批量基因ID转换python版
- 2026-06-28 03:37:48
批量基因ID转换python版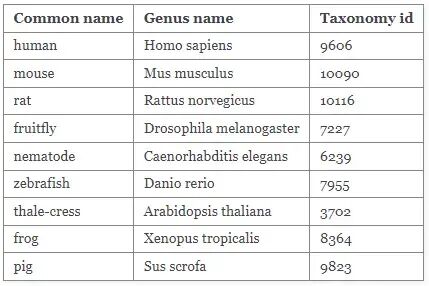
往期回顾 
scanpro | 单细胞数据差异组分分析 
cellxgene远程或本地探索单细胞数据 
scanpy框架用来分析bulkRNA就是好用 
AICelltype | 79个当中表现最佳的大模型用于细 胞类型注释 
claw4science | 大模型分析数据的技能库 

不得不承认基因的ID种类确实很多,好在常用的就那么几个。做分析基本都会遇到基因ID转换的需求,能用来做这个的事资源还是比较多的。其中,NCBI作为生命科学领域的数据库,信息那是相当的全面,做个基因ID转换那肯定没问题,而且数据库也提供了相应的API方便调用,也有现在的软件可以用,如biopython。但这个方式在基因数量多、转换多个ID时不是很方便。此时,biomart和mygene来替代,这两个软件分别是ensembl、MyGene.info数据库API的访问软件,用这两个软件做基因ID转换真的很便捷了。
biomart使用的原则整体上遵循以下四个步骤:Datasets -> Filters (filtering and inputs) -> Attributes (desired output) -> Results
import biomartgenes_list = ['JCHAIN', 'IGJ', 'IGHG1', 'MZB1', 'SDC1', 'CD79A', 'HSP90B1', 'FNDC3B', 'PRDM1', 'IGKC']server = biomart.BiomartServer("http://www.ensembl.org/biomart")ensembl = server.datasets['hsapiens_gene_ensembl']res = ensembl.search({'filters': {'external_gene_name': genes_list}, 'attributes': ['external_gene_name', 'ensembl_gene_id']})genes_conv_df = pd.read_csv(res.url, sep='\t', names=["Gene name", "Gene stable ID"]).dropna()genes_conv_df.head() Gene name Gene stable ID0 IGHG1 ENSG000002776331 IGKC ENSG000002115922 IGHG1 ENSG000002118963 MZB1 ENSG000001704764 PRDM1 ENSG00000057657external_gene_name指Gene Name,即symbol ID。如果想知道哪些字段可用来查询,可以直接查看ensembl对象的filters属性。类似的方式可以查看哪些字段可用来过滤。
上面biomart的转换过程已经挺简单了,相比较而言mygene使用起来更容易:
import mygenegenes = ['SDC1', 'CD79A', 'HSP90B1', 'FNDC3B', 'PRDM1']mg = mygene.MyGeneInfo()res = mg.querymany(genes, scopes="symbol", fields="symbol,entrezgene,ensembl.gene,uniprot.Swiss-Prot", species="human", as_dataframe=True)res _id _score entrezgene symbol ensembl.gene uniprot.Swiss-ProtSDC1 6382 17.965767 6382 SDC1 ENSG00000115884 P18827CD79A 973 17.849460 973 CD79A ENSG00000105369 P11912HSP90B1 7184 17.567043 7184 HSP90B1 ENSG00000166598 P14625FNDC3B 64778 18.165148 64778 FNDC3B ENSG00000075420 Q53EP0PRDM1 639 18.178675 639 PRDM1 ENSG00000057657 O75626以下是MyGene.info数据库支持的物种:
全部可用的字段见网页: https://docs.mygene.info/en/latest/doc/data.html#available-fields
biomart和mygene分别有对应的R包,习惯用R语言的人也可以很快乐地用起来。
--------- The End ---------
基因组
|
转录组
|
表观组
|
单细胞
寻找灵魂的工具人
长按扫码加关注
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

