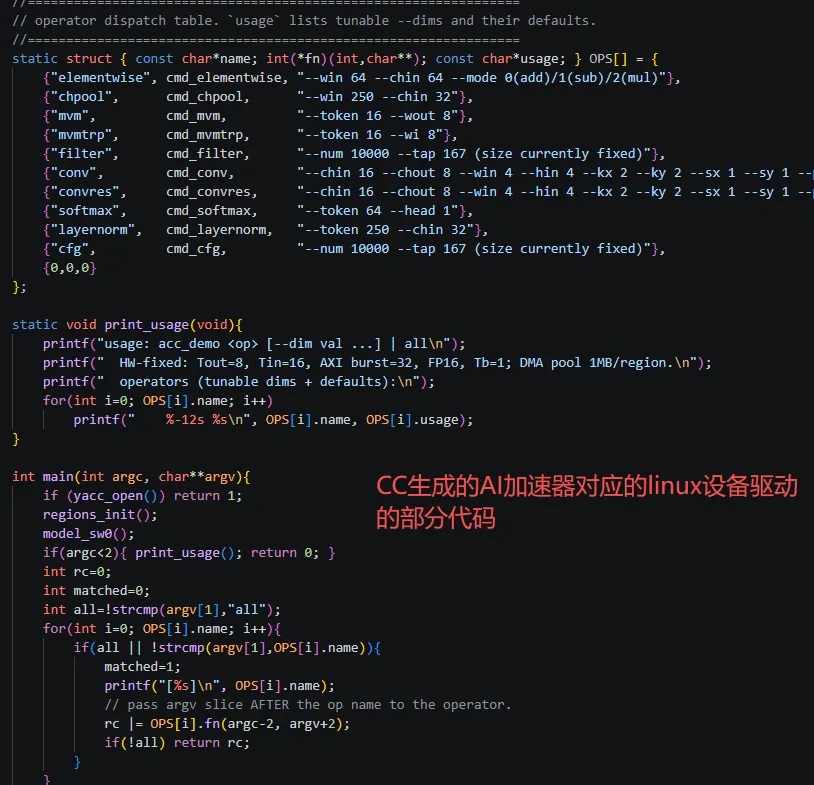
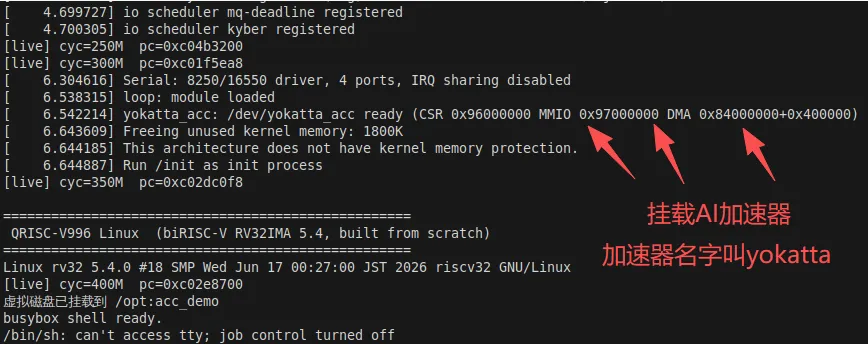
本文主要介绍如何利用 Claude Code(CC)在前一版 RISC-V SoC 的基础上,集成一个完整的 AI 加速器,并在 Linux 下以设备驱动的形式运行。本次将加速器作为外设挂进总线,配套实现了内核态驱动(kernel module)、用户态 runtime 以及算子测试。Notably,加速器的 RTL 是合作者此前开发的工程,而总线接口的对接、Linux 设备驱动乃至上层调用流程均由 CC 实现。目前,整个设计最后还差 eMMC 和 DDR PHY 的 IP,才能拿去做有点用的芯片,但这两块就比较难搞了(为什么一个DDR PHY IP能卖这么贵 )。
)。
本版工程因涉及到一些当前灌水用的idea,等文章灌出来之后再放到Github上(我的文章可能一把就中,但我的文章一把就中有点不太可能——诺言诺语)。
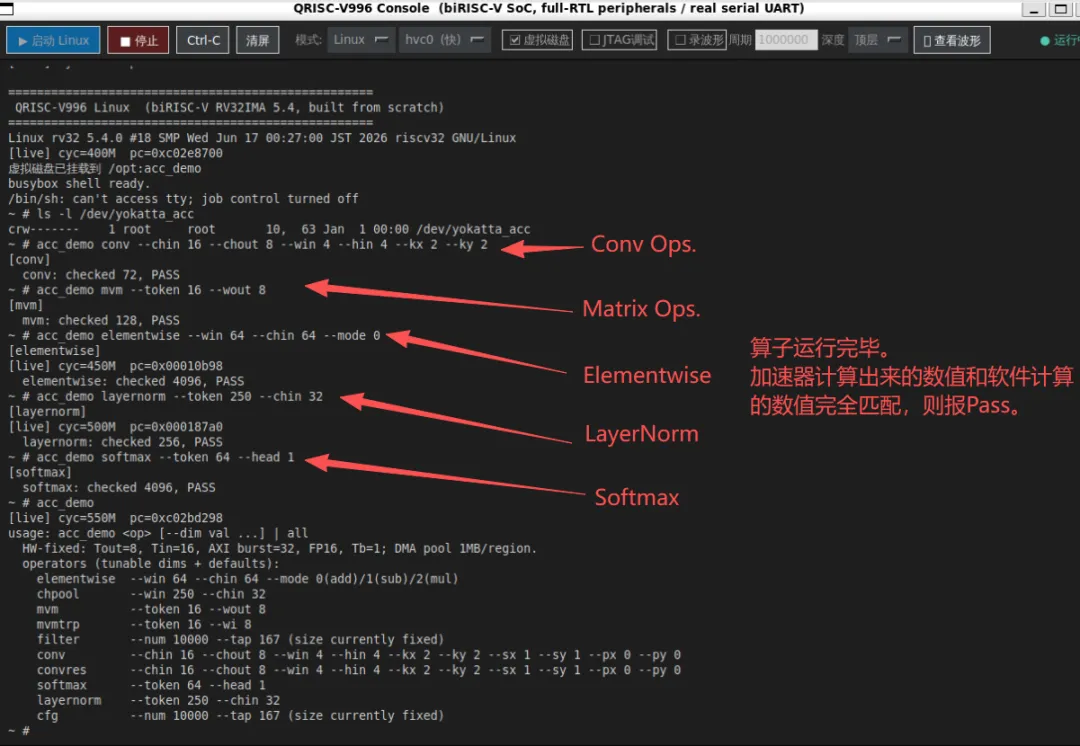
展示如下:内容包括驱动加载、加速器寄存器配置,以及在 Linux 用户态下跑通各种算子
与 CC 的沟通中需要提供完整的加速器 RTL 代码和 Testbench,并经过大量来回沟通,确保每一步都可行。难度明显比前面章节的Linux 编译和常规 IP 集成复杂得多,CC 中途也错了非常多次,老是说我的加速器代码有问题,一直走歪路。磨了2天才把整个工程磨出来。大概率是因为它的大模型在训练时并没有太多 AI 加速器设计相关的语料和数据集。所以在下发命令时需要十分精确,已经无法像上一章那样随手就做个 AXI 总线、JTAG 或 QSPI 的 IP。毕竟这些都是烂大街的 IP,网上相关资料一大堆。
本文以下内容均由Claude Code生成。不用看了,凑字数的。
QRISC-V996 架构文档
一颗能跑 Linux、可 JTAG 调试、从 QSPI flash 启动、内建 AI 加速器的 biRISC-V SoC
0. 总览
QRISC-V996 是基于开源 biRISC-V 双发射 RV32IMA 核构建的片上系统(SoC),目标是在周期级 RTL 仿真(Verilator)上完整运行 Linux,同时具备真实芯片应有的多条工程化通路:OpenOCD 兼容的 JTAG 调试、QSPI flash 烧录 / 启动,以及一颗挂在总线上的 Yokatta AI 加速器。
