苦猿的大模型日记 · Day01 · 写给大模型入门者的地基课-帮普通人把AI学进简历系列前言:别让 Python 成为你的"第一道墙"
后台收到一条私信,是个工作三年的前端同学发的。
他说:「我想转大模型,买了课、配了环境,结果第一节课老师甩过来一段 Python 代码,我连 if __name__ == "__main__" 都看不懂。」
说实话,这种焦虑我太熟悉了。
当年我从二本毕业,进的第一家公司写 Java。第一次被叫去改一段 Python 脚本,我盯着 for x in data: 发了五分钟呆——这玩意儿为啥没有花括号?
后来一路摸爬滚打到 AI 这行,我才发现一个反常识的事实:
你以为 AI 工程师天天在调算法、看论文,其实他们 80% 时间在写 Python 基础代码。
深夜,密密麻麻的教程网页,谁都懵过
那 Python 这门课,到底要学多深才能上手 AI?
我的答案是:不用全学,7 块地基打牢就行。
今天这篇文章,我把这 7 块一次性讲清楚。每一块都配真实 AI 场景的代码,你能直接抄走用。
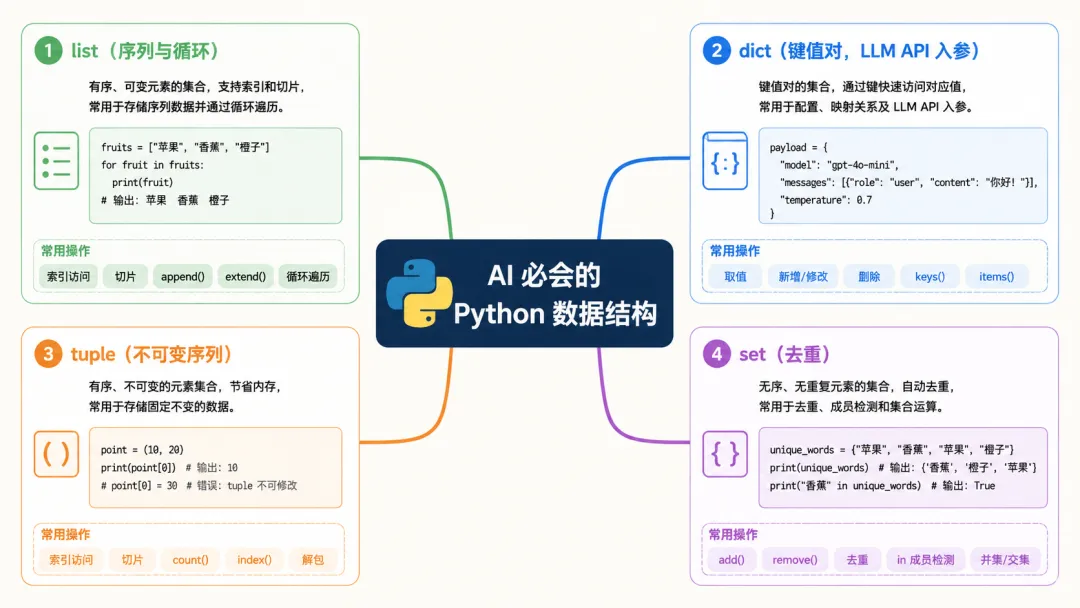
PART 01:数据结构——AI 工程师的"语言地基"
先说一个让我后知后觉的事。
我入行前半年,把整个《Python Cookbook》啃了一遍,装饰器、元类、协程……啥都学。
结果上手做项目,发现真正每天在用的就那 4 个:
就这 4 个,盖起了 90% 的 AI 项目代码。
dict 是 AI 工程师的"母语"
你看一眼 OpenAI 的 Chat Completions API 是怎么调的:
from openai import OpenAIclient = OpenAI(api_key="sk-xxx")response = client.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": "你是一个 Python 老师"}, {"role": "user", "content": "什么是 list comprehension?"} ], temperature=0.7)print(response.choices[0].message.content)
看清楚没?入参是一个大 dict(虽然是关键字参数形式),里面嵌套着 list,list 里又装着 dict。
LLM 的世界,本质就是 dict 套 dict 套 list。
list comprehension:批量处理的瑞士军刀
AI 项目里你天天要做的事:把一堆文本批量塞给模型。
不要写 for 循环 append,太慢太丑。学会这一行:
prompts = [f"总结这段话:{text}" for text in documents]
等价于这个又长又丑的版本:
prompts = []for text in documents: prompts.append(f"总结这段话:{text}")
功能一样,但前者是 Python 工程师的写法,后者是新手的写法。
AI 必会的 Python 数据结构脑图
set:去重一句话搞定
做 RAG(检索增强生成)的时候,你拿到一堆候选文档,里面常有重复。怎么办?
