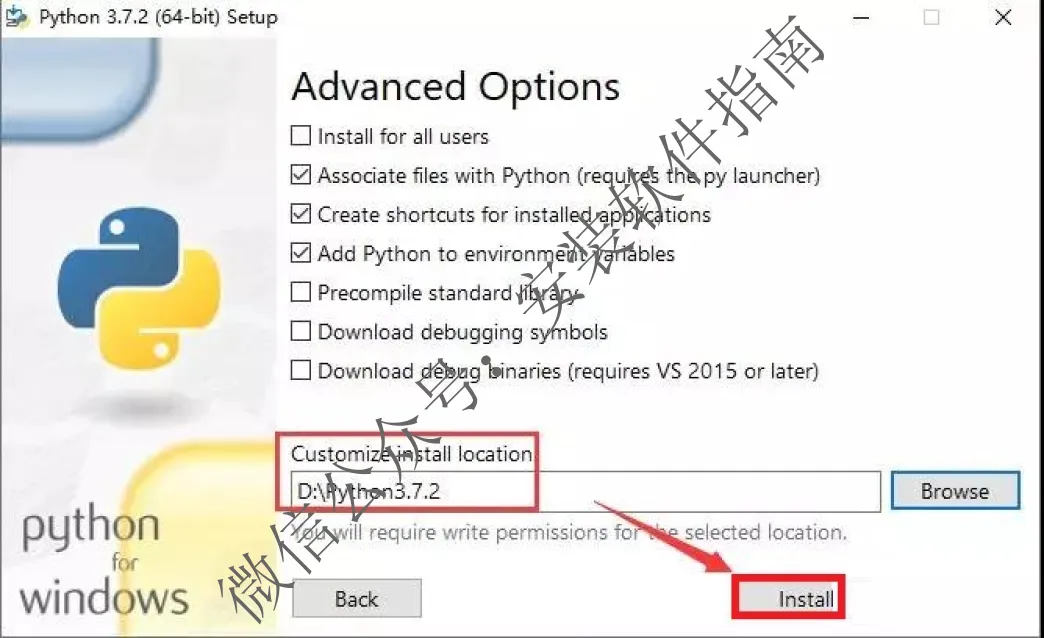
7、点Browse修改安装路径
8、先点D盘,然后点新建文件夹
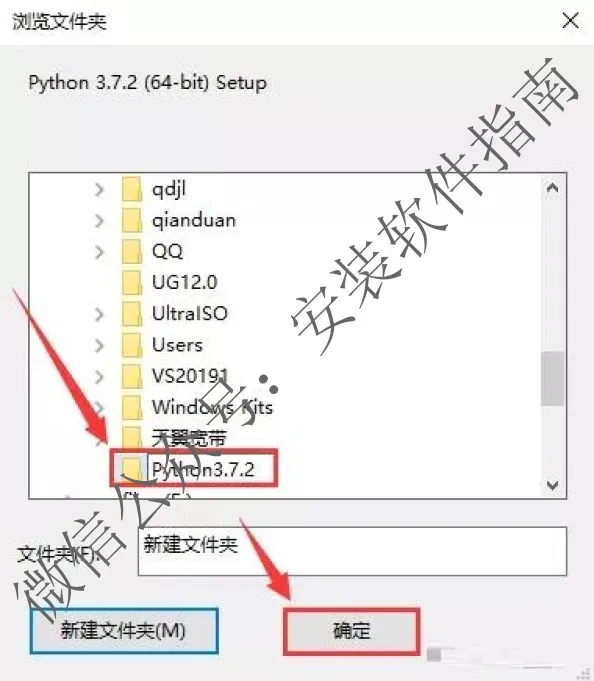
9、将文件夹命名为【Python3.7.2】,然后点【确定】
10、点Install
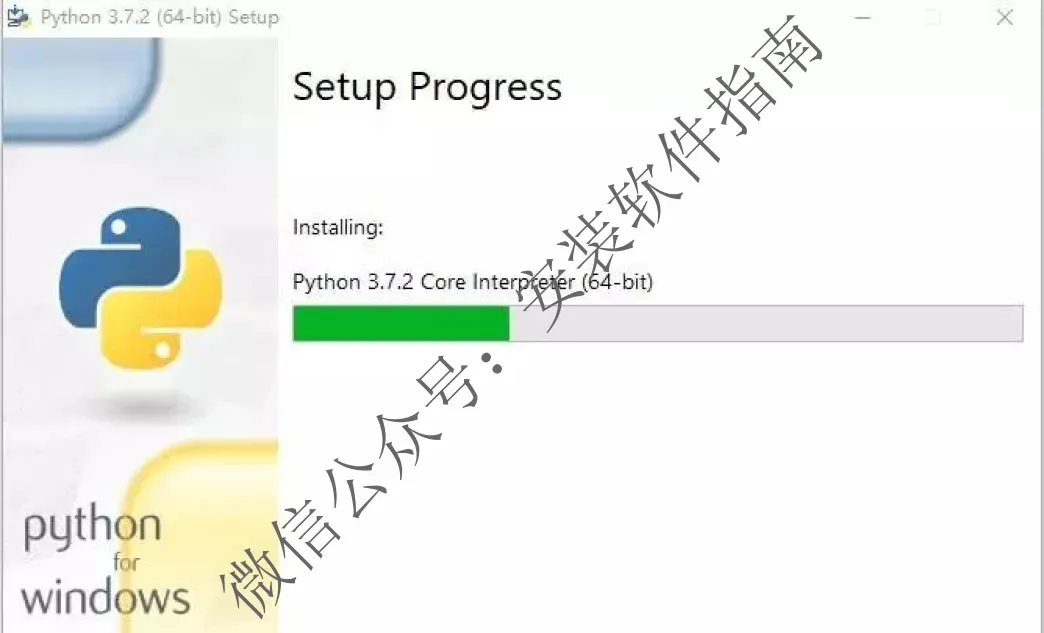
11、安装中请等待
12、安装成功点close
13、通过开始菜单,找到【IDLE】程序,将其拖到桌面产生快捷图标
14、打开如下图软件
15、OK
不管是学生做数据分析、爬虫课设,还是上班做自动化脚本、小型项目开发,Python都是必用的工具。上手门槛低、库资源多,不用纠结复杂语法,快速实现功能的优势确实很明显。
但长期敲代码就会发现,真正耗时间、卡进度的,从来不是写不出逻辑。大多是各种环境、路径、版本兼容的隐性问题,报错提示模棱两可,排查半天找不到根源,特别磨人。
最让人无奈的场景:代码本地完美运行,换台电脑直接全线报错。
之前帮朋友调试课设的数据分析脚本,我本地跑完全没问题,数据读取、可视化绘图、结果导出都正常。把完整项目文件发给他,他运行就一直报库导入错误、模块不存在。一开始以为是他没装依赖,逐个安装后还是报错。
折腾很久才查清问题根源。我本地是新版Python,他电脑装的是老旧版本,部分函数写法、库的调用方式已经迭代更新,新旧版本语法不互通。而且两人的第三方库版本不一致,很多适配新版的函数,旧版根本不支持。
这也是圈子里的常态,很多旧项目不敢随便升级Python版本,一旦升级,一堆旧代码直接报废,全部需要改适配,工作量巨大。
路径问题,绝对是新手重灾区。
太多人写代码习惯用中文路径、带空格的文件夹名称,本地运行偶尔能成功,但换环境、打包运行就直接崩。我之前做批量数据处理脚本,本地桌面文件夹带中文名称,读取本地csv文件完全正常,打包成exe之后,直接读取不到任何数据源,程序静默闪退,没有任何报错弹窗。
