学生数据还能这样用:Python + 大模型实现个性化教育推荐
- 2026-06-29 20:52:48
很多学校系统里都有学生数据,比如成绩、考勤、消费、班级、学科明细等。但这些数据如果只是停留在表格里,老师通常只能看到“谁分数高、谁分数低”,很难进一步判断:
这个学生是基础薄弱,还是成绩波动大? 他需要补弱、拔高,还是需要学习习惯提醒? 推荐学习资源时,应该根据成绩推荐,还是根据综合画像推荐? 大模型能不能参与生成个性化建议,但又不乱编?
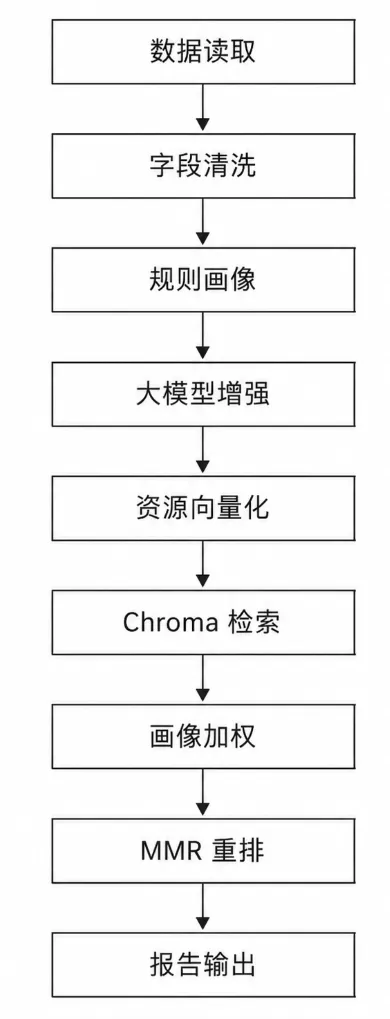
基于这些问题,我用 Python 做了一个学生画像与教育资源推荐实验。这个项目不是简单地调用大模型写几句话,而是把数据处理、规则画像、大模型增强、向量检索、推荐重排和报告输出串成了一条完整流程。
整套流程大致如下:
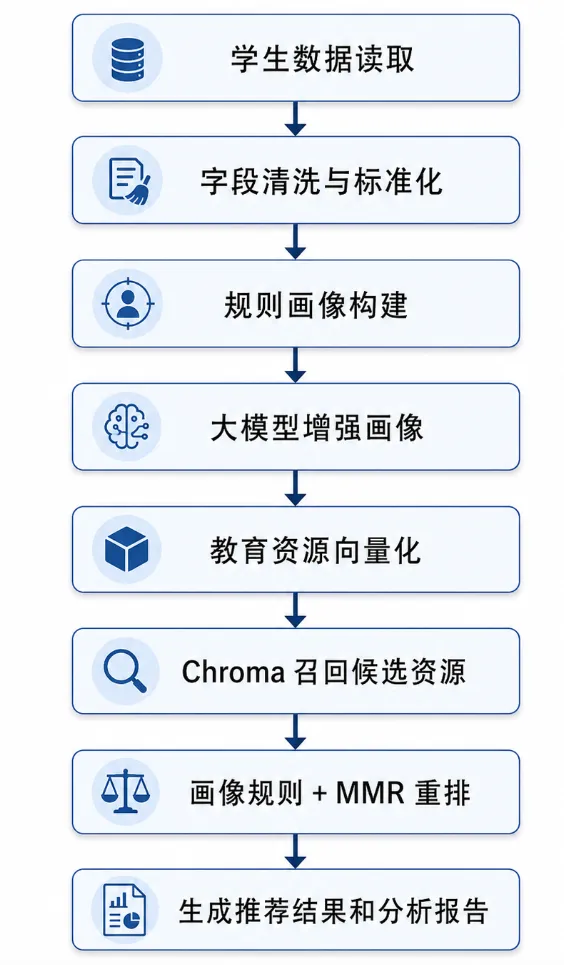
1. 实验目标:让学生数据从“表格”变成“画像”
本次实验的目标是基于 Python 实现一个简化版学生画像推荐系统。输入是学生基础数据和成绩明细数据,输出是学生画像、个性化教育资源推荐结果和运行报告。
实验主要完成以下任务:
使用 pandas 读取学生基础数据; 对原始字段进行统一命名和类型转换; 根据成绩、稳定性、考勤和消费构建规则画像; 使用大模型生成学生优势、风险、行动建议和家校沟通建议; 使用 embedding 模型将教育资源和学生画像转成向量; 使用 Chroma 向量数据库召回候选资源; 使用画像规则和 MMR 算法对推荐结果进行重排; 使用 Pydantic 校验大模型输出,减少格式不稳定问题; 输出 JSON 运行摘要、Markdown 推荐报告和画像分布图。
本次实验是基于 Python 完成的,主要环境如下:
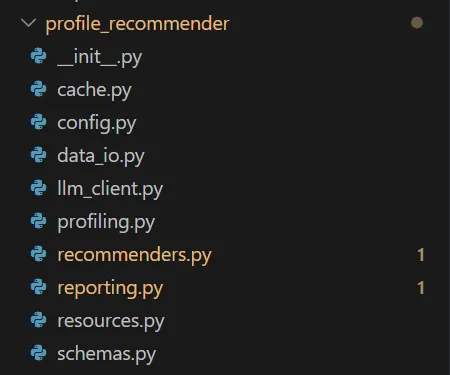
2. 项目结构:先把功能拆开,不要写成一个大脚本
这个项目的代码结构比较清晰,每个文件负责一个独立功能:
config.py # 管理数据目录、模型名称、随机种子等配置data_io.py # 读取学生数据、清洗字段、保存表格profiling.py # 根据规则生成学生画像llm_client.py # 封装大模型和 embedding 调用resources.py # 构造默认教育资源库recommenders.py # Chroma 向量检索 + 推荐重排schemas.py # Pydantic 校验大模型输出cache.py # 文件缓存,减少重复调用reporting.py # 输出 JSON、Markdown 和图表
这种拆法有一个好处:每个模块只做一件事。
比如,data_io.py 不关心怎么推荐,只负责把数据读干净;profiling.py 不关心大模型接口,只负责把数值指标转成画像标签;recommenders.py 只关注资源召回和排序。
这比把所有逻辑写在一个 main.py 里更容易维护。
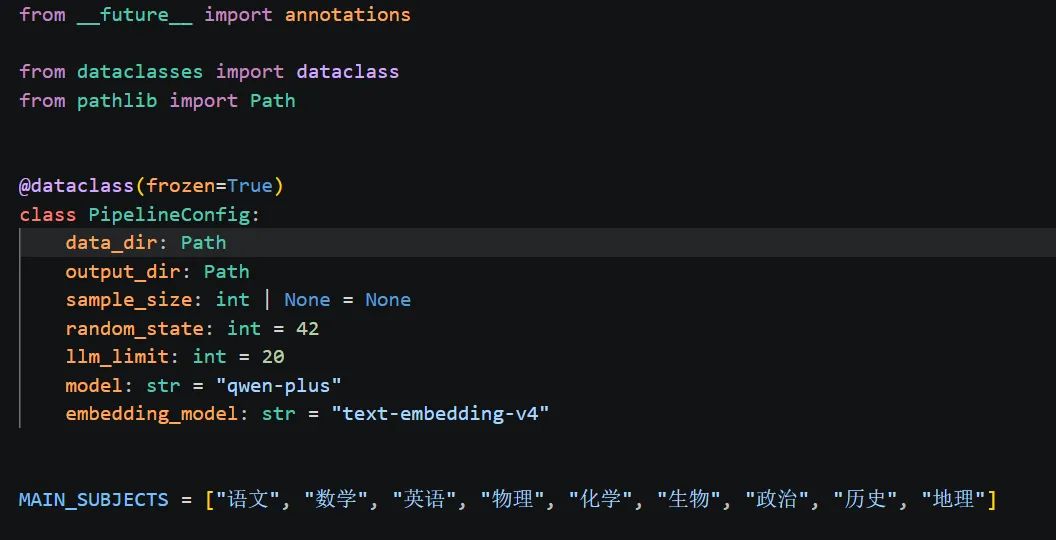
3. 配置管理:用 PipelineConfig 管住实验参数
实验的第一步不是直接读数据,而是先把运行参数集中起来。代码中使用了 dataclass 定义配置对象:
from dataclasses import dataclassfrom pathlib import Path@dataclass(frozen=True)class PipelineConfig:data_dir: Pathoutput_dir: Pathsample_size: int | None = Nonerandom_state: int = 42llm_limit: int = 20model: str = "qwen-plus"embedding_model: str = "text-embedding-v4"
这段代码虽然不长,但很重要。
其中:
data_dir: Pathoutput_dir: Path
分别表示输入数据目录和输出结果目录。
sample_size: int | None = Nonerandom_state: int = 42
用于控制抽样数量和随机种子。如果实验数据量较大,可以先抽一部分样本测试流程。