unique_docs = list(set(documents))
一行搞定。这就是 set 的价值。
PART 02:函数与模块化——别再写"面条代码"了
我见过一个同事,把整个 AI 客服后端写在了一个 1400 行的脚本里。
没有函数,全是 if-else 套 if-else。
后来他要加一个"按用户分级调用不同模型"的功能,改了三天,把生产环境搞挂了两次。
从那以后我立了个规矩:超过 50 行的脚本,必须拆函数。
默认参数 + **kwargs:AI 函数的标准长相
封装一个调 LLM 的函数,标配写法长这样:
def ask_llm( prompt: str, system: str = "你是一个助手", model: str = "gpt-4o-mini", temperature: float = 0.7, **kwargs): """调一次 LLM,返回文本结果。 kwargs 用来透传 API 的可选参数,比如 top_p、max_tokens、stream。 """ client = OpenAI() response = client.chat.completions.create( model=model, messages=[ {"role": "system", "content": system}, {"role": "user", "content": prompt}, ], temperature=temperature, **kwargs # ← 透传 top_p、max_tokens 等 ) return response.choices[0].message.content
注意这两个细节:
- 默认参数:调用方不需要每次都写
model="gpt-4o-mini",只有换模型时才传 **kwargs:API 可选参数一大堆(top_p、max_tokens、stream、stop...),用 **kwargs 全透传,函数永远不用改
调用起来是这样的:
# 简单调用print(ask_llm("你好"))# 高级调用,透传 max_tokens 和 stopprint(ask_llm( "写一首关于 Python 的诗", max_tokens=200, stop=["。"]))
这就是 Python 函数的精髓——封装一次,无限复用。
面条代码,谁写谁哭
lambda:一行小函数
map、filter、sorted 配 lambda,处理数据时一气呵成:
# 按文本长度排序documents = ["短文本", "这是一个比较长的文本内容", "中等"]documents.sort(key=lambda x: len(x))
不用单独写个 def get_len(x): return len(x),省下来的代码就是你的命。
PART 03:文件 IO 与异常处理——给 AI 应用配"安全带"
PART 01、02 讲的是"怎么写得动",PART 03 讲的是"怎么活得久"。
AI 项目 90% 的事故,都和这两件事有关:
- API key 写在代码里,被同事推到了 GitHub 公开仓库
- LLM 调用没加异常处理,限流时整个服务雪崩
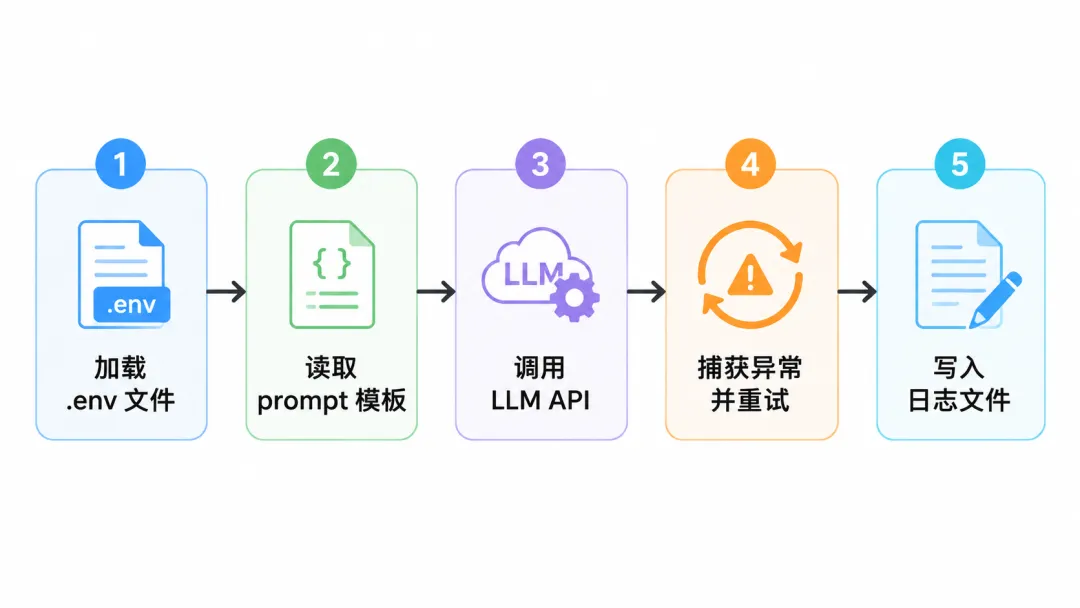
下面这套"安全带",每个 AI 工程师都要会系。
with open:安全读写文件
不要这样写:
f = open("prompt.txt", "r", encoding="utf-8")content = f.read()f.close() # ← 万一中间报错,这行不会执行,文件句柄泄漏
要这样写:
with open("prompt.txt", "r", encoding="utf-8") as f: content = f.read()# with 块结束自动 close,哪怕中间报错也会关
with 就是 Python 给你的"自动门"——进得去就一定出得来。
try/except:兜住所有 LLM 调用
