很多人第一次接触 Agent,是从 LangChain、CrewAI、AutoGen 开始。框架文档里 Chain、Tool、Memory、Planner 一堆抽象,很容易让人觉得:Agent 很复杂,必须先学框架。
其实把框架剥开,底层逻辑就三件事:LLM 负责思考,工具负责行动,循环负责持续推进。
即:Agent = LLM + Tools + Loop。
理解这个公式,比背任何框架 API 都重要。框架会变,机制不会。下面用最小 Python Agent 把循环跑起来。
1. Agent 到底是什么?
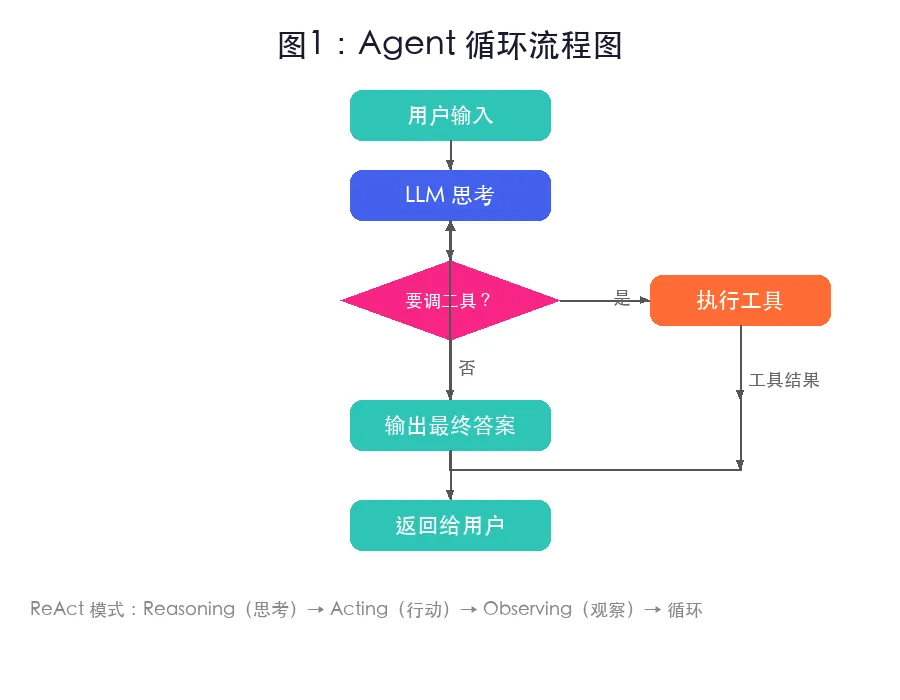
普通 LLM 调用是一次性的:用户提问,模型回答,结束。Agent 多了”行动循环”:
这个模式常称 ReAct:Reasoning + Acting。先推理,再行动,再观察结果,继续推理。
图1:Agent 循环流程图——用户输入进入 LLM,LLM 要么直接回答,要么调用工具;工具结果回传 LLM 继续思考,直到输出最终答案什么时候需要 Agent? 任务需要”多步判断 + 外部动作”时,如查资料、算数、调接口、读文件。只做改写、摘要、分类,普通 LLM 调用就够。
2. 用 Python 写一个最小 Agent
示例用 Anthropic Claude API 的 tool_use。OpenAI function calling 同一套思想:定义工具 → 模型选工具 → 程序执行 → 结果回传。
先安装依赖,通过环境变量设置 Key(不要写进代码):
pip install anthropic
export ANTHROPIC_API_KEY="你的_API_Key"
2.1 定义工具
工具不是函数本身,而是给模型看的"能力说明书":工具叫什么、能做什么、需要哪些参数。
import re
import anthropic
client = anthropic.Anthropic()
tools = [{
"name": "calculator",
"description": "计算简单数学表达式,只支持数字、加减乘除和括号。",
"input_schema": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "数学表达式,例如 123 * 456 + 789"
}
},
"required": ["expression"]
}
}]
工具描述越清楚,模型越容易选对。这里只放一个计算器,方便看懂完整链路。
2.2 执行工具
模型不会真的执行代码。它只提出”我要调 calculator,参数是 x”。真正执行的是你的 Python 程序。
defrun_tool(name: str, args: dict) -> str:
if name != "calculator":
return"未知工具"
expr = args["expression"]
ifnot re.fullmatch(r"[0-9+\-*/(). ]+", expr):
return"表达式包含不允许的字符"
try:
return str(eval(expr, {"__builtins__": {}}, {}))
except Exception as e:
returnf"计算失败:{e}"
这里用白名单限制字符。生产环境更建议用专门数学解析库,别让模型生成内容直接进入高权限执行环境。
2.3 写 Agent 循环
核心就是一个 for 循环:请求模型 → 检查工具调用 → 执行工具 → 结果塞回历史 → 再请求模型。
defagent(user_input: str, max_steps: int = 5) -> str:
messages = [{"role": "user", "content": user_input}]
for _ in range(max_steps):
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
tools=tools,
messages=messages,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return"".join(
block.text for block in response.content
if block.type == "text"
)
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = run_tool(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
messages.append({"role": "user", "content": tool_results})
return"达到最大循环次数,Agent 停止。"
print(agent("123 乘以 456 再加上 789 等于多少?"))