llm_limit: int = 20用于限制大模型处理数量。这个设计很实用,因为大模型调用通常有成本,也可能受限于接口速率。实验阶段没有必要一次性调用全部学生数据。
model: str = "qwen-plus"embedding_model: str = "text-embedding-v4"
分别指定文本生成模型和向量模型。
这里我认为比较好的地方是:代码没有把模型名称写死在推荐函数里,而是放在配置中。后续如果要把 qwen-plus 换成其他模型,只需要修改配置,不需要改核心逻辑。
代码中还定义了主要学科列表:
MAIN_SUBJECTS = ["语文", "数学", "英语", "物理", "化学", "生物", "政治", "历史", "地理"]这个列表后面会用于薄弱学科分析。
4. 数据读取:先解决“字段不统一”的问题
学生数据读取由 data_io.py 完成。这里的核心函数是:
def load_student_base(data_dir: Path) -> pd.DataFrame:wide_path = data_dir / "analysis_wide_modeling.csv"if wide_path.exists():df = pd.read_csv(wide_path)return _normalize_wide_modeling(df)student_path = data_dir / "2_student_info.csv"if student_path.exists():df = pd.read_csv(student_path)return _normalize_raw_student_info(df)raise FileNotFoundError(f"未找到可用数据。请把 analysis_wide_modeling.csv 或原始 7 表放到: {data_dir}")
这段代码体现了一个很实用的数据读取策略: 优先读取已经加工好的宽表 analysis_wide_modeling.csv;如果宽表不存在,再读取原始学生信息表 2_student_info.csv。
也就是说,代码不是只支持一种输入,而是提供了一个兼容方案。
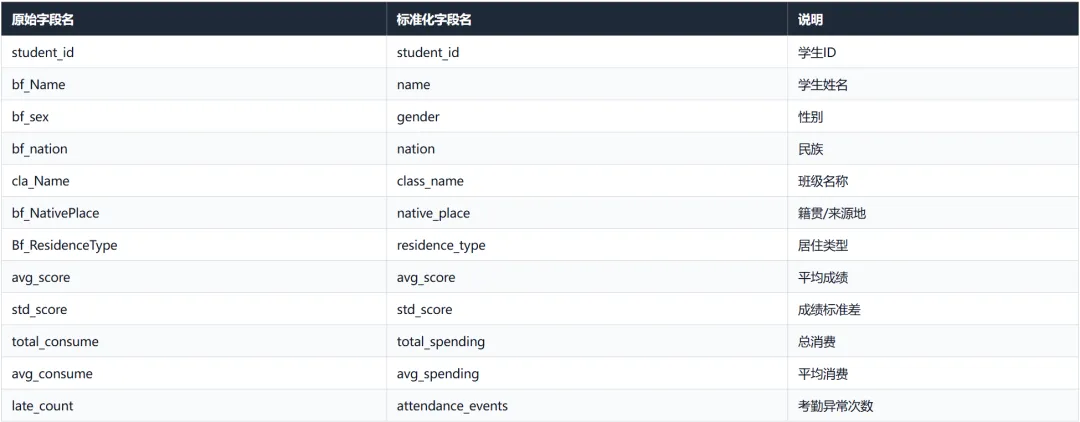
读取数据之后,真正关键的是字段标准化:
rename_map = {"student_id": "student_id","bf_Name": "name","bf_sex": "gender","bf_nation": "nation","cla_Name": "class_name","bf_NativePlace": "native_place","Bf_ResidenceType": "residence_type","bf_zhusu": "boarding","avg_z_score": "avg_zscore","total_consume": "total_spending","avg_consume": "avg_spending","consume_count": "spending_count","late_count": "attendance_events","consume_level": "consume_level_raw","score_level": "score_level_raw",}
原始字段名如 bf_Name、cla_Name、avg_consume、late_count,如果直接用于后续分析,可读性比较差。因此代码统一转换成:
nameclass_nameavg_spendingattendance_events
这样后续构建画像时,就可以直接看出字段含义。
除了重命名,代码还保留了一些已经加工好的指标:
passthrough = ["avg_score","std_score","max_score","subject_std","age","teacher_list","subject_list"]
这些字段中,avg_score 用于判断学业层级,std_score 用于判断成绩稳定性,subject_std 可以作为学科波动参考。
接着,代码对数值字段做类型转换:
for col in ["avg_score","std_score","subject_std","avg_spending","total_spending","spending_count","attendance_events"]:if col in out.columns:out[col] = pd.to_numeric(out[col], errors="coerce")
这一步非常必要。因为 CSV 中的数字字段有时会被读取成字符串,如果不转换,后续计算分位数、排序、分箱时都可能出错。
最后,学生 ID 统一转成字符串:
out["student_id"] = out["student_id"].astype(str)这样可以避免学生 ID 被 pandas 误读成数字,导致前导零丢失或合并时类型不一致。
5. 成绩明细读取:给推荐补充“薄弱学科”依据
除了学生基础数据,代码还支持读取成绩明细数据:
def load_score_detail(data_dir: Path) -> pd.DataFrame | None:detail_path = data_dir / "analysis_wide_detail.csv"if not detail_path.exists():return None
这里有一个比较好的设计: 如果成绩明细文件不存在,函数直接返回 None,而不是让整个程序报错。
这意味着系统可以在“只有学生宽表”的情况下继续运行,只是无法补充薄弱学科分析。
代码只读取需要的字段:
usecols = ["student_id","mes_sub_name","score_clean","mes_Score","score_status",]
为了兼容不同数据版本,代码还会检查实际存在的字段:
available = pd.read_csv(detail_path, nrows=0).columnsusecols = [c for c in usecols if c in available]detail = pd.read_csv(detail_path, usecols=usecols)
这比直接 pd.read_csv() 更稳,因为如果某些字段缺失,程序不会立刻崩掉。
如果数据中没有 score_clean,但有原始成绩字段 mes_Score,程序会自动生成清洗成绩:
if "score_clean" not in detail.columns and "mes_Score" in detail.columns:detail["score_clean"] = pd.to_numeric(detail["mes_Score"], errors="coerce")detail.loc[detail["score_clean"] < 0, "score_clean"] = pd.NA
这里把负数成绩设为空值,是为了处理异常成绩。因为负数通常不应该参与均分计算,否则会影响薄弱学科判断。
6. 规则画像:把成绩、考勤、消费转成可解释标签
学生画像构建由 profiling.py 完成。主函数如下:
def build_rule_profiles(students: pd.DataFrame) -> pd.DataFrame:df = students.copy()df[COLS.academic_level] = _score_band(df.get("avg_score"))df[COLS.stability_level] = _stability_band(df.get("std_score"))df[COLS.attendance_level] = _attendance_band(df.get("attendance_events"))df[COLS.consumption_level] = _spending_band(df.get("avg_spending"))df["profile_summary"] = df.apply(_summary_sentence, axis=1)df[COLS.profile_json] = df.apply(_profile_json, axis=1)df[COLS.profile_text] = df.apply(_profile_text, axis=1)return df