系统由五大块组成:① 双发射核(含 I/D-cache + MMU);② SoC 互连(仲裁 + 地址译码 + XIP 路由);③ 片上外设(中断 / 定时 / UART / SPI / GPIO);④ QSPI flash 子系统(两种启动 + 命令控制器);⑤ Yokatta AI 加速器(10 个算子 + DMA 主口)。再旁挂一套 JTAG 调试子系统。
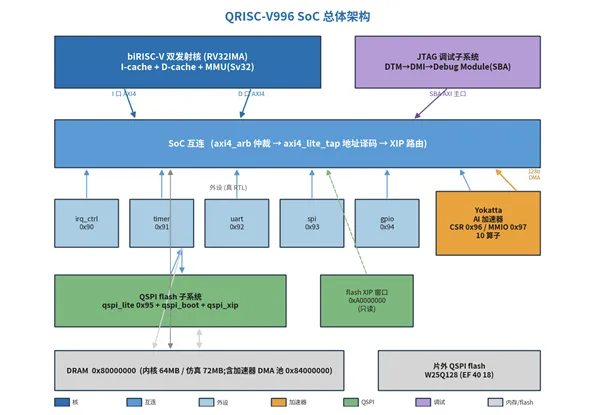
图 0-1 总体架构总览
1. 处理器核(biRISC-V)
核是一个顺序双发射的 RV32IMA 流水线,每拍最多发射两条指令:
·前端:fetch(双取指槽)→ decode → issue(发射选择 + 记分牌)
·执行:两条 ALU / 分支流水(exec0 / exec1)+ 乘除 + LSU(访存)+ CSR
·存储:I-cache + D-cache,经 MMU(Sv32)接 2 路 AXI4 主口(I 口取指 / D 口访存)
核对外只暴露 2 路 AXI4 主口和调试接口;其余全部经 SoC 互连访问。关键约定:cache 是否生效由物理地址范围决定(参数 MEM_CACHE_ADDR_MIN / MAX),不看页表属性 —— 这条约定在第 6 节加速器一致性里至关重要。
2. SoC 互连与地址映射
互连做三件事:把核的 I/D 两口仲裁进统一总线、按地址译码分发到各从设备、把落在 XIP 区的读请求路由到 QSPI flash。加速器的 128 位 DMA 主口经位宽转换也接进同一仲裁器,与 CPU 共享主 DRAM。地址映射如下:
区域 | 基址 | 说明 |
DRAM | 0x80000000 | 主内存;dts 内核 RAM 64MB,仿真 tb DRAM 72MB |
irq_ctrl | 0x90000000 | Xilinx 风格中断控制器,汇聚各外设中断 |
timer | 0x91000000 | 周期中断,内核时钟源 |
uart_lite | 0x92000000 | 真串行 tx/rx,Linux 控制台 |
spi_lite | 0x93000000 | SPI 主机 |
gpio | 0x94000000 | 通用 IO |
qspi_lite | 0x95000000 | QSPI 命令控制器(CMD/ADDR/LEN/...) |
加速器 CSR | 0x96000000 | Yokatta 加速器控制寄存器(PERIPH6) |