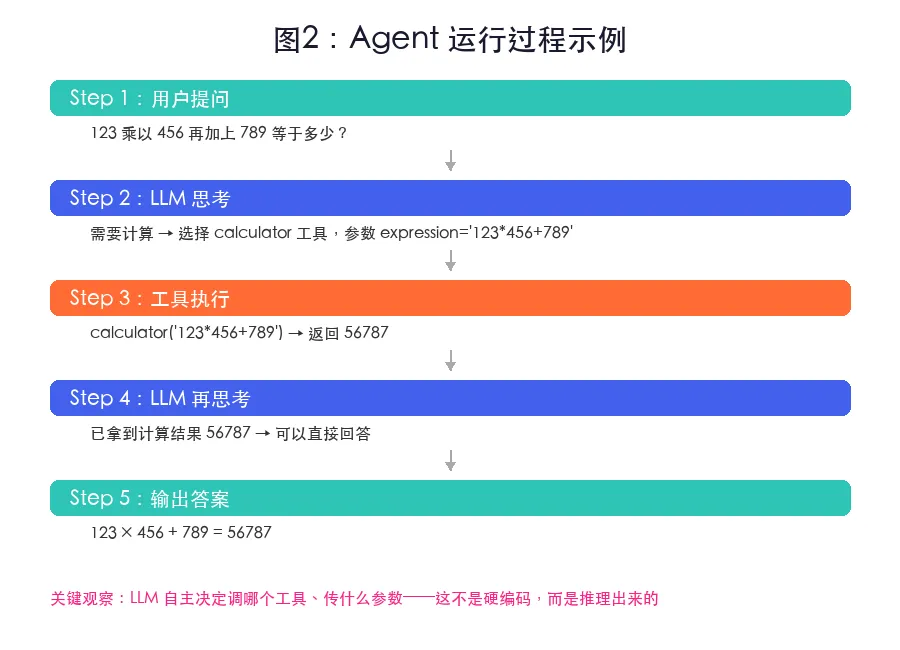
典型运行:用户提问 → LLM 判断需要计算器 → 生成工具调用 calculator({"expression":"123*456+789"}) → Python 执行得 56877 → 结果回传 LLM → LLM 输出自然语言答案。
图2:Agent 运行过程——LLM 思考"需要计算器"→ 调用 calculator → 工具返回 56787 → LLM 组织最终回答注意:图中示例数值用于展示流程;如果你换表达式,结果以程序实际计算为准。
什么时候用这个最小版? 学原理、验证工具调用、做内部小工具。还不适合直接上生产——缺权限控制、日志、重试、上下文管理和人工确认。
3. 拆开看:Agent 的 4 个关键机制
机制一:工具定义
工具定义就是 LLM 的“工具菜单”。模型根据 name、description 和参数 schema 判断能不能用、该不该用、怎么传参。
坑点: 工具描述太泛会导致误选。例如“处理数据”不如“计算数学表达式并返回结果”。工具越多,描述越要互斥。
什么时候用: 只要模型需要访问外部世界——数据库、文件、接口、搜索、计算——就要定义工具。
机制二:模型决策
Agent 不是你硬编码“先调 A,再调 B”。LLM 会根据问题和工具列表自己决定下一步。这是 Agent 相比普通脚本最大的区别。
什么时候用: 路径不固定时用 Agent;路径固定时用普通代码编排更稳定、更便宜。
机制三:工具执行
LLM 只负责“提出动作”,程序负责“执行动作”。这个边界很重要:工具权限、参数校验、失败处理,都应该在你控制的代码里完成。
什么时候用: 永远如此。不要让模型直接执行任意 shell、SQL 或高权限 API。
机制四:循环终止
stop_reason == "tool_use" 表示模型还想行动;否则说明它准备回答。除此之外,还要加 max_steps,防止无限循环。