这段代码做了三类事情:
第一,生成画像标签:
academic_levelstability_levelattendance_levelconsumption_level
第二,生成自然语言摘要:
profile_summary第三,生成适合程序使用的 JSON 和适合大模型输入的文本:
profile_jsonprofile_text
6.1 学业层级:不用固定分数线,而是用分位数
学业层级由 _score_band() 实现:
def _score_band(score: pd.Series | None) -> pd.Series:s = pd.to_numeric(score, errors="coerce")valid = s.dropna()q20, q40, q60, q80 = valid.quantile([0.2, 0.4, 0.6, 0.8]).tolist()
这段代码先计算平均分的 20%、40%、60%、80% 分位数,然后根据学生分数所在区间打标签:
def label(v: float) -> str:if pd.isna(v):return "暂无成绩"if v >= q80:return "优势突出"if v >= q60:return "稳中向上"if v >= q40:return "基础中等"if v >= q20:return "需要巩固"return "重点帮扶"
这里没有使用固定规则,比如“90 分以上优秀、60 分以下不及格”。原因是不同考试难度不同,不同班级整体水平也不同。使用分位数更适合做相对评价。
6.2 稳定性画像:用标准差判断成绩波动
成绩稳定性由 _stability_band() 处理:
q33, q66 = valid.quantile([0.33, 0.66]).tolist()然后根据标准差分成三类:
if v <= q33:return "表现稳定"if v <= q66:return "有一定波动"return "波动较大"
这里的逻辑是: 标准差越小,说明成绩越稳定;标准差越大,说明学生在不同考试或不同科目上的表现波动更明显。
这类学生不一定是成绩低,也可能是“会的很会,不会的很不会”,因此后续推荐时更适合推送“错题系统”“考试节奏”这类方法型资源。
6.3 考勤画像:用分箱规则判断关注程度
考勤画像使用 pd.cut() 完成:
return pd.cut(e,bins=[-0.1, 0, 2, 8, np.inf],labels=["记录良好", "偶有异常", "需要提醒", "重点关注"],).astype(str)
这里的区间含义大致是:
这种规则虽然简单,但比较适合实验场景。它可以把原始数字转化成老师更容易理解的判断。
6.4 消费画像:用四分位数判断消费状态
消费画像由 _spending_band() 实现:
q25, q75 = valid.quantile([0.25, 0.75]).tolist()然后分成三类:
if v < q25:return "低频低额"if v > q75:return "高频高额"return "常规水平"
消费状态本身不能直接说明学习问题,但可以作为生活状态参考。比如消费明显偏高的学生,后续可以推荐“消费管理”这类生活建议资源。
6.5 画像文本:给大模型和报告使用
画像摘要由 _summary_sentence() 生成:
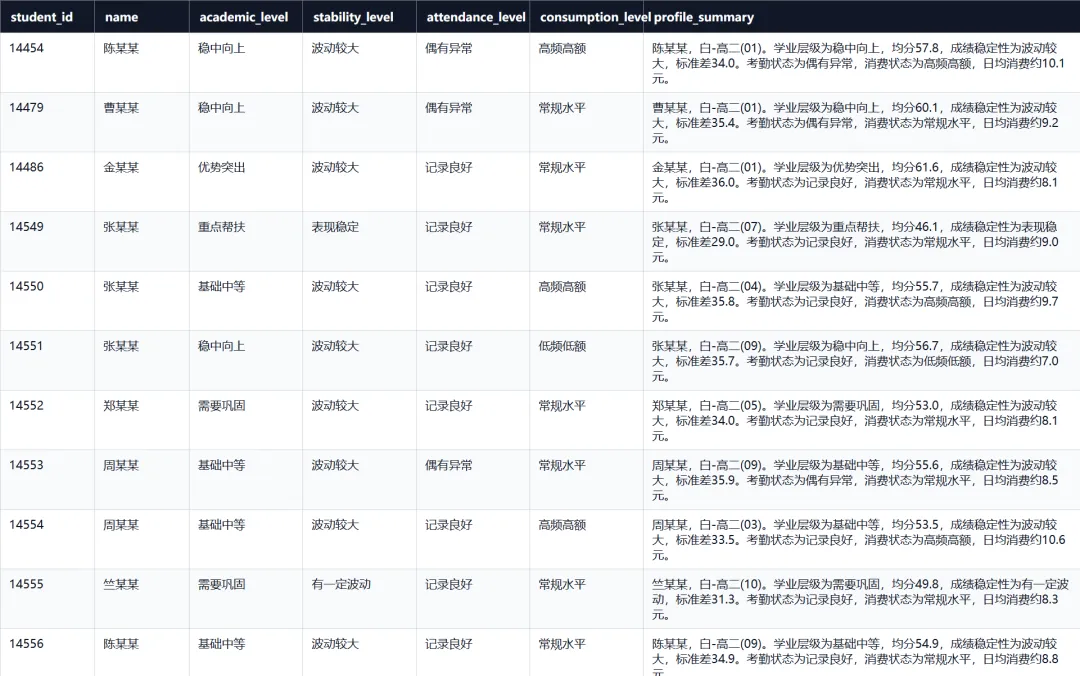
def _summary_sentence(row: pd.Series) -> str:avg_score = _fmt(row.get("avg_score"), "{:.1f}")std_score = _fmt(row.get("std_score"), "{:.1f}")spending = _fmt(row.get("avg_spending"), "{:.1f}")return (f"{row.get('name', '该学生')},{row.get('class_name', '未知班级')}。"f"学业层级为{row.get(COLS.academic_level)},均分{avg_score},"f"成绩稳定性为{row.get(COLS.stability_level)},标准差{std_score}。"f"考勤状态为{row.get(COLS.attendance_level)},消费状态为{row.get(COLS.consumption_level)},"f"日均消费约{spending}元。")
