【入门到精通】Python编程集合,一篇文章全讲解
- 2026-06-30 05:39:04
走过路过不要错过
点击蓝字关注我们
Python环境部署
Python的安装
目前市场主流的Python版本,基本上是3.7~3.9左右,因为3.10开始,有很多第三方库还不太支持,所以还是推荐下载安装3.10以下的版本。
Python下载直接在官网下载。下载地址:https://www.python.org/downloads/
选择3.7~3.9的版本进行下载即可,下载好后,双击打开python的exe文件,根据提示下一步下一步,执行安装,安装完成之后,可以在cmd中输入python --verison 来查看python安装是否成功。如果显示有python的版本,则表示安装成功。

如果看完还不会安装,可以直接联系我哦~
Pycharm的安装
Python环境安装好后,虽然Python自带有一个IDE的编码工具,并且命令行也可以支持python编码,但这些东西都极其难用,没有必要去浪费时间研究。目前Python最常用的编译工具叫做Pycharm,分为专业版和社区版两种,专业版需要购买license付费激活,社区版是开源免费使用的。对于初期学习Python以及做Python自动化的人而言,用社区版已经完全够了,不需要再去想着专业版怎么破解之类的了。
选择Community版本直接点击Download进行下载即可。
社区版下载地址:https://www.jetbrains.com/pycharm/download/#section=windows
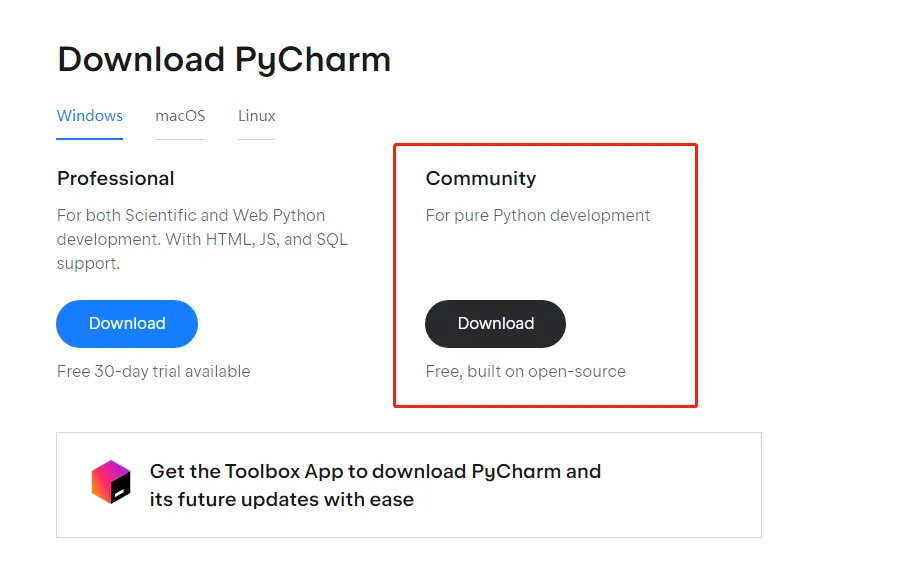
下载好社区版之后,也是直接下一步下一步地进行安装就好,但是需要注意一点,为了确保环境可用,在安装时要勾选Add "bin" folder to the Path选项。
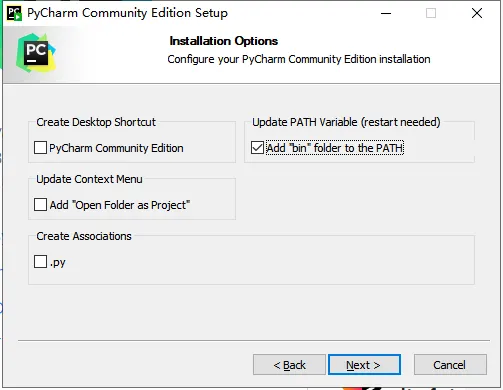
安装完成后,在Pycharm中因为没有任何工程存在,所以看不到任何东西,点击New Project创建一个新的工程,在Location中确定好工程的路径以及工程名称后,点击Create就可以开始我们的Python之旅了。但是在创建时需要注意一个小小的细节,就是Python工程下分为虚拟环境和本地环境两种不同的环境模式。
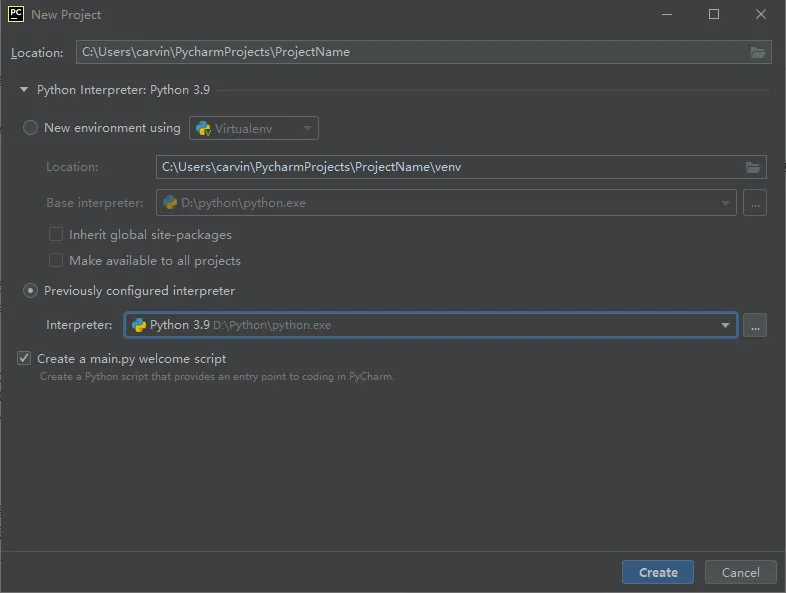
New Environment using Virtualenv表示创建一个虚拟Python环境。意思就是在创建这个工程时,会创建一个完整的虚拟环境(可以理解为虚拟机一样),所有的第三库都需要你自行安装,这个环境不会调用本地的任何资源,与其他工程不会存在有任何环境的关联性。用于独立化开发环境有比较好的效果,但是在创建时比较耗费时间,因为要开辟虚拟资源。