加速器 MMIO | 0x97000000 | Yokatta 片上 SRAM 窗口(PERIPH7) |
flash XIP | 0xA0000000 | 只读;CPU 读 → 翻译成 0xEB 四线读 flash |
其中 0xA0000000 XIP 窗口是只读映射:CPU 对它的取指 / 读会被路由到 qspi_xip 控制器,实时翻译成0xEB 四线读 flash —— 对软件透明,像读普通内存一样从 flash 取指。
3. 片上外设
一套真 RTL 外设(非行为模型),经 irq_ctrl 把中断汇聚回核:
·uart_lite(0x92000000)—— 真串行 tx/rx,即 Linux 控制台;tb 端像示波器一样把串行线反序列化成字符。
·timer(0x91000000)—— 周期中断,内核时钟源。
·spi_lite / gpio(0x93 / 0x94)—— SPI 主机与通用 IO。
·irq_ctrl(0x90000000)—— 上述中断汇聚 → 核 intr_i。RISC-V 上需把该控制器注册成根中断处理器(set_handle_irq),这是本平台对 Linux irq-xilinx-intc 驱动的关键改动。
4. QSPI flash 子系统
一颗片外 QSPI flash(W25Q128 行为模型,JEDEC EF 40 18),由五个使用者共享,经一个五级优先级引脚 mux 仲裁。
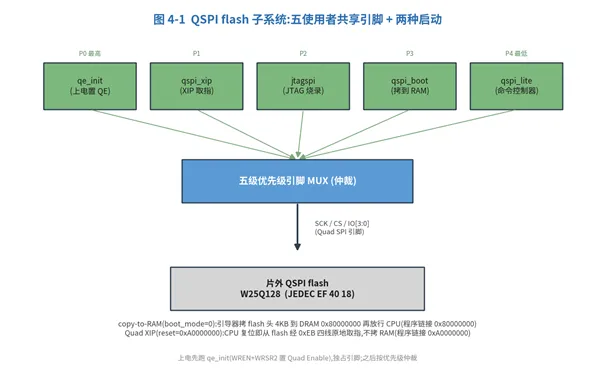
图 4-1 QSPI 子系统与两种启动方式
两种从 flash 启动:
·copy-to-RAM(boot_mode=0):上电后 qspi_boot 引导器把 flash 头 4KB 拷进 DRAM 0x80000000,再放行 CPU。程序链接在 0x80000000。
·Quad XIP(reset 向量 = 0xA0000000):CPU 复位即从 flash 映射窗口经 0xEB 四线原地取指,不拷到 RAM。程序链接在 0xA0000000,栈 / 数据在 DRAM。
上电 QE + 引脚仲裁:真实 W25Q 在四线读前必须先把状态寄存器的 QE(Quad Enable)位置 1,所以 qe_init 在复位后最先跑(WREN+WRSR2),期间独占 flash 引脚;之后 xip / jtagspi / boot / qspi_lite 按优先级仲裁。