这一步的作用是把画像结果转换成可读文字。比如:
张三,高一2班。学业层级为需要巩固,均分72.4,成绩稳定性为波动较大,标准差11.6。考勤状态为偶有异常,消费状态为常规水平,日均消费约18.5元。
而 _profile_text() 会生成更结构化的文本,后面会传给大模型:
parts = [f"学生姓名: {row.get('name', '')}",f"班级: {row.get('class_name', '')}",f"性别: {row.get('gender', '')}",f"籍贯: {row.get('native_place', '')}",f"家庭类型: {row.get('residence_type', '')}",f"学业层级: {row.get(COLS.academic_level)}",f"成绩稳定性: {row.get(COLS.stability_level)}",f"考勤状态: {row.get(COLS.attendance_level)}",f"消费状态: {row.get(COLS.consumption_level)}",f"简要画像: {row.get('profile_summary')}",]
这个设计比直接把整行 DataFrame 丢给大模型更好,因为它只保留与画像相关的信息,减少无关字段干扰。
7. 大模型增强:让画像从“标签”变成“建议”
规则画像解决了“学生是什么状态”的问题,但还没有解决“应该怎么帮助他”的问题。
因此项目在 llm_client.py 中封装了大模型调用。
7.1 创建大模型客户端
def create_llm_client():api_key = os.environ.get("DASHSCOPE_API_KEY")if not api_key:raise RuntimeError("大模型未配置:请先设置环境变量 DASHSCOPE_API_KEY。""本项目已经取消非大模型路线,不能在无 API Key 的情况下运行。")
这里程序会先检查环境变量 DASHSCOPE_API_KEY。如果没有配置,就直接抛出错误。
这比静默失败更好。因为如果大模型没有配置,后面生成画像建议、embedding、推荐报告都会失败,提前报错能更快定位问题。
客户端创建代码如下:
return OpenAI(api_key=api_key,base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
这里使用的是 DashScope 兼容 OpenAI SDK 的调用方式。
7.2 生成学生画像增强信息
核心函数是:
def enhance_profile_with_llm(client: Any,profile_text: str,model: str = "qwen-plus") -> dict[str, Any]:
提示词如下:
prompt = ("你是一名教育数据分析师。请基于学生结构化画像生成严格 JSON,字段包括 ""strengths, risks, action_plan, parent_note。不要编造画像中不存在的事实。\n\n"f"{profile_text}")
这段提示词有几个关键要求:
严格 JSON字段包括 strengths, risks, action_plan, parent_note不要编造画像中不存在的事实
这很重要。因为学生画像属于教育分析场景,不能让模型随意推断学生家庭、性格或心理状态。
调用模型时,代码设置了较低的温度:
temperature=0.2较低温度可以让输出更稳定,减少格式漂移。
同时,代码要求返回 JSON 对象:
response_format={"type": "json_object"}最终返回结果会被解析成 Python 字典:
return json.loads(response.choices[0].message.content)

8. Embedding 封装:为向量检索做准备