Previously configured interpreter表示创建一个本地Python环境,基于本地所安装的所有第三方库直接进行调用,这种模式下的所有工程都共用自己的本地环境,不会额外耗费资源。当然,每个工程也就无法独立环境了。一般我用这种,因为速度很快。
初识Python
Python工程结构介绍
在创建一个Python工程后,还需要基于个人的需求,在工程下创建各类文件/文件夹。这些文件/文件夹都是在工程下右键,选择New功能创建出来的。
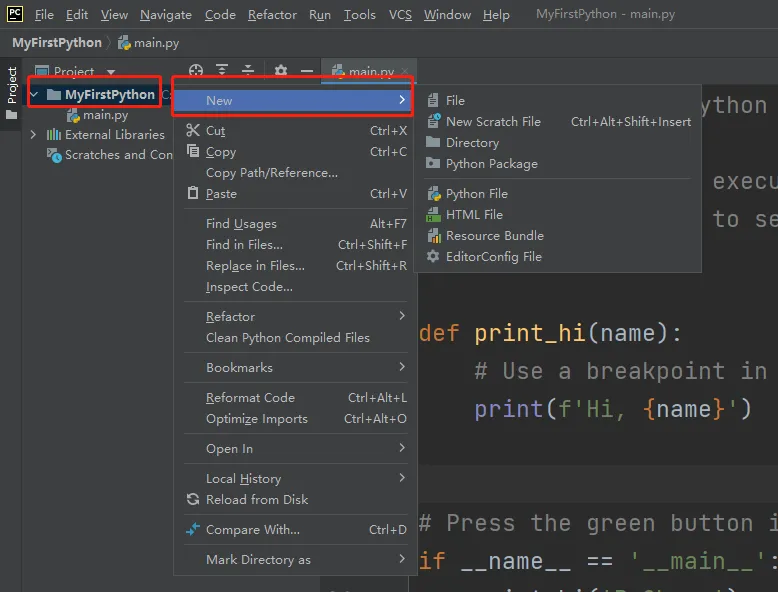
在Python中,工程结构内容分为以下几种:
File:可创建各类文件,比如txt,yaml,py等等,输入时注意格式为“文件名称.后缀名”,按照这样的模式进行输入,可以创建各类后缀名对应的文件。
New Scratch File:可创建一个临时文件,用于创建一个可随时删除的文件,这个文件不会与工程产生任何联系。我基本不用这个功能。整体来说就是“可以用,但是没有必要。”
Directory:可创建一个目录,你可以直接理解为就是创建一个文件夹。一般用来管理各类文件之类的,比如txt、csv等等
Python Package:可创建一个Python包,创建时会默认生成一个init.py的文件。一般所有的python模块都会在不同的Package中进行管理,init.py文件的作用就是在我们使用from...import...时,会调用到init.py中的内容。所以,如果你在之后写入有非常多的模块需要一次性导入时,可以通过修改init.py的内容来实现这个效果,方便我们简化导入的代码,这个后续慢慢说。
Python File:可直接创建一个.py后缀名的Python文件,用于进行Python代码的编写。这个是Python编程下使用最多的文件格式。创建时选择默认的python file即可。
HTML File、Resource Bundle等等可以忽略,暂时用不上。
第一个Python程序
但凡接触过编程的人都会知道,所有的编程都始于一段伟大的代码,那就是Hello World!咱们Python也不例外。
实现Hello World的步骤如下:
在已有工程下,创建一个Python File,取名为FirstCode
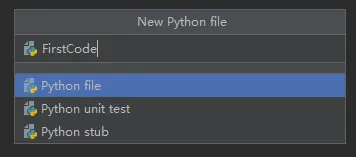
在打开的py文件中,输入python代码
print('Hello World!')
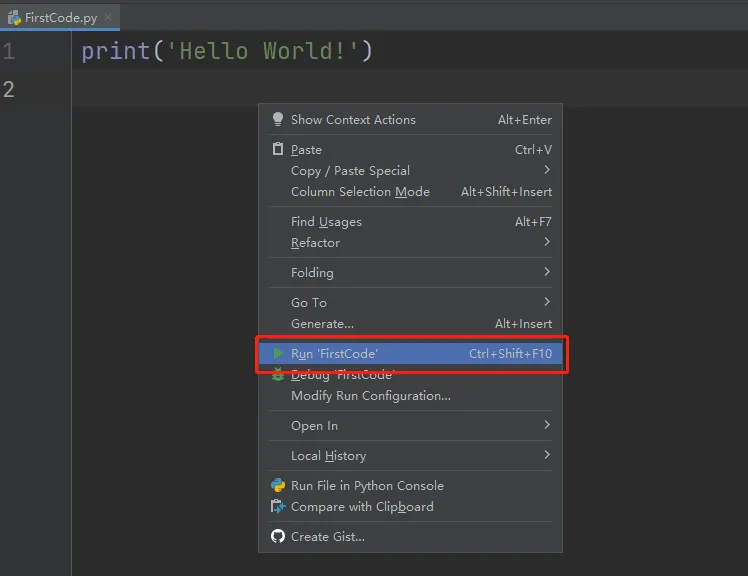
在py文件中,点击右键,在弹出的菜单中选择 Run 'FirstCode',点击执行即可。
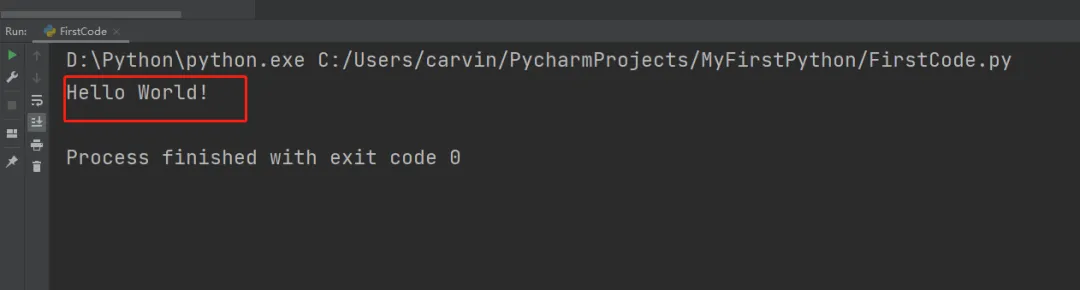
然后在pycharm软件的下方,有一个控制台,你运行代码后,就可以在这里看到,你的代码运行已经成功!
