
python爬虫篇II
今天爬取飞卢小说网的小说,并将小说中的免费章节的下载到本地文件夹里面的txt文件
我下载的是四合院:与弟弟妹妹相依为命
期望效果
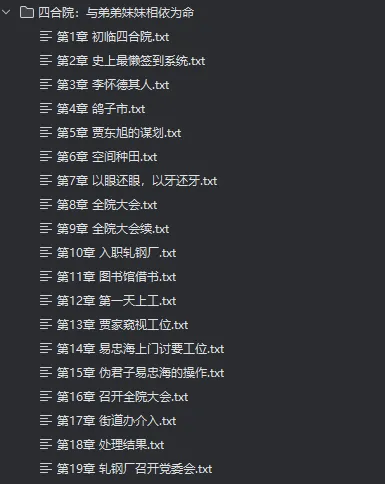

和漫画一样
1.首先,请输入想要爬的小说id,id从地址栏获取
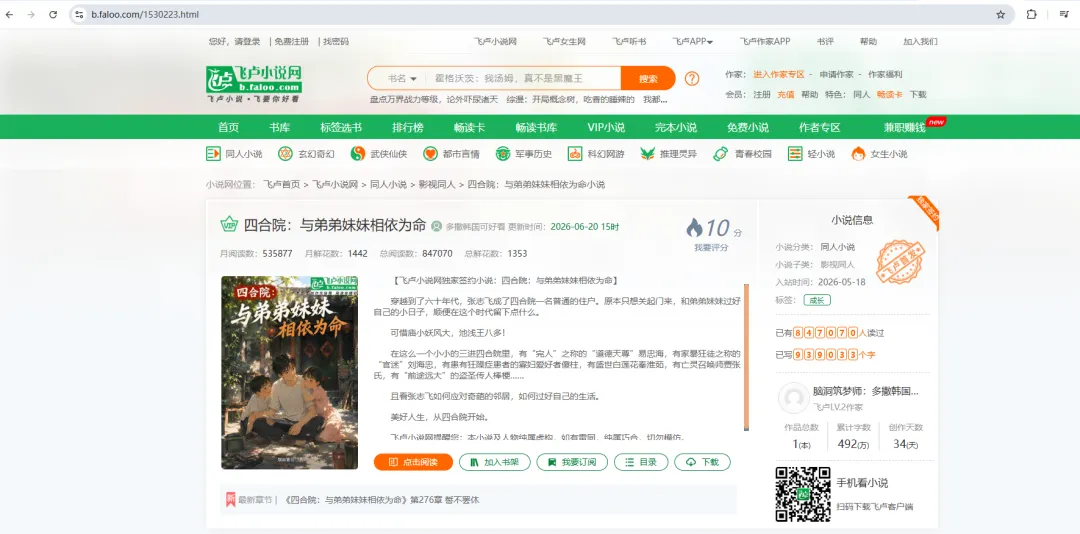
2.让用户输入小说id
textid = input("请输入小说id")
重点代码
def getxiaoshuo():
textid=input("请输入小说id")
baseUrl = f"https://b.faloo.com/{textid}.html"
response=requests.get(baseUrl,headers)
document=html.fromstring(response.text)
list=document.xpath("//div[@id='mulu']/div[@class='DivTable']/div")
textlist=[]
hreflist=[]
subtitle = document.xpath("//h1[@id='novelName']/text()")
print(subtitle)
for item in list:
title=item.xpath("./div[@class='DivTd3']/a/text()")
href=item.xpath("./div[@class='DivTd3']/a/@href")
if(len(title)!=0):
for items in title:
textlist.append(items)
if (len(href) != 0):
for hrefitem in href:
hreflist.append(hrefitem.replace("//",""))
print(subtitle)
download(subtitle,textlist,hreflist)
8.下载txt
def download(subtitle, textlist, hreflist):
print(subtitle)
exist=os.path.exists(subtitle[0])
if(exist == False):
os.mkdir(subtitle[0])
for text, href in zip(textlist, hreflist):
print(text, href)
result = os.path.exists(f'{subtitle[0]}/' + text)
print(result)
if (result == False):
responses=requests.get('https://'+href,headers)
documentnew=html.fromstring(responses.text)
list=documentnew.xpath("//div[@class='noveContent']/p/text()")
with open(f'{subtitle[0]}/' + text+'.txt','at',encoding="utf-8") as file:
for item in list:
file.write(item)
爬虫暂时到此结束,因为能爬的数据太少了
接下来更新数据分析
需要了解服务器和域名的购买以及返佣政策的可以找我,我有朋友做这方面对这些比较了解。第一个群:只讨论java+vue的项目,学历提升和卖服务器的就别进了,进了也会被踢。第二个群:只讨论python项目,以后python的代码和教程会在群里开源,学历提升和卖服务器的就别进了,进了也会被踢。