qspi_lite(0x95000000)是命令式控制器(CMD/ADDR/LEN/CTRL/STATUS/WDATA/RDATA),供软件或调试器经 SBA 直接发 WREN / 扇区擦 / 页编程等命令读写 flash。
5. Yokatta AI 加速器
挂在总线上的一颗 AI 加速器,经 axi4_lite_tap 接在 CSR(0x96000000)/ MMIO(0x97000000),其 128 位 DMA 主口经位宽转换接 axi4_arb 与 CPU 共享主 DRAM。支持 10 个神经网络算子:
类别 | 算子 |
逐元素 / 池化 | elementwise(加 / 减 / 乘)、chpool(通道池化) |
矩阵乘 | mvm、mvmtrp(转置权重) |
卷积 | conv、convres(带残差) |
归一化 / 激活 | softmax、layernorm |
其他 | filter(滤波)、cfg(配置自动机) |
数据格式:FP16(IEEE half)输入 / 输出,内部 FP20(1-6-13)做累加,卷积权重可用 INT4。HW 固定参数:Tout=8、Tin=16、AXI burst=32。
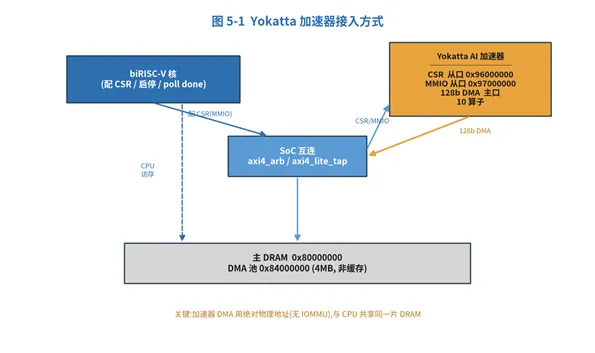
图 5-1 Yokatta 加速器接入方式
访问方式(两条线):
·裸机协同验证:每个算子一个 testbench(tb/tb_soc_<op>/),tb 直接灌输入 + 生成软件 golden + 比对;驱动经 DRAM 邮箱(INPUT_READY / DONE)握手。10 个算子秒级出 PASS/FAIL,全部通过。
·Linux 用户态:统一应用 acc_demo,经内核 misc 驱动 /dev/yokatta_acc(mmap CSR / MMIO / DMA 池 + ioctl 取 DMA 物理地址)。命令行可调尺寸:acc_demo all / acc_demo softmax --token 64 --head 1。
6. CPU 与加速器的 Cache 一致性
这是把加速器从裸机搬到 Linux 时踩到、并最终解决的关键工程问题。加速器 DMA 用绝对物理地址(无 IOMMU)与 CPU 共享 DRAM;CPU 的数据 cache 必须与加速器看到的 DRAM 保持一致,否则算子全部失败。