推荐系统需要比较“学生画像”和“教育资源”之间的语义相似度,因此项目封装了 embedding 调用:
def embed_texts(client: Any,texts: list[str],model: str = "text-embedding-v4",batch_size: int = 10) -> list[list[float]]:
这段代码支持批量处理:
embeddings: list[list[float]] = []for start in range(0, len(texts), batch_size):batch = texts[start : start + batch_size]response = client.embeddings.create(model=model, input=batch)embeddings.extend(item.embedding for item in response.data)return embeddings
这里用 batch_size=10 控制每次请求的文本数量。这样做有两个好处:
避免一次性提交太多文本导致接口失败; 比逐条请求更高效。
这一步会被后面的 Chroma 建库和学生画像检索共同使用。
9. Pydantic 校验:不要完全相信大模型输出
虽然提示词要求大模型输出 JSON,但实际开发中仍然不能完全相信模型输出。 因此项目使用 schemas.py 定义了 Pydantic 模型。
学生画像增强结果的结构如下:
class ProfileLLMOutput(BaseModel):strengths: list[str] = Field(default_factory=list)risks: list[str] = Field(default_factory=list)action_plan: list[str] = Field(default_factory=list)parent_note: str = ""
这里规定了四个字段:
strengths 学生优势risks 风险点action_plan 行动建议parent_note 家校沟通建议
代码还写了一个字段转换器:
@field_validator("strengths", "risks", "action_plan", mode="before")@classmethoddef _listify(cls, value: Any) -> list[str]:if value is None:return []if isinstance(value, list):return [str(item).strip() for item in value if str(item).strip()]return [str(value).strip()] if str(value).strip() else []
这个函数解决了一个常见问题:大模型有时候会把列表写成字符串。
比如模型可能返回:
{"strengths": "学习态度较稳定"}
但程序希望得到:
{"strengths": ["学习态度较稳定"]}
通过 _listify(),字符串会被转换成列表,避免后续处理报错。
推荐结果也定义了结构:
class RecommendedResource(BaseModel):resource_id: strreason: strpriority: str = "中"
完整推荐报告结构如下:
class RecommendationLLMOutput(BaseModel):recommended_resources: list[RecommendedResource] = Field(default_factory=list)learning_plan: str = ""peer_suggestion: str = ""overall_recommendation: str = ""
这里最关键的是资源 ID 校验:
filtered = [itemfor item in parsed.recommended_resourcesif item.resource_id in allowed_resource_ids]
这可以防止大模型生成候选资源库之外的资源 ID。 换句话说,大模型可以生成推荐理由,但不能随便“发明资源”。