Python语法与编程基础
编码规范
Python语言本身在编写时,会有非常多的格式要求以及行业内的规范要求,我们在后续的内容讲解过程中,随着内容的逐步深入,会讲解到更多的规范,在刚开始编程时,我们需要了解到的就是一些最为基本的规范要求。具体内容包括:
命名规则:所有的工程、包名、文件名、类名、函数名等,需要命名的东西,我们在命名时都需要注意遵循基本的命名规则
'''部分命名规则:1. 不得使用关键字进行命名,例如:print.py等2. 不得使用拼音进行命名3. 多个单词组成的名称时,需要通过_或者开头字母大写的形式将各个单词区分开,例如:MyFirstPython、my_first_python4. 命名时要统一命名格式,尽量保持同一种风格的命名方式,便于阅读者快速理解5. 名称前添加_表示私有,名称后添加_表示避免关键字'''
缩进:Python编程非常关注缩进,同一级别的代码块的缩进量必须保持一致,不然则会抛出异常。缩进统一为4个空格,在实操时可以通过Tab来进行缩进的控制。
弱数据类型:Python中所有的变量都是弱数据类型,我们可以不用去定义每一个变量的数据类型,通过赋值,变量可以成为任意的数据类型。
注释:代码编写时,为了更好地让其他人读懂,我们会在代码块中添加注释,注释的代码将不会被运行。Python中的注释形态分为单行与多行。
# 单个#放在行头,表示整行注释,一般用于对下方的单行或者几行代码进行讲解print('黄财财') # 代码结尾的# 表示从当前位置开始注释,一般是通过注释的形式对本行代码进行讲解'''通过这种格式实现多行注释,一般用于对整个文件、一个完整代码块等进行注释讲解'''
编码规范其实相对来说会有非常多的内容,在初期先简单了解一些基本的即可,毕竟来日方长嘛。
变量
顾名思义,“变量”就是可以变化的量,用于记录某种特定状态。
在编程过程中,我们会需要应用到各种内容,在引用这些内容时,就会频繁通过变量来进行引用。所以变量的灵活应用是我们在编程过程中非常重要的一个点。
变量的用法
# 语法格式:变量名 赋值符号 变量值name = '黄财财' # '='表示将'黄财财'赋值给到'name'变量。而不是说'name'变量等于'黄财财'# 同时为多个变量进行赋值# 变量a/b/c都赋值为'黄财财'a = b = c = '黄财财'# 变量a赋值为1,b赋值为2,c赋值为3a, b, c = 1, 2, 3
变量存储的原理:搞清楚变量的存储原理,对于后续的实际使用会带来非常大的帮助
'''1. 在内存中申请一块空间,用来存储'黄财财'2. 将'黄财财'所在的内存空间地址,绑定给到name变量3. 如果要访问'黄财财',则直接通过name变量访问即可'''name = '黄财财'print(name)# 如果此时将另外一个内存地址绑定给到name变量,则原本的'黄财财'被pass掉,最后输出新的值name = '变量值'print(name)'''综上所述:1. 变量通过赋值,来进行数据的存储2. 调用变量,实质意义上就是调用变量所指向的内存地址中的值3. 一个变量在同一时间内只能指向一个值,如果对其进行多次赋值,则保留最后一次的赋值内容拓展:多个变量可以指向同一个内存地址,也就是多个变量可以赋值同一个内存空间的值。'''name = name1 = '黄财财'print(id(name), id(name1))# 输出结果 id(name) = 8553264 , id(name1) = 8553264,两个地址相同
每一个变量在使用前都必须要先赋值,不然就会抛出异常
数据类型
在Python中,我们不需要在定义变量时声明变量所属的数据类型,而是在我们对变量赋值时,基于值本身的数据类型来确定变量的数据类型,所以我们在做变量与变量间的计算和处理时,必须要基于变量的值来判断是否能够共同处理,以及该用什么方法来处理。
想要正确地处理变量值,我们需要先搞清楚Python中的各种数据类型。在Python中有标准的六大数据类型,我们可以通过type()来查看当前数据属于什么数据类型。
Number(数字)
'''在python中,所有的数字都属于Number类型,不管是int、float、bool,还是complexbool类型只有True和False两个值,在Number中,True表示1,False表示0complex类型,我个人很少用到,以后如果有用到再具体说明吧。'''a, b, c, d = 10, 1.1, True, 4 + 3jprint(type(a), type(b), type(c), type(d))# 输出结果:<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
String(字符串)
'''在python中,字符串用单引号''或者双引号""括起来,如果遇到特殊字符,则通过反斜杠\进行转义。\是转义字符,将特殊字符以原文进行输出。避免因为特殊符号导致原文解析出现问题。'''str1 = '单引号字符串'print(str1)str2 = "双引号字符串"print(str2)str3 = '这是带\'单引号\'的字符串' # 字符串的内容包含有单引号,但是单引号本身是特殊字符,所以用\将字符串中的单引号转义为普通字符print(str3)str4 = '这是带"双引号"的字符串' # 因为str4是用单引号括起来的,所以内部的引号用双引号,这样两者就不会冲突,双引号可以正常输出print(str4)str5 = r'这是带有\的字符串' # 如果遇到带有\的字符串,可以在字符串前加上r,表示为原文输出,这样也可以实现转义
List(列表)
'''在Python中,列表是用中括号[]括起来,用以实现大多数集合类的数据结构。列表中的内容都是以元素来定义,一个列表可以包含多个元素,元素可以是不同的数据类型,不同元素间用逗号,进行分隔获取列表中的元素内容时,通过下标来获取,下标的计算是从0开始的,所以说,如果列表有10个元素,则最大下标值为9。通过在列表变量名称后添加中括号,在中括号中写入下标值来获取该列表中对应的元素:el = li1[0]需要注意,如果列表本身下标最大为9,如果获取元素时填入了下标10,则代码运行会抛出异常IndexError: list index out of range,表示下标越界'''# 创建一个空列表li = list() # print(li)的结果:[] 这表示li是个空的列表# 创建一个有值列表li1 = [123, '黄财财', 1.1] # print(li1)的结果:[123,'黄财财',1.1]# 获取列表中的第一个元素el = li1[0] # print(el)的结果: 123 这表示成功获取到第一个元素
Tuple(元组)
'''在Python中,元组类型tuple与列表类型list在使用上是相似的,都是基于下标操作元素,一个元组中可以包含各种不同类型的元素。tuple类型是基于圆括号()将元素进行包裹。下标也是从0开始取。元组的元素获取与列表一样,如果下标超过最大值,同样会抛出异常IndexError: tuple index out of range'''# 创建一个空元组tu = tuple()# 创建一个有值元组tu1 = (123, '黄财财', 1.1)# 获取元组中指定下标元素el = tu1[1]print(el) # print结果:黄财财el1 = tu1[4] # 抛出异常IndexError: tuple index out of range
Set(集合)
