Python入门课| 11. 简单机器学习入门
- 2026-06-29 22:02:01

11. 简单机器学习入门


《Python入门课》是作为生信小白入门重要的课程之一,学好python,是单细胞+空间转录组,Python全流程实战教学的基础。
B站同步播出:https://b23.tv/c8LWhpG
简单机器学习入门
在Python入门课| 01. 绪论中,我们给大家介绍了python的特点与用途,同时Python入门课| 02. python下载与安装手把手带领大家在不同系统中安装和下载Python;在Python入门课| 03. 变量与数据类型中了解了变量与数据类型,主要是整数、浮点数、字符串和布尔值;在Python入门课| 04. 类型转换中,python实现数据类型相互转换;在Python入门课| 05. 数据结构中掌握了python的数据结构,主要是列表与元组、字典、集合、数组、Series、数据框DataFrame、AnnData;之后学习了Python入门课| 06. 运算符和表达式,主要包含:算法运算符、比较运算符、逻辑运算符、位运算符、赋值运算符;在Python入门课| 07. 语法与语句中学习了python常见语句:条件语句、循环语句、函数定语语句;在Python入门课| 08. 数据的读取与保存中学习了在python中进行数据的读取与保存;在Python入门课| 09. 模块与包中我们学习了python中的模块与包;在Python入门课| 10. 基于Matplotlib的基础可视化中学习了绘制2D图表:折线图、柱状图、散点图、直方图等可视化图;接下来,我们学习机器学习的流程:导入库和加载数据→数据集划分和特征缩放→模型训练和评估,最终实现得到可视化结果。


图文内容


1. 简单机器学习入门
💡 机器学习简介
机器学习 (Machine Learning, ML) 是一门多学科交叉的领域,它致力于研究如何让计算机系统通过数据而非明确编程来学习和改进性能。
简单来说,机器学习就是:
允许计算机在没有被明确告知如何执行任务的情况下,通过对数据模式的识别和提取,自动完成任务。
核心概念:
训练 (Training): 机器通过分析大量已知数据(即训练数据)来建立一个数学模型,这个过程就是“学习”。
模型 (Model): 学习过程的输出,它可以是一个数学公式、一组规则或一个复杂的神经网络结构。模型用于从新数据中进行预测或决策。
预测 (Prediction): 使用训练好的模型对未知数据进行推断。
机器学习的主要类型
| 监督学习 (Supervised Learning) | 分类 | |
| 无监督学习 (Unsupervised Learning) | 聚类 | |
| 强化学习 (Reinforcement Learning) |
🤖 使用 Scikit-learn 进行分类:鸢尾花数据集 (KNN)
Scikit-learn (Sklearn) 是一个开源的机器学习库,建立在 NumPy、SciPy 和 Matplotlib 这些科学计算库之上,提供了简单高效的数据挖掘和数据分析工具。
以下演示了一个标准的分类任务流程,使用经典的鸢尾花 (Iris) 数据集和 K 最近邻 (KNN) 算法。
k 近邻 (KNN) 是一种非参数的监督学习方法,它通过计算一个数据点与训练集中所有点的距离,然后将其分配给距离最近的 k 个数据点中出现频率最高的类别(对于分类问题)或平均值(对于回归问题)。
k 近邻 (KNN) 通过度量距离来寻找最相似的 k 个训练样本,然后用它们多数(分类)或平均(回归)的属性来决定新样本的属性。
📜 机器学习流程 整个流程分为七个步骤:
导入库
加载数据
数据集划分 (训练集/测试集)
特征缩放(标准化)
选择模型并训练
评估模型
可视化结果(可选)
导入库和加载数据
import numpy as np # 数据处理库import pandas as pd # 数据处理库import matplotlib.pyplot as plt # 绘制图库from sklearn.datasets import load_iris # 加载鸢尾花数据集from sklearn.model_selection import train_test_split # 数据集划分from sklearn.preprocessing import StandardScaler # 数据标准化from sklearn.neighbors import KNeighborsClassifier # KNN分类器from sklearn.metrics import accuracy_score # 准确率评估# 加载鸢尾花数据集iris = load_iris()# 将数据转化为 pandas DataFrameX = pd.DataFrame(iris.data, columns=iris.feature_names) # 特征数据 (X)y = pd.Series(iris.target) # 标签数据 (y)# 数据预览print(X)
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 .. ... ... ... ... 145 6.7 3.0 5.2 2.3 146 6.3 2.5 5.0 1.9 147 6.5 3.0 5.2 2.0 148 6.2 3.4 5.4 2.3 149 5.9 3.0 5.1 1.8 [150 rows x 4 columns]print(y)0 0 1 0 2 0 3 0 4 0 .. 145 2 146 2 147 2 148 2 149 2 Length: 150, dtype: int64数据集划分和特征缩放
将数据划分为训练集和测试集(80% 训练,20% 测试),然后对特征进行标准化处理,使其均值为 0,标准差为 1。
# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 标准化特征scaler = StandardScaler()# 在训练集上 fit_transformX_train = scaler.fit_transform(X_train)# 在测试集上 transform (使用训练集拟合的参数)X_test = scaler.transform(X_test)print("\n--- 特征标准化完成 ---")print(f"训练集特征形状: {X_train.shape}")print(f"测试集特征形状: {X_test.shape}")
--- 特征标准化完成 --- 训练集特征形状: (120, 4) 测试集特征形状: (30, 4)模型训练和评估
# 创建 KNN 分类器并训练knn = KNeighborsClassifier(n_neighbors=3)# 训练模型knn.fit(X_train, y_train)# 评估模型# 预测测试集y_pred = knn.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print("\n--- 模型评估结果 ---")print(f'模型准确率: {accuracy:.2f}')
--- 模型评估结果 --- 模型准确率: 1.00可视化结果
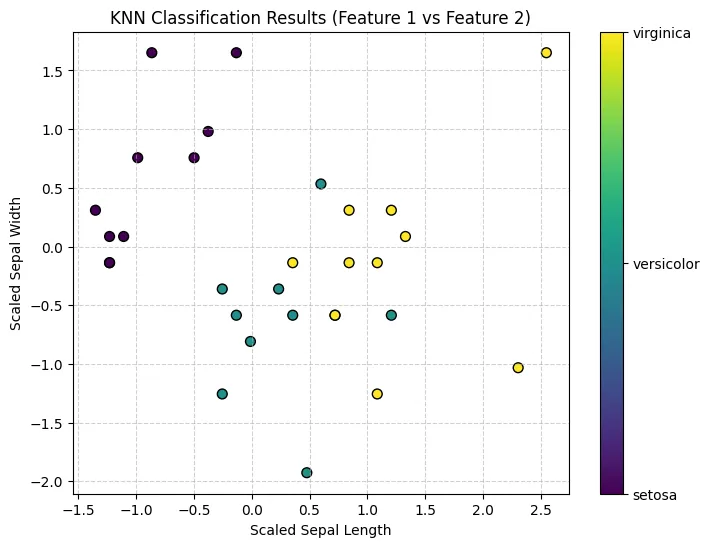
将测试集的结果可视化。由于鸢尾花数据集是四维的,这里简化为只绘制前两个特征的散点图,并用预测的类别着色。
# 可视化结果(仅使用前两个特征进行二维展示)plt.figure(figsize=(8, 6))# 使用预测的类别 (y_pred) 作为颜色# X_test[:, 0] 是第一个特征(萼片长度),X_test[:, 1] 是第二个特征(萼片宽度)plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis', marker='o', edgecolor='k', s=50)# 添加颜色条和标签cbar = plt.colorbar(ticks=np.unique(y_pred))cbar.set_ticklabels(iris.target_names)plt.title("KNN Classification Results (Feature 1 vs Feature 2)")plt.xlabel("Scaled Sepal Length")plt.ylabel("Scaled Sepal Width")plt.grid(True, linestyle='--', alpha=0.6)plt.show()