本核的特性:是否缓存纯由物理地址范围决定(MEM_CACHE_ADDR_MIN / MAX),无视页表的 noncached 属性。因此 Linux 驱动的 pgprot_noncached 在本核上不起作用。
| 修复前 | 修复后 |
MEM_CACHE_ADDR_MAX | 0x8fffffff | 0x83ffffff |
DMA 池(0x84000000) | 在 cache 区内 → 被缓存 | 在 cache 区外 → 非缓存 |
现象 | CPU 写的输入卡在 dcache,加速器读 DRAM 旧值 | CPU 写直达 DRAM,加速器立刻看到 |
10 算子结果 | 0 PASS / 10 FAIL | 10 PASS / 0 FAIL(ALL PASS) |
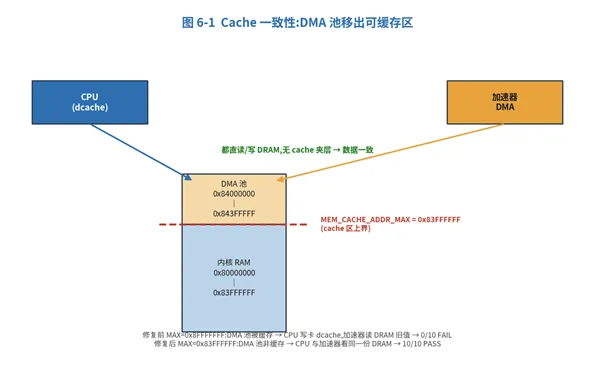
图 6-1 DMA 池移出可缓存区,CPU 与加速器看同一份 DRAM
修复办法:把 cache 区上界收到 0x83ffffff —— cache 只覆盖 64MB 内核 RAM,DMA 池(0x84000000,在内核 RAM 之后)落在 cache 区外,自然非缓存。CPU 与加速器看同一份 DRAM,无需任何软件 flush,用户态应用一行不用改。裸机算子数据在 0x80xxxxxx 仍可缓存,不受影响。
为什么不照搬裸机的 cache flush:裸机用自定义 CSR(csrw 0x3a0)flush dcache,但那是 M 态特权指令,Linux 用户态(U 态)甚至内核态(S 态)执行都会触发非法指令异常。所以 Linux 侧选「DMA 池非缓存」是正解。
7. JTAG 调试子系统
一套符合 RISC-V Debug Spec 0.13 的调试模块,接真 OpenOCD:
·调试链:jtag_dtm(TAP/DTM)→ riscv_debug(DMI mux)→ dm_sba(Debug Module)。
·能力:halt / resume、单步、软件断点(ebreak)、读写 GPR·CSR。
·System Bus Access(SBA):Debug Module 自带一路独立 AXI 主口,可读写整片内存映射(DRAM / 外设 / 加速器 CSR / DMA 池)而不暂停核 —— OpenOCD 的 mdw / mww 走这条。
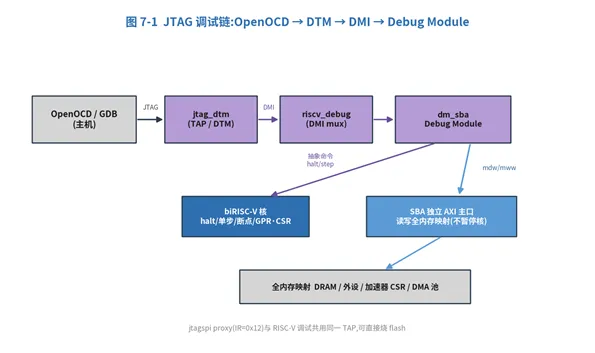
图 7-1 JTAG 调试链路
OpenOCD 还经 jtagspi proxy(IR=0x12)直接烧录 flash;烧录与 RISC-V 调试共用同一 TAP。