'''在Python中,集合类型set,与数学中的集合是一个概念。用来保存不重复的元素,也就意味着一个集合中,所有的元素都是唯一的,互不相同。set类型是基于大括号{}将元素进行包裹,不同元素间用逗号进行分隔,集合内的元素是无序的。'''# 创建一个有值的集合se = {1, 2, 'a', 'c', '黄财财'}print(se) # 实际输出执行三次,结果分别为:{1, 2, '黄财财', 'a', 'c'},{1, 2, 'c', 'a', '黄财财'},{1, 2, 'a', '黄财财', 'c'}# 通过set函数创建集合se1 = set("我是黄财财")print(se1) # 实际输出结果:{'黄', '我', '财', '是'}
Dictionary(字典)
'''在Python中,字典类型dictionary,在python3.5版本之后,都是有序保存的,具备有键值对形态的一种集合。同一个字典中,所有的键都是唯一的。dict类型与set类型一样,都是基于大括号{}将每一组键值对进行包裹,不同组别间使用逗号进行分隔,获取字典内的指定键值对,都是基于键来获取。'''# 创建一个空字典di = dict()print(di) # 实际输出结果:{}# 创建一个有值字典di1 = {"name": "黄财财","age": 18,"sexual": "male"}print(di1) # 实际输出结果:{'name': '黄财财', 'age': 18, 'sexual': 'male'}# 基于字典的键(key)来获取对应的值(value)print(di1['name']) # 实际输出结果:黄财财
运算符
在代码编写过程中,经常会需要应用到各类运算,比如基本的加减乘除等,这些符号,就是Python中的运算符。并且,在Python中,运算符有非常多的类型,具体内容如下:
算数运算符
+,表示两个对象相加
# + 运算符a = 1b = 2c = a + b # 对象a与对象b相加,即 1 + 2,c的结果为3d = 3 + 4 # 数字3与数字4相加,d的结果为4e = '黄' + '财财' # 两个字符串相加,表示拼接的意思,及'黄'与'财财'进行拼接,e的结果为'黄财财'f = [1, 2] + ['黄', '财财'] # 两个集合相加,最终会组合成一个新的集合,f的结果为[1, 2, '黄', '财财']print(c, d, e, f) # 实际输出结果:3 7 '黄财财' [1, 2, '黄', '财财']
-,得到负数或者是一个数减去另一个数
# - 运算符c = 1 - 2print(c) # 实际输出结果:-1
*,两个数相乘,或者是将一个特定字符串重复指定次数
# * 运算法c = 3 * 3d = '黄财财' * 5 # 重复'黄财财'字符串5次print(c, d) # 实际输出结果:9 黄财财黄财财黄财财黄财财黄财财
/,两者相除,若有余数则显示余数
# / 运算符c = 1 / 3d = 6 / 2print(c, d) # 实际输出结果:0.3333333333333333 3.0e = 3 / 0 # 因为除数不能为0,所以会报错:ZeroDivisionError: division by zero
其他运算符
# % 运算符,返回除法中的余数,没有余数则返回0c = 10 % 4d = 6 % 2print(c, d) # 实际输出结果:2 0# ** 运算符,返回x的y次幂c = 10 ** 2 # 表示为10 * 10print(c) # 实际输出结果:100# // 运算符,除法返回商的整数部分(向下取整)c = 9 // 2 # 实际结果为4...1,向下取整,结果为4d = -9 // 2 # 实际结果为-4...-1,向下取整,结果为-5print(c, d) # 实际输出结果:4 -5
比较(关系)运算符
==表示对比两个对象是否相等
!=表示两个对象是否不相等
\>,\>=表示大于或大于等于
<,<=表示小于或小于等于
'''Python 比较运算符代码示例,比较运算只有正确和失败两个结果,所以返回值为True和False整体内容与基本的数学概念差别不大,所以一起展示'''# == 运算符,需要注意,一个=表示赋值,两个=表示对比print('黄财财' == '黄财') # Falseprint('黄财财' == '黄财财') # True# != 运算符print('黄财财' != '黄财财') # Falseprint('黄财财' != '黄财') # True# <,<=运算符print(1 <= 2) # Trueprint(2 < 1) # False# >,>=运算符print(1 >= 2) # Falseprint(2 > 1) # True
赋值运算符
'''Python中的赋值运算符,主要列举最常应用的内容如=、+=、-+其余内容只是简单介绍,不做过多讲解'''# = 运算符:仅能够进行赋值操作,将右边的值赋值给到左边的对象。已做过讲解# a = 1# b = 1 + 2# += 运算符:加法赋值运算符a = 1print(a) # 实际输出结果:1a += 2 # 等同于 a = a + 2print(a) # 实际输出结果:3# -= 运算符:减法赋值运算符,与加法赋值运算符相同a = 2print(a) # 实际输出结果:2a -= 1 # 等同于 a = a - 1print(a) # 实际输出结果:1# 也有 *=、/=、%=、**=、//=这一类的赋值运算符,与前面描述的加法或减法运算符是一样的。
逻辑运算符
'''Python中的逻辑运算符,主要用于做条件判断,具体有三种不同的逻辑所有逻辑判断都只有两个结果,成立(返回True),不成立(返回False)1. and:表示与,表达式示例:x and y,x与y之间,任意一个为False,则返回False2. or:表示或,表达式示例:x or y,x与y之间,任意一个为True,则返回True3. not:表示非,表达式示例:not x,不为x,则返回True'''# 三类逻辑运算示例print(True and False) # 实际输出:Falseprint(True or False) # 实际输出:Trueprint(not True) # 实际输出:False'''三类逻辑运算进阶:1. and: 若x,y都为True时,x and y会返回y的值2. or:若x为True时,x or y会返回x的值'''# a = Falsea = 1# b = Falseb = 2# andprint(a and b) # a为False,则实际输出:False,a为1,则实际输出:2# orprint(a or b) # a为False,则实际输出:2,a为1,则实际输出:1# notprint(not b) # b为False,则实际输出:True,b为True,则实际输出:False
位运算符
只能用来操作整数类型,它按照整数在内存中的二进制形式进行计算,在自动化测试领域中可以忽略
成员运算符
'''Python中的成员运算符,用来识别成员是否在或不在指定的内容之中1. in:表达式 x in y,如果x在y之中,则返回True,否则返回False2. not in:表达式 x not in y,如果x不在y之中,则返回True,否则返回False'''a = '黄财财'b = '黄'c = 'caicai'# inprint(b in a) # 因为'黄'在'黄财财'之中,所以实际输出结果为Trueprint(c in a) # 因为'caicai'不在'黄财财'之中,所以实际输出结果为False# not inprint(c not in a) # 因为'caicai'不在'黄财财'之中,所以实际输出结果为Trueprint(b not in a) # 因为'黄'在'黄财财'之中,所以实际输出结果为False
身份运算符