什么时候用: 所有 Agent 都必须有循环上限。没有上限,成本和风险都会失控。
4. 从最小 Agent 到实用 Agent
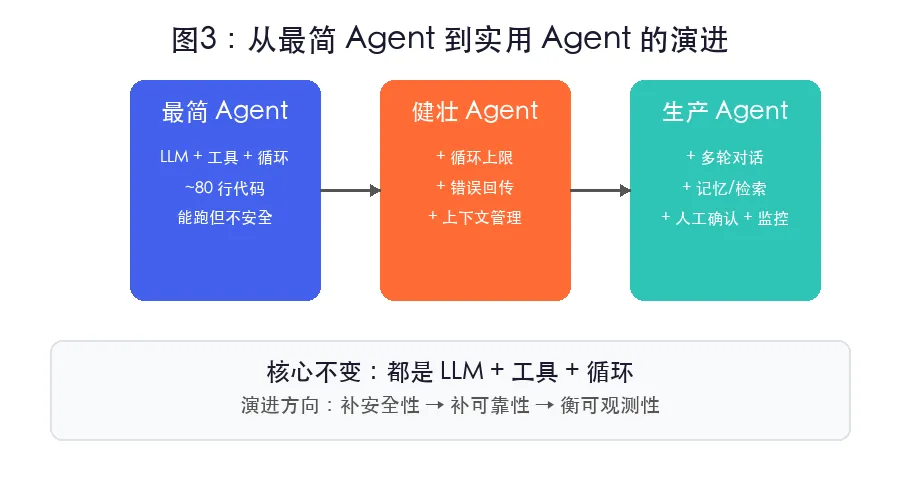
最小版本能说明原理,但实用 Agent 至少要补三层能力。
图3:从最简 Agent 到实用 Agent 的演进——补循环上限、补错误回传、补上下文管理第一,循环上限。用 max_steps 控制最多执行几轮,避免模型在“搜索—总结—再搜索”里打转。
第二,错误回传。工具失败时不要吞错误,要把错误作为 tool_result 返回给模型。模型看见“参数不合法”或“接口超时”,才有机会换策略。
第三,上下文管理。每轮工具调用都会让消息历史变长。短任务可以直接保留全部历史;长任务要做截断、摘要或外部记忆,否则 token 会爆。
什么时候升级? 当 Agent 需要跑很多步、接多个工具、给多人使用,或者会触碰文件/数据库/生产系统时,就不能停留在教学版。
5. 要不要用框架?
建议路线:先写原生 Agent,搞懂 LLM + Tool + Loop;再学框架。 否则框架出错时,你分不清是模型没选对工具、schema 写错、工具执行失败,还是框架封装层的问题。
6. 继续练习
如果你想继续深入,做三个小练习:
- 加一个
read_file 工具,让 Agent 能读本地文件; - 加一个
search 工具,让 Agent 能查外部资料; - 把
messages 保存到文件里,实现最简单的记忆。
做完这三个练习,你就真正理解了 Agent 的基本机制:模型负责决策,工具负责行动,循环负责推进,边界负责安全。
参考资料
- Building Effective Agents(Anthropic 博客)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