排查了整整一下午,才确定是中文路径编码冲突导致的。从那之后,我所有项目、素材、文件路径,一律纯英文数字命名,文件夹层级尽量简短,能避开九成的路径编码报错。
还有个很隐蔽的坑:缓存残留导致的莫名报错。
很多人改完代码直接运行,不清理pyc缓存文件。有时候明明改了函数逻辑、修正了参数,运行结果还是没变,甚至持续报旧代码的错误。新手会反复修改代码,越改越乱,殊不知是旧缓存文件在干扰程序运行。
现在我每次修改完核心代码,都会手动清理缓存文件夹,避免旧数据残留影响运行结果,省去很多无效调试时间。
硬件配置的短板,处理大批量数据时格外明显。
简单的爬虫、小体量数据分析,普通办公本完全够用。但一旦处理上万条数据集、批量绘图、大规模数据清洗,电脑内存直接拉满,代码运行卡顿严重,执行进度极其缓慢。
我用常规16G内存笔记本跑大数据循环脚本,多次出现程序卡死、内核崩溃的情况,之前写好的循环逻辑没问题,纯粹是硬件内存不足,导致程序强制终止,之前的运算进度全部白费。
另外虚拟环境乱用也很容易翻车。
很多新手不分项目、不分版本,全部装在全局环境里,久而久之库版本互相冲突。新脚本需要新版库,旧项目依赖旧版库,互相拉扯,最后导致整个环境崩盘,所有代码都无法正常运行,只能重装环境,费时费力。
现在我每个独立项目都会单独建虚拟环境,隔离依赖包,互不干扰,彻底杜绝版本冲突的问题。
Python的优势就是灵活高效,快速落地各种小功能、小项目。但它的隐性问题真的很多,环境、路径、缓存、版本,随便一个细节出错,就能卡住一整天。
比起纠结语法,养好规范的使用习惯,反而能省下最多的调试时间。
最近打算给电脑加根内存,大批量数据运算频繁卡顿,真的太耽误效率了。









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