'''Python中每个对象都有属于自己的id值,查看id值的方法为id()身份运算符就是判断对象的id值是否一致。身份运算符:同身份运算符is当两个变量指向的是同一个对象,则返回为True,否则返回为False非同身份运算符is not当两个变量指向的是同一个对象,则返回False,否则返回为True'''# 定义基本的变量a = 1b = 2c = aprint(id(a))print(id(b))print(id(c))print(a is c) # Trueprint(a is not b) # True# 对于数值与字符对象,相同的值通常身份也相同,但列表相同,身份通常是独立的l = []s = []print(l is s) # Falseprint(l is not s) # True
运算符优先级
与数学概念类似,先算乘除再算加减,有括号就先算括号里面的。
还有很多比较复杂或者相对麻烦的运算符优先级的逻辑概念,但这些,基本在自动化中应用不上,所以暂时可以忽略。对数学有兴趣可以自行了解一下。
String字符串
访问字符串中的值
在字符串中,如果想要访问字符串内指定的子字符串,可以通过方括号来截取字符串,可截取单个或者多个内容,依据下标来进行指定内容的选择,下标从0开始进行计数。具体代码如下:
string1 = 'hello word'string2 = 'huang cai cai'# 截取单个字符串的值print(string1[0])# 截取多个字符串的值print(string2[1:5])
字符串拼接
在字符串中,也可以将多个字符串进行拼接,通过‘+’进行拼接。具体代码如下:
string1 = 'huang cai cai'# 字符串与字符串之间的连接,通过+进行print(string1 + 'Python')
转义字符
在字符串中,如果包含有特殊字符,例如#、‘’、""等,如果不进行特殊字符的转义,则会因为这些特殊字符对原有字符串影响,从而导致代码报错。Python默认的转义字符是'\\'。对特殊字符的转义处理如下:
# 1. 通过切换单双引号对包含有引号的内容进行处理string1 = '"Hello World" ——世界上最伟大的代码'string2 = "'Python是最好的编程语言'——黄财财说的"print(stirng1)print(string2)# 2. 转义字符\对特殊字符进行处理,加上\的引号将作为字符串进行输出string3 = '鲁迅先生说:\'世上本无路,走的人多了自然就有路了。\''print(string3)# 3. 对转义字符\进行处理,在转义字符\前,再加一个\,则可以将\作为字符串进行输出string4 = 'C:\\Users\\HuangCaicai\\chrome.exe'print(string4)
字符串的格式化
如果在使用过程中需要将值插入字符串之中,可以通过占位符的形式来进行插入,虽然用法相对复杂一些,但可以很好地进行格式化输出。具体代码如下:
string1 = 'Huangcaicai'string2 = 'Dota2'# 在原有字符串中,进行格式化输出,将定义的变量传入字符串内容。print('我是{0},我最喜欢打的游戏叫做{1}'.format(string1,string2))# 也可以直接使用字符串进行传入print('这里是{}带来的Python教学。'.format('黄财财'))
字符串的三引号
在字符串处理中,可以通过三引号对复杂的字符串进行处理。三引号允许一个字符串跨多行,同时字符串中可以包含各类特殊字符,用法与多行注释类似。此类方式对于SQL、HTML等内容的输出会特别方便。具体代码如下:
# 三引号字符串使用string1 = '''<html><header></header><body><input type="text" id="AutoTest" name="huangcaicai"/></body></html>'''# 输出内容可以将所有的特殊字符正常输出,再也不用再为各类特殊字符费神啦~print(string1)
字符串内置常用函数
字符串除去基本的处理行为外,也内置有很多函数,强化了关于字符串类型的功能。也很大程度提升了对字符串的操作。
encode与decode
Python对字符串本身有默认的编码格式,有时因为编码格式的不正确,会导致原本的内容出现乱码或者内容的改变,所以在这时需要进行转码,所以python提供有转码与编码的两种方法,可以将原有的内容进行指定编码格式的编码,以及基于指定编码格式来进行解码。具体代码如下:
# 定义一个普通字符串string1 = 'Huangcaica Python Class'# 将string1 转换编码为gbkstring2 = string1.encode(encoding='gbk')print(string2)# 将string2 以gbk编码格式进行解码print(string2.decode(encoding='gbk'))
upper与lower
在操作全部为字母的字符串时,如果需要对内容进行大小写的转换,可以通过调用upper()与lower()函数来实现,具体代码如下:
string1 = 'HuangCaiCai Python Class'# 将string1中的内容全部转换为大写string2 = string1.upper()print(string2)# 将已经全部转换为大写的string2中的内容全部转换为小写string3 = string2.lower()print(string3)
去除字符串中的空格
有时获取到的字符串内容中,会包含有很多的空格内容,在实际使用时,这些空格内容可能会对我们代码的逻辑产生影响。如果需要将空格去除,python中也提供有各类方法,来满足各种需求下,对于空格内容的去除。具体代码如下:
# 定义一个包含空格的字符串内容string = ' 黄财财真的 是在教Python 'print(string)# 去除字符串开头的空格内容print(string.lstrip())# 去除字符串结尾的空格内容print(string.rstrip())# 去除字符串中首尾的空格内容print(string.strip())# 去除字符串中所有的空格内容print(string.replace(' ', ''))
replace字符串内容替换
在前面有使用replace()函数实现去除所有空格的功能,但实际上replace()的主要作用是将字符串中指定的内容替换为其他内容,可以传入三个参数,old表示被替换的字符;new表示替换后的字符;count表示替换次数,默认为所有,指定count值,则只会替换count值定义的次数。具体代码如下:
# 定义一个字符串string = '000000000who 00are you0000!'# 将字符串中所有的0替换为空值print(string.replace('0', ''))# 将字符串中的0替换为xprint(string.replace('0', 'x'))# 将字符串中的0替换为空值,只替换5次print(string.replace('0', '', 5))
strip去除字符串首尾指定内容
strip()默认可以去除字符串首尾的空格,相当于同时执行了lstrip()和rstrip(),但同时strip()也提供有另外一个功能,可以去除字符串首尾指定的内容,只需要在调用strip()时传入一个参数,chars表示指定去除的字符串,但只在字符串的开头与结尾进行去除,其余地方不会去除。具体代码如下:
# 定义一个字符串string = '00000huang0000caicai0000'# 通过strip函数去除string中首尾存在的0print(string.strip('0'))
find查找字符串中是否包含指定内容
find()通过传入一个参数,str表示指定内容,可实现对当前字符串进行指定内容的查找,如果查找到str内容,则返回开始的索引值,如果未找到,则返回-1。具体代码如下:
# 定义一个字符串string = 'this is huangcaicai'# 通过find查找字符串中是否包含huangcaicai,存在,则返回开始的索引值print(string.find('huangcaicai'))# 通过find查找字符串中是否存在黄财财,不存在,则返回-1print(string.find('黄财财'))
split字符串切片
split()可以实现对现有字符串进行切片,通过指定分隔符将原有字符串进行分隔,按照要求切分为多个不同的字符串内容,也是非常常用的一个操作行为。split()包含有两个参数,sep表示指定分隔符,默认为所有的空字符,包括空格、换行等;maxsplit表示分隔次数,默认为-1,即分隔所有。具体代码如下:
# 定义一个字符串string = 'this is huangcaicai'# split函数调用,分割后会以list格式返回结果# 不传入参数,会基于空格进行分割print(string.split())# 设置基于i进行分割,不设置分割次数print(string.split('i'))# 设置基于i进行分割,设置只分割一次print(string.split('i', 1))
join连接字符串
join()用于将指定序列中的元素以指定的字符连接生成一个新的字符串,并返回。具体代码如下:
# 通过逗号将list中的元素进行分割,拼接为一个新的字符串print(",".join(['a', 'b', 'c']))# 通过join函数将list中的内容拼接为一个新的字符串print("".join(['a', 'b', 'c']))
List常用操作
list列表是一个可以包含任意内容的序列,序列中的每一个元素都会分配一个下标来指定它的位置。下标默认从0开始,第一个下标为0,第二个为1,以此类推。不同的元素之间互不冲突,都是各自独立的存在。作为Python中最常用的数据类型之一,也提供有很多的操作行为与内置函数。
List基本使用与常用函数
list的声明
list声明与int和string的声明不一样,可以声明一个有值或者空值的list对象,具体代码如下:
# 声明有值的listli = ['huangcaicai', 'python', 8888, 123456]# 声明无值的listli = list()
访问列表中的元素
通过下标来获取指定的单个或者多个元素,进行元素的访问。具体代码如下:
# 创建一个list列表li = ['huangcaicai', 'python', 8888, 123456]# 获取指定下标的元素print(li[0])# 获取多个下标的元素print(li[0:3])# 获取list中倒数第二个值print(li[-2])# 获取list中从第二个到最后一个值print(li[1:])# 获取list中从第一个到倒数第二个值print(li[:-1])
对列表进行元素的添加
可以通过调用append()函数来实现对list中添加新的元素,append()需要传入一个参数,object表示添加的内容,可以是任意数据类型。具体代码如下:
# 创建一个list列表li = ['huangcaicai', 'python', 8888, 123456]# 对li进行元素的添加li.append('zxc')li.append(22222)print(li)
对列表进行元素的修改
list类型支持对已有的元素进行值的修改,实现方式是通过调用list的下标,获取指定元素,然后通过等号赋值新的内容,从而实现对元素值的修改。具体代码如下:
# 创建一个list列表li = ['huangcaicai', 'python', 8888, 123456]# 对li的指定元素进行修改li[1] = 'Python'print(li)
对列表进行元素的删除
list中,如果需要对已存有的值进行删除,可以通过del关键字或者remove()函数来进行删除,删除的操作都是基于下标或者元素值来实现的。一次只能删除一个对应元素。具体代码如下:
# 创建一个list列表li = ['huangcaicai', 'python', 8888, 123456]# 通过del关键字对li进行元素的删除del li[1] # del关键字删除是基于元素下标,将指定的下标元素进行删除print(li)# 通过remove()函数对li进行元素的删除li.remove(8888) # remove()函数删除是基于元素值,将首个匹配的元素进行删除,只执行一次print(li)
获取列表的长度
有些时候,list会根据代码逻辑去添加数据,我们也无法清晰知道list的具体内容和长度会是多少,所以会通过len()来获取到指定list的长度,再通过长度去查看list之中的具体元素。具体代码如下:
# 创建一个list列表li = ['huangcaicai', 'python', 8888, 123456]# 获取当前list的长度print(len(li))
当前列表对值进行排序
list本身会根据值添加的先后顺序进行默认排序,我们也可以使用sort()函数对list进行重新排序,排序后会完全改变list值的顺序。但sort()函数在调用时,list必须为同一种数据类型才可以进行排序。如果list中有不同的数据类型,调用sort()时会报错。
sort()会将原有的列表元素排列顺序进行改变,如果不想改变顺序,可以通过调用sorted()函数临时修改列表的元素排列顺序。sorted()排序也要求list必须为同一种数据类型才可以进行排序。如果list中有不同的数据类型,调用sorted()时也会报错。
具体代码如下:
# 创建三个list列表li1 = ['huangcaicai', 'python', 8888, 123456]li2 = [3, 2, 123, 654]li3 = ['是', '黄财财', 'asdas']# 对统一为int类型的li2进行排序li2.sort()print(li2)print(sorted(li2))# 对统一为string类型的li3进行排序li3.sort()print(sorted(li3))# 对数据类型不统一的li1进行排序li1.sort()print(li1) # 结果会报错print(sorted(li1)) # 结果会报错
将多个列表合并为一个列表
对单个list添加元素是我们经常遇到的一种场景,有时候因为程序本身的逻辑原因,可能我们需要添加的不再是单个的元素,而是将一整个新的list与现有的list合并。具体代码如下:
'''list中提供有extend()函数来实现将新的list添加到现有的list中,但只支持两个list合并如果有两个以上list需要合并,其实直接通过+来合并会更加简单。不过需要注意,list默认是不会将重复元素去除的。如果需要实现去重,需要用到其他技术'''# 创建三个list列表li1 = ['huangcaicai', 'python', 8888, 123456]li2 = [3, 2, 123, 654]li3 = ['是', '黄财财', 'asdas']# 通过+合并多个listli4 = li1 + li2 + li3print(li4)# 通过extend()函数实现两个list的合并li1.extend(li2)print(li1)
反向list中的元素
python编程除去我们自己的编码基本使用,有时候面试或者做python题的时候,会需要用到一些不太常用的操作,比如说将原有list中的元素反过来排序。具体代码如下:
# 创建list列表li1 = ['huangcaicai', 'python', 8888, 123456]# 反向list中的元素,重新进行排序li1.reverse()print(li1)
Set常用操作