调 LLM 必须包异常,不然网络一抖整个程序崩:
from openai import OpenAI, RateLimitError, APITimeoutErrorclient = OpenAI()def safe_ask_llm(prompt: str, retries: int = 3): for i in range(retries): try: return ask_llm(prompt) except RateLimitError: print(f"限流了,第 {i+1} 次重试...") time.sleep(2 ** i) # 指数退避 except APITimeoutError: print(f"超时了,第 {i+1} 次重试...") except Exception as e: print(f"未知错误:{e}") raise raise RuntimeError(f"重试 {retries} 次后仍失败")
这段代码我直接复制粘贴过 50 次,每一个 AI 项目里都有它的影子。
.env:密钥管理的行业标准
把 API key 写在 .py 里 = 等着上热搜。
正确姿势:
# .env 文件(注意:必须加到 .gitignore)OPENAI_API_KEY=sk-xxxDASHSCOPE_API_KEY=sk-yyy
# config.pyfrom dotenv import load_dotenvload_dotenv() # 加载 .envimport osapi_key = os.environ["OPENAI_API_KEY"]
记住这条铁律:代码可以开源,密钥永远不入仓库。
LLM 调用安全带:加载 .env → 读 prompt → 调 API → 异常重试 → 写日志
PART 04:生成器 yield——LLM 流式输出的底层引擎
你用 ChatGPT 的时候有没有注意一个细节——
回答不是一次性弹出来的,而是一个字一个字"吐"出来的。
这个效果,在 Python 这边有个专门的名字:流式输出(streaming)。
底层支撑它的,就是 yield 这个关键字。
yield vs return:一个是"边算边吐",一个是"算完再给"
先看一个最简单的对比:
# return 版本:一次性返回所有结果def get_numbers_return(): return [1, 2, 3, 4, 5]# yield 版本:一个一个吐def get_numbers_yield(): yield 1 yield 2 yield 3 yield 4 yield 5
调用方式看起来一样,但内存占用天差地别:
# return 版本:内存里要同时存 1 亿个数nums = [i for i in range(100_000_000)]# yield 版本:内存里永远只有 1 个数def gen(): for i in range(100_000_000): yield i
yield 就是 Python 给你的"流式管道"——边生产边消费,内存零压力。
真实场景:流式调用 LLM
OpenAI 的 API 支持 stream=True,返回值就是一个生成器。你 yield 出来,前端就能逐字渲染:
def stream_llm(prompt: str): """流式输出 LLM 响应,逐 token yield""" response = client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": prompt}], stream=True # ← 关键 ) for chunk in response: content = chunk.choices[0].delta.content if content: yield content# 用起来:用户看着字一个一个冒出来for token in stream_llm("用三句话解释什么是 Transformer"): print(token, end="", flush=True)
