自学编程第46课:用Python写一段代码让麦克风实时语音识别——让电脑听到你说话
- 2026-06-29 21:25:37

在45课我们学会了识别音频文件里的语音,但Tyree说还得先录音再保存,太麻烦了。能不能直接对着电脑说话,它一边听一边认?
其实是可以的,今天咱们就用麦克风实时识别。你说一句,电脑认一句。
于是他端端正正坐在电脑前,清了清嗓子:“好了,开始吧。”
今天的课程我们就来做这个:从麦克风实时获取语音并转成文字。
01. 安装必要的库
首先win+r,输入cmd 打命令行打开,在命令行执行:
pip install SpeechRecognition

如果你想让程序能使用麦克风,还需要安装`pyaudio`。`pyaudio` 是一个让 Python 能够录制音频的底层库,`speech_recognition` 依赖于它来读取麦克风数据。
Windows 系统用户的推荐安装方式(如果直接`pip install pyaudio` 报错,用这个方法):
pip install pipwin
pipwin install pyaudio
如果下载不了,可以尝试用下面这个:

如果安装失败,可以先跳过,后面所有课程不依赖语音识别功能。
02. 第一个实时语音识别程序
下面来写这个实时语音识别的程序代码:
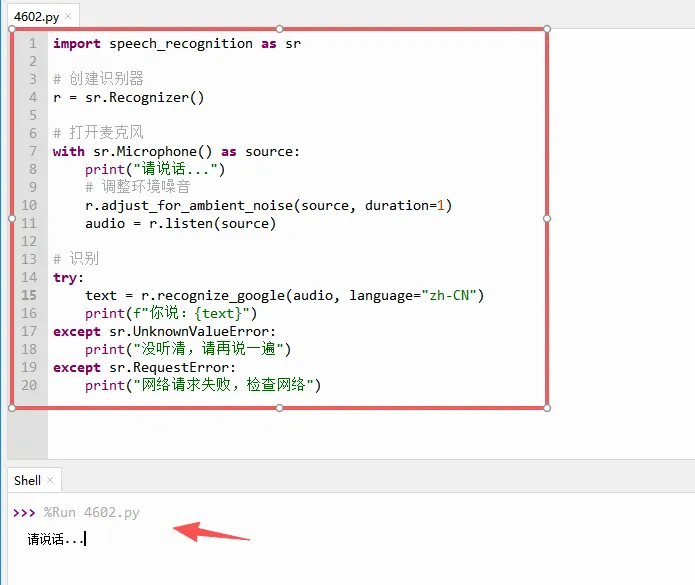
运行后,对着麦克风就可以说话识别啦!
下面来看看代码逐段的解释
- `sr.Microphone()`:这个对象代表你的电脑麦克风。`speech_recognition` 会通过 `pyaudio` 扫描你的系统音频设备,找到默认的麦克风。
- `with ... as source:`:这里使用 `with` 语句,保证录音结束后自动释放麦克风资源。`source` 就是当前麦克风对象,它告诉程序从哪个设备采集音频。
- `adjust_for_ambient_noise(source, duration=1)`:它做的不是“降噪”,而是检测当前环境的背景噪音,然后设置一个阈值。这个阈值决定了后面的 `listen` 什么时候认为“有人在说话”。
如果在安静房间,阈值会自动调整到较低水平,更容易捕捉到说话声;在嘈杂环境,阈值会调高,防止环境噪音被误判为说话。
- `listen(source)`:开始实际录音。它会持续监听 `source` 输入的音频数据,直到检测到一段“有效语音”结束(默认是检测到0.5秒以上的静默,就认为说话人已说完)。
- `recognize_google(audio, language="zh-CN")`:第45课我们讲过 API 的概念。
这里就是调用 Google 的语音识别服务器,把刚才录到的那段音频(`audio`)发过去,让服务器转成文字,然后返回结果。
03. 循环识别:持续监听
单次录音只能识别一句话,如果想持续监听,可以把它放进循环中:
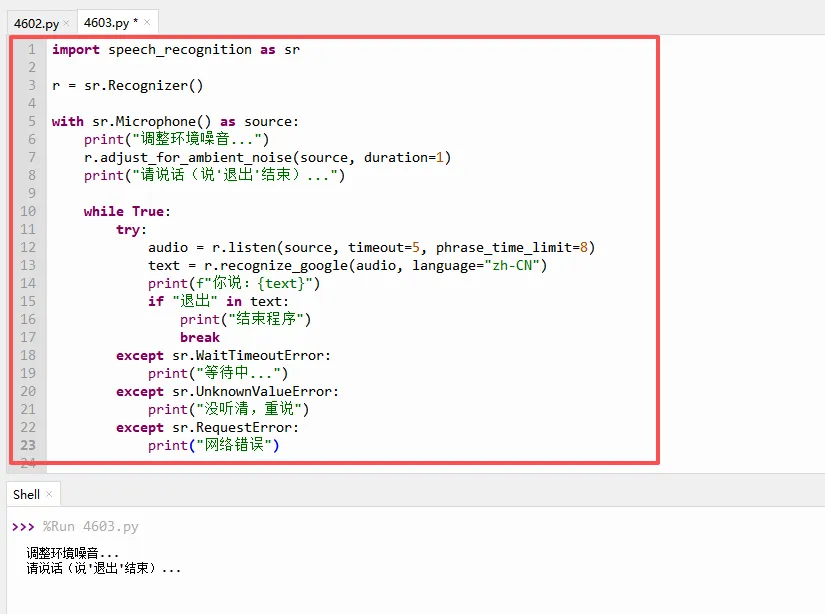