Set用来表示一个无序不重复元素的序列,在python中,set主要作用是用来给数据进行去重。
set集合的创建与使用
set集合创建
创建set集合,通过大括号{}或者set()函数来进行创建,如果需要创建空集合,则必须调用set()来实现。因为大括号{}是用来创建空字典的。具体代码如下:
# 使用set()创建空集合set1 = set()print(set1)# 使用set()创建有值集合set2 = set(('a', 'b', 'c', 'd'))print(set2)# 使用{}创建有值集合set3 = {1, 2, 3, 4, 5, 6}print(set3)# 集合默认去重set4 = {1, 2, 3, 4, 5, 4, 3, 2, 1}print(set4)
set集合添加元素
set集合中,通过add()实现对现有集合进行新元素的添加,一次只可以添加一个元素。具体代码如下:
# 使用set()创建空集合set1 = set()# 添加元素进入到set1中set1.add('sss')print(set1)
set集合删除元素
set集合中,可以通过discard()对指定元素进行删除,需要传入一个参数,element表示指定的元素对象。也可以通过pop()进行随机元素的删除。如果需要对整个集合内容全部删除,则可以通过clear()实现。具体代码如下:
# 使用{}创建有值集合set3 = {'a', 'b', 'c', 'd', 'e', 'f'}# discard()删除指定元素set3.discard('c')print(set3)# pop()删除随机元素set3.pop()print(set3)# clear()清空所有元素set3.clear()print(set3)
set集合判断指定对象是否为集合中的元素
set集合中,可能存有大量数据,我们需要去判断某一个值是否为当前集合中的元素,可以通过调用in关键字来实现判断。具体代码如下:
# 使用{}创建有值集合set3 = {'a', 'b', 'c', 'd', 'e', 'f'}# in判断指定内容是否是集合中的元素print('a' in set3) # 存在返回Trueprint(1 in set3) # 不存在返回False
set交集
两个或多个set集合之间如果存有交集,可以通过intersection()函数来进行计算。具体代码如下:
# 创建有值集合set1 = set(('a', 1, 3, 'd'))set2 = {1, 2, 3, 4, 5, 6}set3 = {1, 2, 3, 4, 5, 4, 3, 2, 1}# 判断两个集合间的交集print(set1.intersection(set2))# 判断多个集合间的交集,多个集合传入通过逗号区分print(set3.intersection(set1, set2))
set差集
set集合中,可以通过difference()对两个集合进行差集的获取,会返回一个新的集合,返回的集合元素包含在第一个集合中,但不包含在第二个集合(即参数)中。
拓展内容:
set中还有difference_update()函数,用于移除两个集合中都存在的元素。
difference_update() 方法与 difference() 方法的区别在于 difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。
具体代码如下:
# 创建有值集合set1 = set(('a', 1, 3, 'd'))set2 = {1, 2, 3, 4, 5, 6}# 判断两个集合间的差集,生成新的集合set3 = set1.difference(set2)print(set3)# difference_update()函数的使用示例# set1.difference_update(set2)# print(set1)set2.difference_update(set1)print(set2)
set并集
set集合中,可以通过union() 方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。也可做多个集合的并集。具体代码如下:
Dictionary字典常用操作
字典的创建与使用
字典的创建
字典是一种可变容器模型,可存储任意类型对象。基于键值对(key-value)形态进行数据的管理。
字典中每一个键值对都是通过冒号分割,每一对之间通过逗号分割。整个字典内容包含在大括号{}之中。
在字典中,key是唯一值,不可重复,而value则随意,可以是任意内容。
字典在创建时,可以通过{}创建一个有值的字典,也可以通过dict()或者{}创建一个空值字典。
具体代码示例:
# 创建一个空字典di1 = dict()di2 = {}print(di1)print(di2)# 创建一个有值字典,key不可重复,不同键值对之间通过逗号分隔di3 = {'name': '黄财财','age': 18,'sexual': 'male'}print(di3)
访问字典中的内容
字典的内容访问,都是基于key来获取value的,在实际获取时,通过调用字典变量名,再通过[key]的方式来实现对应value的访问。具体代码实现如下:
# 创建一个有值字典,key不可重复,不同键值对之间通过逗号分隔di1 = {'name': '黄财财','age': 18,'sexual': 'male'}print(di1['name']) # 获取di1中name对应的value值print(di1['age']) # 获取di1中age对应的value值print(di1['sexual']) # 获取di1中sexual对应的value值
字典内容的修改
字典支持对内容进行新增或者修改,新增与修改的写法相同,区别在于key,如果输入的key原字典中不存在,则为新增键值对,若key存在,则对对应key的value值进行修改。具体代码如下:
# 创建一个有值字典,key不可重复,不同键值对之间通过逗号分隔di1 = {'name': '黄财财','age': 18,'sexual': 'male'}# 新增键值对di1['school'] = '黄财财专属课堂'print(di1)# 修改已有键值对di1['age'] = 28print(di1)
字典内容的删除
字典支持对整个字典内容删除,也可以对指定键值对进行删除。具体代码如下:
# 创建一个有值字典,key不可重复,不同键值对之间通过逗号分隔di1 = {'name': '黄财财','age': 18,'sexual': 'male'}# 删除指定键值对del di1['age']print(di1)# 清空整个字典内容di1.clear()print(di1)
字典常用函数
字典中会提供有很多不同的功能函数,来满足字典的各类编程需求,其中常用的方法都在下方具体代码中展示:
# 创建一个有值字典,key不可重复,不同键值对之间通过逗号分隔di1 = {'name': '黄财财','age': 18,'sexual': 'male'}# items()获取字典中的每一组键值对print(di1.items())# keys()获取字典中的所有keyprint(di1.keys())# values()获取字典中所有的valueprint(di1.values())
Tuple元组常用操作
tuple元组,与list列表相似。不同之处在于,列表是可以修改的序列,而元组中的内容是无法进行修改的。
元组的创建与使用
元组的创建
元组创建,通过()进行,可以创建有值或者空的元组。具体代码如下:
# 创建一个有值元组tuple1 = (1, 2, 3, 4, 5)print(tuple1)# 创建一个空值元组tuple2 = ()print(tuple2)# 元组中若只有一个值,需要添加逗号,不然()会被识别为运算符tuple3 = (1)print(type(tuple3)) # 显示tuple3为int类型tuple4 = (11,) # 如果创建一个元素的元组,则需要在元素后方添加逗号print(type(tuple4)) # 显示tuple4为tuple类型
元组访问元素
元组中的元素访问,与列表的操作类似,通过[]中输入元素的下标值进行访问,下标从0开始计算。
# 创建一个有值元组tuple1 = (1, 2, 3, 4, 5)# 获取元组中指定单个元素print(tuple1[0])# 获取元组中多个元素print(tuple1[1:4])
元组修改元素
元组中的元素不支持修改,但可以基于原有的元组内容,通过创建新的元组将内容进行改变。同理,元组中的元素也不支持被删除,但可以删除整个元组。具体代码如下:
# 创建一个有值元组tuple1 = (1, 2, 3, 4, 5)# 在原有元组上进行元素值的修改# tuple1[0] = 'aaa' # 会报错,因为元组无法被修改# 删除元组中的元素# del tuple1[0] # 会报错,因为元组不支持元素的删除。# 删除整个元组# del tuple1 # 可以正常删除整个元组。# 创建新的元组,增加新的值tuple2 = ('a',) + tuple1print(tuple2)
If判断控制流
代码在执行过程中,因为各类逻辑的运算,会需要经由各种条件进行判断,以确认代码的执行顺序,所以在编写代码的过程中,会涉及到逻辑的判断,而if就是对代码逻辑的判断语法。
If判断的使用
if判断一般的写法是基于if...else...的结构,当然,还有if...elif...else...的拓展语句。主要用于对程序的逻辑进行判断。理论描述过于复杂,通过具体代码展示如下:
'''If基本语法结构说明:if 条件:if语句块else 条件:else语句块当条件满足if时,进入if语句块代码执行,当条件不满足if时,进入else语句块执行。一个判断只会执行一次,要么if,要么else。'''a = True# if判断。if a is True:print('这里是if语句块') # 如果a为True,则进入此部分else:print('这里是else语句块') # 如果a不为True,则进入此部分'''if进阶:elif语法if 条件1:if语句块elif 条件2:elif语句块elif 条件3:elif语句块else:else语句块if...elif...else语法结构,也只会执行一次,如果满足if判断,则执行if语句块,其余内容不再执行,若不满足if,则判断elif,若都不满足,则进入else。'''a = Trueb = Falseif a is True:print('这里是a代码块')elif b is False:print('这里是b语句块')else:print('这里是else语句块')'''if语句单条件语法:if 条件:if语句块在if语法结构中,if可以单独使用,也可以关联elif使用,else不是必须项。若判断条件都不满足,则不会进入if之中。'''a = Trueb = False# 不添加else的if判断写法if a is False:print('这是a语句块')elif b is False:print('这是b语句块')'''pass关键字,在if判断语法中,用于表示略过。一般在判断过程中,如果不需要执行额外代码的情况下,可以调用pass实现。'''a = Trueif a is True:passelse:print('这是else语句块')
For控制流
循环,是编程语言中非常常用的一种语法结构。主要用于对单行代码或者一个代码块进行重复运行。
在Python中,循环语法结构一般是基于For循环或者是While循环的形式来实现。一般用于获取序列所有值,或特定代码的重复执行时,会使用到。
for循环的使用
循环中的一种语法。用于重复执行多次同一行代码或者代码块。具体代码示例如下:
'''For循环语法结构:for 条件:循环块'''li = [1, 2, 3, 4, 5, 6, 7]# 循环读取list中的所有元素for i in li:print(i)'''内置函数range()的使用:range函数可以创建一个临时的整数列表。一般用在for循环中。range(start, stop[, step])中,start是开始计数,stop是停止,step是步长range(0,5)生成[0,1,2,3,4]range(0,5,2)生成[0,2,4]'''# 基于range()实现的循环for i in range(0, 5):print(i)for i in range(0, 5, 2):print(i)'''break与continue关键字用法:在循环中,可以通过break退出整个循环;或者通过continue退出本次循环。'''# break用法:当i为3时,整个for循环全部结束,后续的循环不再执行for i in range(0, 5):if i == 3:breakprint(i)# continue用法:当i为3时,本次循环结束,continue后面的代码不再执行,进入新的一轮循环。for i in range(0, 5):if i == 3:continueprint(i)
While循环
Python编程中,除去for循环外,还有While循环体系。在特定场景下,也会使用到。整体逻辑与for循环差不多。但在语法上会存有区别。
While循环用法
在掌握基本的循环概念之后,While用法会更容易理解,且While循环对重复大量次数的逻辑运行可以更好支持。但要避免在使用while时出现死循环。具体代码如下:
'''While循环语法结构:while 判断条件:while循环体使用while时,需要避免死循环。导致程序无法正常执行。死循环:一直在循环体中,无限执行循环,无法跳出循环。while循环也支持break跳出循环,continue跳出本次循环。'''# while示例:基于a的增长,循环判断a<10的条件是否成立,如果成立则持续运行循环,直到不满足为止。a = 1while a < 10:print(a)a += 1if a == 3:continue# 死循环示例:因为True条件一直成立,所以会在循环中无法结束,从而导致死循环。# while True:# print(a)# a += 1# 为避免出现死循环,所以在while循环时,考虑判断条件的设定,以及通过设置break来处理while True:print(a)a += 1if a == 20:break # 满足判断则结束循环

关注作者微信公众号 —《蜀道衫》
了解更多软件测试开发知识以及最新面试宝典

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python装饰器:怎么让代码在不改变结构的情况下获得新能力
- 【第40期】21天养成编程习惯:Python刷题第18天
- 27届秋招嵌入式驱动岗,这10个Linux问题,面试官能追到probe
- Python爱心代码 | 零基础也能运行的浪漫爱心动画教程
- Python资源释放+JSON序列化:AI伴侣会话管理核心技术
- Bun.$执行python代码?
- 【往期回顾】Python 潮流周刊#105:Dify突破10万星、2025全栈开发的最佳实践
- Python 课程同步笔记|Python 所有核心数据类型,一篇彻底吃透(含实战场景+避坑指南)
- OS24.【Linux】进程终止
- 还在手动回邮件?用Python搭建邮件自动回复机器人,解放你的双手…