这就是 ChatGPT 那种打字机效果的真相。不会 yield,你写不出 LLM 前端。
ChatGPT 那种逐字打字效果,底层就是 yield + stream=True
顺带:大文件别再 read() 了
处理几个 G 的训练数据,千万别 f.read()——会爆内存。
# 错误:一次性读完,几 G 数据进内存content = open("huge_dataset.jsonl").read()# 正确:一行一行 yield,内存恒定def read_lines(path): with open(path, "r", encoding="utf-8") as f: for line in f: yield line.strip()for line in read_lines("huge_dataset.jsonl"): process(line) # 内存里永远只有 1 行
AI 工程师处理大数据的第一守则:能流式就别全量。
PART 05:异步 async/await——批量并发调 LLM 的加速器
讲完 yield,再讲一个性能怪兽:异步。
我做过一个真实项目:要给 1000 条用户评论批量调用 LLM 做情感分析。
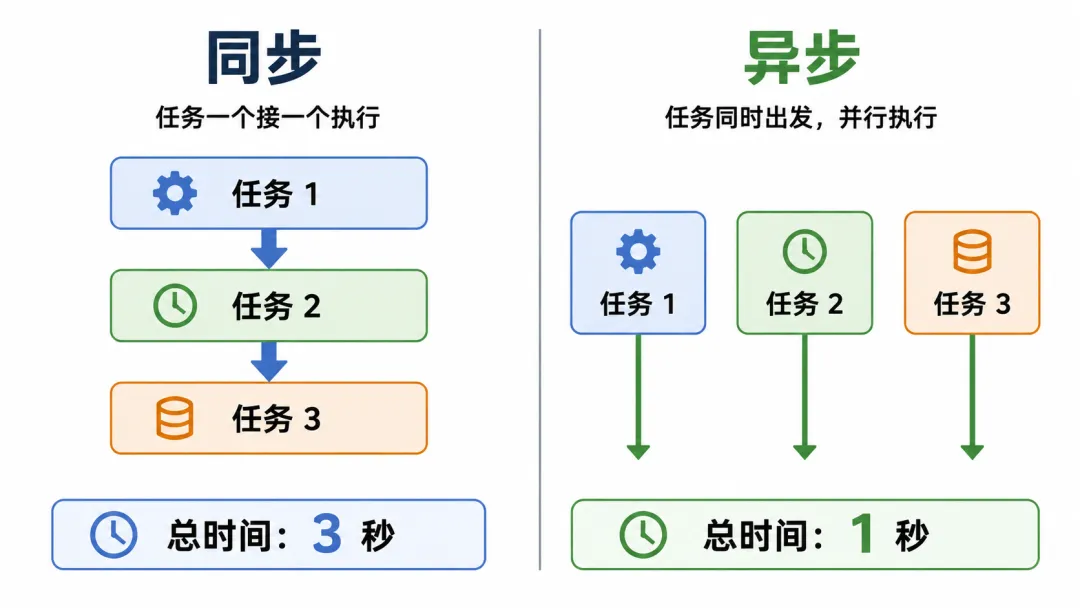
第一次我写的同步代码,1000 条跑了 47 分钟。
后来改成异步,4 分钟跑完。10 倍加速。
同步 vs 异步:一张图看懂
- 同步:一个一个排队,前一个不回来后一个不动
- 异步:一起发出去,谁先回来谁先处理
# 同步:串行调用,3 次 = 3 秒def sync_call(): results = [] for p in prompts: results.append(ask_llm(p)) # 每次 1 秒 return results# 总耗时:3 秒
# 异步:并行调用,3 次 ≈ 1 秒import asynciofrom openai import AsyncOpenAIasync_client = AsyncOpenAI()async def ask_one_async(prompt): resp = await async_client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": prompt}] ) return resp.choices[0].message.contentasync def batch_ask(prompts): """批量并发,速度 5-10 倍""" tasks = [ask_one_async(p) for p in prompts] return await asyncio.gather(*tasks)# 用起来results = asyncio.run(batch_ask(prompts))# 总耗时:约 1 秒
关键就三个词:async def、await、asyncio.gather。
记住这个组合,碰到任何"批量调 API"的场景,套上去就完事。
同步串行 vs 异步并行:10 倍性能差距就来自这一步
什么时候用异步?
不是所有场景都该用异步。只有"等 IO"的场景才值:
LLM 项目里 90% 都是网络等待,所以异步是必修课。
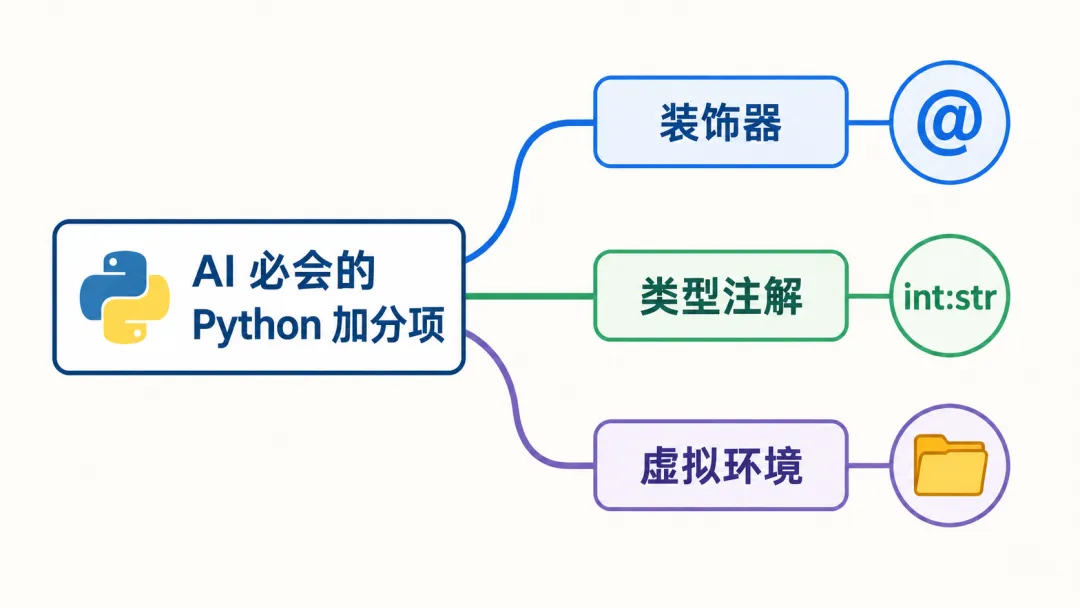
PART 06:装饰器 + 类型注解 + 虚拟环境——三个"加分项"变"必会项"
最后这一 PART 讲三件小事,单独看都不大,但少一个你都玩不转现代 AI 项目。
装饰器 @:框架里的"语法糖"
你打开 FastAPI、Pydantic、LangChain 的代码,到处都是 @:
@app.get("/chat") # FastAPI 路由装饰器@retry(times=3) # 自定义重试装饰器@functools.cache # 自动缓存def some_func(): ...