下面来看看新增参数的解释
- `timeout=5`:当程序在等待用户说话时,最多等5秒。如果5秒内麦克风没有收到任何声音,就抛出 `WaitTimeoutError`,然后回到循环开头继续等待。这样程序就不会卡死在 `listen` 上。
- `phrase_time_limit=8`:一旦检测到语音开始,最多录制8秒,超过就自动截断并识别。这防止有人说话太久导致程序长时间卡住。
04. 保存录音到文件(可选)
如果你想把刚才录到的音频保存到硬盘,以便后续检查或调试:
下图中圈起来的部分就是了。
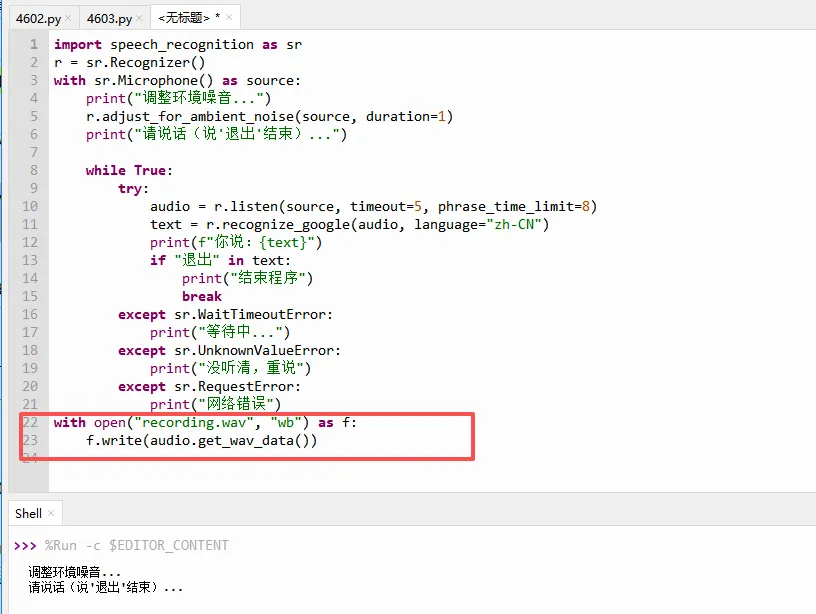
`get_wav_data()` 会返回一段二进制数据,格式是标准 WAV。保存后可以用播放器打开听一下,确认录音是否清晰。
Tyree试了几次,有时候识别不准,他就把录音保存下来自己听,发现是说话声音不够大。他把麦克风凑近一点就好了。
05. 如果网络不通怎么办?
`recognize_google` 需要联网。如果网络不通,你会收到 `RequestError` 错误。
有三种解决思路:
1. 使用国内的语音识别API,需要申请密钥。具体方法后续也会在评论区贴上。
2. 使用Vosk离线识别(完全不需要网络),需下载约780MB的模型文件,相关教程后续也会在评论区贴上。
3. 暂时跳过本课,进入后面不依赖语音识别的课程(自动化工具、爬虫、Web开发等)。
06. 课后小挑战
挑战识别英文
把`language="zh-CN"` 改成 `language="en-US"`,说一句英文试试。注意英文识别对发音清晰度要求较高,建议在安静环境下测试。
07. 今天学到了什么
- `Microphone()`:打开麦克风,需要 `pyaudio` 支持。
- `adjust_for_ambient_noise`:检测环境噪音,自动设置语音识别阈值。原理是在前1秒内计算背景音的基准音量,然后用这个基准判断后续音频中哪些是有效语音。
- `listen`:录音,并在检测到静默时停止。静默检测默认为0.5秒,可通过参数调整。
- `recognize_google`:调用在线 API 识别语音,需要联网。
- `timeout` 和 `phrase_time_limit`:控制等待时间和单次录音长度。
好了,今天课程内容讲完了,大家可以多多动手调试下!
下一节课我们来学习:语音识别+ 命令执行——说“打开浏览器”,电脑就真的打开浏览器。
————热门推荐————
少儿自学编程第40课:打包游戏成exe文件——把你用Python做的作品发给朋友
少儿自学编程第43课:用Python,MNIST手写数字识别——亲手训练一个AI
少儿自学编程第45课:语音识别入门(上)——从音频文件识别语音
自学编程第7课:turtle画图入门(画一个正方形,五角形,螺旋形,三角形)
自学编程第一步:安装Python和Thonny(零基础图文教程)
(本系列教程每天更新,欢迎关注收藏)