Python入门课


1、课程简介
生信基地希望能够给大家提供系统性、形成性、规范性的生信教学。本次《Python入门课》可针对性的指导、答疑,分为"Python课程绪论"、"Python下载与安装"、"变量与数据变型"、"类型转换"、"数据结构"、"运算符和表达式"、"语法与语句"、"数据的读取与保存"、"模块与包"、"基于Matplotlib的基础可视化"、"简单机器学习入门"十一个模块共21节课。当然,我们也不做生信快餐,课程视频剪辑完毕,永久回放。后续我们会持续拉群在群里进行课程内容的答疑。
2、Python介绍
Python作为本次课程核心编程语言,语法简洁、库生态丰富、计算高效,是数据科学与自动化开发的主流选择,兼顾入门友好与高效开发。随着研究数据量,Python可弥补R语言在处理规模与扩展性上的不足,更好适合现科研需求。
我们制作的单细胞和空间转录组教程几乎也全是基于Python环境。很多同学找我们学习单细胞的时候都表示不想学习编程语言,直接学习单细胞/空间转录组分析,不积跬步无以至千里,这显然是不现实的,所以,欢迎大家来参加此次的课程。

报名/缴费二维码:



资料&课表


课程目录:
1. Python课程绪论
2. Python下载与安装
2.2 安装(以 Windows 为例)
2.3 Linux / macOS 安装
2.4 Miniconda 安装 python(虚拟环境)
3. 变量与数据类型
3.1 整数
3.2 浮点数
3.3 字符串
3.4 布尔值
4. 类型转换
5. 数据结构
5.1 列表与元组
5.2 字典
5.3 集合
5.4 数组
5.5 Series
5.6 数据框 DataFrame
5.7 Anndata
6. 运算符和表达式
6.1 算数运算符
6.2 比较运算符
6.3 逻辑运算符
6.4 位运算符
6.5 赋值运算符
7. 语法与语句
7.1 if条件语句
7.2 for循环语句
7.3 while循环语句
7.4 跳转语句
7.5 函数定义与调用
8. 数据的读取与保存
8.1 基础信息
8.2 不同格式文件读取
9. 模块与包
10. 基于Matplotlib的基础可视化
10.1 基础可视化
10.2 图像大小和 DPI 设置
10.3 设置图例
10.4 实战练习
11. 简单机器学习入门


如何联系我们


已有生信基地联系方式的同学无需重复添加