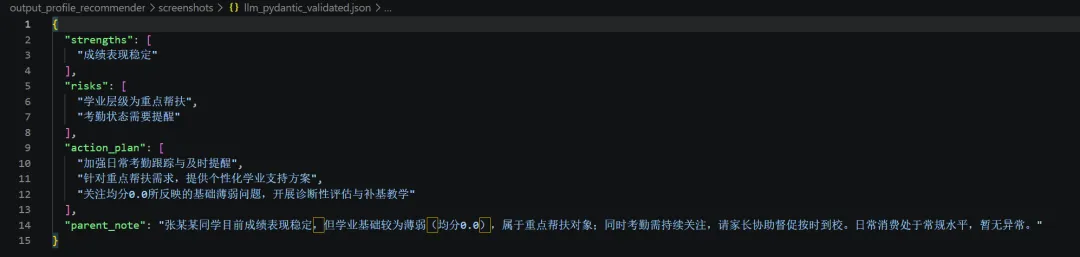
10. 教育资源库:推荐系统不能凭空推荐
项目在 resources.py 中内置了一组教育资源:
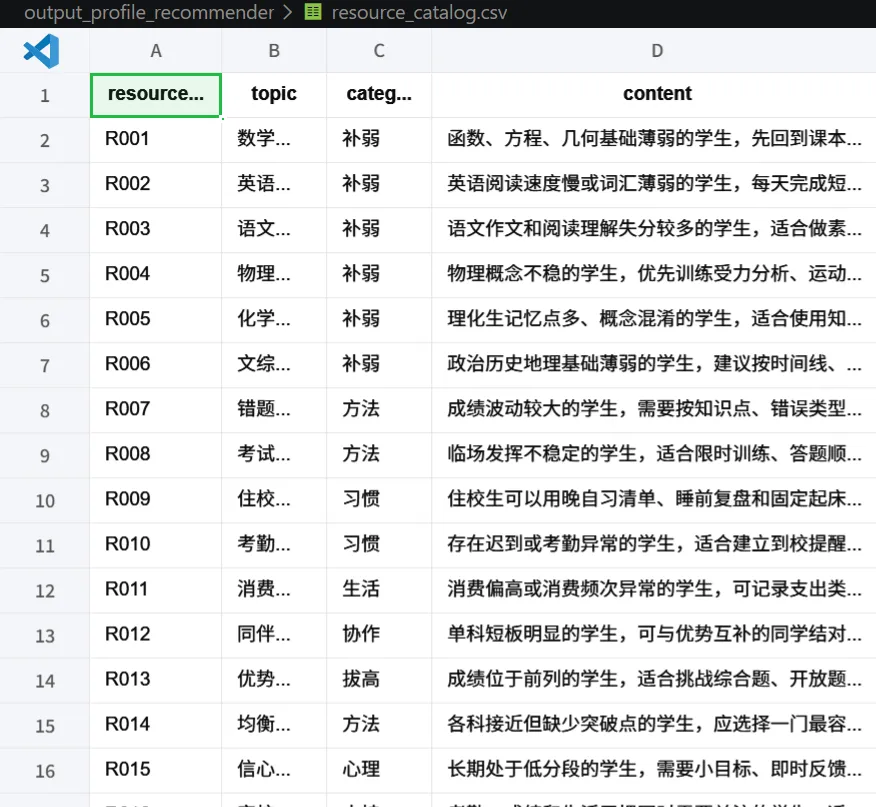
def default_resource_catalog() -> pd.DataFrame:resources = [("R001", "数学基础", "补弱", "函数、方程、几何基础薄弱的学生,先回到课本例题和错题复盘,建立一题多解笔记。"),("R002", "英语阅读", "补弱", "英语阅读速度慢或词汇薄弱的学生,每天完成短文精读和高频词复现训练。"),("R007", "错题系统", "方法", "成绩波动较大的学生,需要按知识点、错误类型和复盘日期管理错题。"),("R010", "考勤改善", "习惯", "存在迟到或考勤异常的学生,适合建立到校提醒、同伴监督和一周行为记录。"),("R011", "消费管理", "生活", "消费偏高或消费频次异常的学生,可记录支出类型,区分必要消费与冲动消费。"),("R016", "家校沟通", "支持", "考勤、成绩和生活习惯同时需要关注的学生,适合建立教师、家长、学生三方周反馈。"),]
最后返回 DataFrame:
return pd.DataFrame(resources, columns=["resource_id", "topic", "category", "content"])每条资源包含四个字段:
这里的资源类别很重要,比如:
补弱、方法、习惯、生活、协作、拔高、心理、支持后续推荐时,系统会根据学生画像优先选择对应类别。
例如:
学业层级为“重点帮扶”:优先推荐补弱、心理、支持; 成绩稳定性为“波动较大”:优先推荐错题系统、考试节奏; 考勤状态为“重点关注”:优先推荐考勤改善、家校沟通; 消费状态为“高频高额”:可以推荐消费管理。
11. 推荐主流程:Chroma 召回 + 画像重排
推荐核心在 recommenders.py 中,主函数是:
def recommend_resources(profiles: pd.DataFrame,resources: pd.DataFrame,client: Any,persist_dir: Path,embedding_model: str,top_k: int = 3,candidate_pool: int = 10,mmr_lambda: float = 0.72,) -> pd.DataFrame:
这个函数输入学生画像、资源库、大模型客户端、向量库目录和 embedding 模型,输出推荐结果表。
11.1 创建 Chroma 持久化向量库
persist_dir.mkdir(parents=True, exist_ok=True)chroma_client = chromadb.PersistentClient(path=str(persist_dir))
这里使用的是 Chroma 的持久化客户端。 也就是说,资源向量库不是每次运行都临时存在,而是可以保存到本地目录中。
接着调用:
collection = _prepare_resource_collection(chroma_client=chroma_client,resources=resources,client=client,embedding_model=embedding_model,)
这个函数负责准备资源向量集合。
11.2 构造资源文档
资源不是直接拿 topic 或 content 去做 embedding,而是先拼成完整文本:
def _resource_document(row: pd.Series) -> str:return f"资源ID:{row['resource_id']}\n主题:{row['topic']}\n类别:{row['category']}\n内容:{row['content']}"
这样 embedding 模型看到的不只是资源内容,还能看到资源 ID、主题和类别。
比如一条资源会被转换成:
资源ID:R007主题:错题系统类别:方法内容:成绩波动较大的学生,需要按知识点、错误类型和复盘日期管理错题。