注:仿真自测(+DBGTEST / +QSPITEST)用一个 tdmi 测试注入口绕过慢 JTAG 直驱 DMI(几千周期跑完一套自测)。该注入口用 `ifdef SIM_SELFTEST 包裹,综合时整片消失 —— 芯片里不留测试后门。
8. 复位链:标准 ndmreset
「JTAG 烧 flash → 重启 → 从 flash 启动」这条真机流程,靠的是 RISC-V Debug Spec 标准的 ndmreset(dmcontrol.ndmreset,复位除 Debug Module 外的整个系统),不是仿真用的「门铃」。
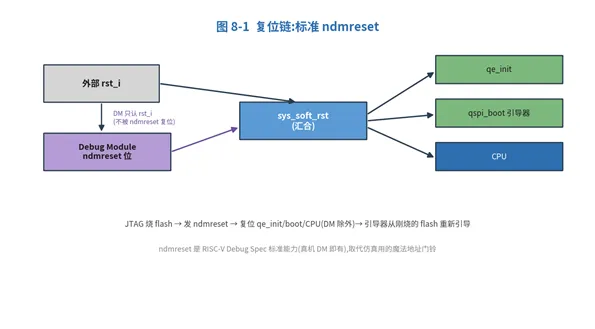
图 8-1 复位链设计
关键设计:ndmreset 汇进 qe_init + qspi_boot + CPU 的复位,但 Debug Module 自身只认外部 rst_i —— 否则 ndmreset 会把调试器自己复位掉,OpenOCD 掉线。烧完 flash 发一次 ndmreset,引导器就从刚烧的 flash 重新引导,真机一样成立。
9. 验证与工具
·仿真:Verilator(--binary --timing),纯 RTL;tb 提供行为级 DRAM + 串行 UART 反序列化。仿真线程数可配(SIM_THREADS,实测全 Linux 用 8 线程)。
·快速自测:+DBGTEST(halt / 单步 / 断点)、+QSPITEST(flash 读写),几千周期出结果。
·加速器协同验证:tb/tb_soc_<op>/ 每算子一套,秒级出 PASS/FAIL,10 个全 PASS。
·从 flash 启动:+QSPIBOOT(copy-to-RAM)、+XIPBOOT(Quad XIP)。
·GUI:Python / Tkinter 调试台,集成连接 OpenOCD、核调试、flash 烧录 / 读写、XIP 更新、ndmreset 启动、波形查看;Linux 模式 + 虚拟磁盘可直接在 shell 里跑 acc_demo。
·Linux 端到端:从源码编译内核 5.4 + BusyBox,在 RTL 上启动到 busybox shell,并跑通加速器 10 算子(acc_demo all → ALL PASS)。完整复现步骤见仓库 docs/ 与各目录 README。
工程地址:https://github.com/xxxxxxxx