装饰器的本质:用一个函数包装另一个函数,加点料再返回。
实战中最常用的:自己写一个重试装饰器,给所有 LLM 调用套上:
import functoolsimport timedef retry(times=3, delay=2): """重试装饰器,AI 调用必备""" def decorator(func): @functools.wraps(func) def wrapper(*args, **kwargs): last_err = None for i in range(times): try: return func(*args, **kwargs) except Exception as e: last_err = e print(f"第 {i+1} 次失败:{e},{delay}秒后重试") time.sleep(delay) raise RuntimeError(f"重试 {times} 次仍失败:{last_err}") return wrapper return decorator# 用起来,所有调 LLM 的函数自动重试@retry(times=3, delay=2)def ask_llm(prompt): return client.chat.completions.create(...)
学会装饰器,你的代码复用率直接翻倍。
类型注解:现代 Python 的"通行证"
Python 不是强类型语言,但2024 年之后的 AI 项目,没 type hint 等于裸奔。
为什么?因为 Pydantic 和 LangChain 强依赖类型注解:
from pydantic import BaseModelclass Message(BaseModel): role: str content: strclass ChatRequest(BaseModel): model: str = "gpt-4o-mini" messages: list[Message] temperature: float = 0.7# Pydantic 自动校验类型,传错直接报错req = ChatRequest( model="gpt-4o-mini", messages=[{"role": "user", "content": "你好"}], temperature=0.7)
类型注解的好处:
- Pydantic / FastAPI 自动校验入参
记住这个口诀:函数签名必加类型,变量可加可不加。
虚拟环境 venv:每个 AI 项目的"第一步"
最后讲一个最朴素但最关键的——虚拟环境。
不创建虚拟环境会怎样?你的全局 Python 会被各种包污染,今天装 openai 0.27,明天装 openai 1.0,项目之间互相打架。
正确姿势,每个新项目都跑一遍:
# 1. 创建虚拟环境(在项目根目录)python -m venv .venv# 2. 激活(Windows).venv\Scripts\activate# 2. 激活(Mac/Linux)source .venv/bin/activate# 3. 装依赖pip install openai python-dotenv pydantic# 4. 导出依赖清单(提交到 git)pip freeze > requirements.txt# 5. 别人 clone 项目后,一键复现环境pip install -r requirements.txt
这套流程,是 AI 工程师的"开机仪式"。每个项目都从这 5 步开始。
装饰器、类型注解、虚拟环境:三件"加分项"早已变成"必会项"
结尾:地基不牢,地动山摇
写到这里,4 块地基讲完了。
回头看,其实就这么点东西:
没有任何花哨的东西。
但就是这 4 块,撑起了 ChatGPT 客户端、RAG 系统、Agent 框架、模型微调脚本——所有你能想到的 AI 应用,底层都是这些语法。
工具会变,框架会换,但 Python 这套底层语法,十年都不会过时。
把地基打牢,上面盖什么楼都稳。
别再纠结"我是不是该再学一门语言"了——先把 Python 这门用透。
想听你说:
你学 Python 时被哪个概念卡得最久?是装饰器、*args/**kwargs、还是那个看一百遍还是懵的 if __name__ == "__main__"?
评论区聊聊,下一篇我挑最多人问的那个,单独拆一篇讲透。
关注「苦猿的大模型日记」,下一篇:Day02 | PyTorch 入门:从装环境到跑通第一个模型
— END —苦猿 · 帮普通人把 AI 学进简历



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