这种文本比单独的“错题系统”更完整,召回效果也会更稳定。
11.3 资源库签名:判断是否需要重建索引
代码中有一个细节:
signature = _resource_signature(resources, embedding_model)资源签名由资源内容和 embedding 模型共同生成:
payload = embedding_model + "\n" + "\n".join(_resource_document(row)for _, row in resources.sort_values("resource_id").iterrows())return hashlib.sha1(payload.encode("utf-8")).hexdigest()
如果资源库内容没变,embedding 模型也没变,就可以复用已有索引。 如果资源或模型变了,就删除旧索引重新构建。
这个设计避免了两个问题:
每次运行都重复生成资源向量,浪费时间; 资源内容更新后仍然误用旧索引。
11.4 写入 Chroma
collection.add(ids=resources["resource_id"].astype(str).tolist(),documents=documents,embeddings=embeddings,metadatas=[{"resource_id": str(row["resource_id"]),"topic": str(row["topic"]),"category": str(row["category"]),}for _, row in resources.iterrows()],)
这里同时写入了:
ids 资源 IDdocuments 资源文本embeddings 资源向量metadatas 资源元数据
元数据中的 category 后面会用于过滤候选资源。

12. 学生画像如何变成检索 query
给学生推荐资源时,代码会遍历每个学生画像:
for _, profile in profiles.reset_index(drop=True).iterrows():query_text = _recommendation_query(profile)query_embedding = embed_texts(client, [query_text], model=embedding_model)[0]
_recommendation_query() 会把规则画像和大模型画像拼接起来:
def _recommendation_query(profile: pd.Series) -> str:llm_parts = [profile.get("llm_strengths", ""),profile.get("llm_risks", ""),profile.get("llm_action_plan", ""),profile.get("llm_parent_note", ""),]llm_text = " ".join(str(part)for part in llm_partsif pd.notna(part) and str(part).strip())base_text = str(profile.get("profile_text", ""))if llm_text:return f"{base_text}\n【大模型画像补充】{llm_text}"return base_text
也就是说,学生 query 不是只有规则标签,而是包含:
结构化画像文本+大模型补充分析
例如:
学生姓名: 张三班级: 高一2班学业层级: 需要巩固成绩稳定性: 波动较大考勤状态: 偶有异常消费状态: 常规水平简要画像: 张三,高一2班。学业层级为需要巩固...【大模型画像补充】需要通过错题复盘降低成绩波动,建议每周固定一次学习反馈。
这样生成的向量更能表达学生的真实推荐需求。
13. 先过滤类别:不是所有资源都应该进入候选池
在向量检索之前,代码会根据画像判断优先资源类别:
categories = _preferred_categories(profile)核心规则如下:
if academic in {"重点帮扶", "需要巩固", "基础中等"}:categories.update(["补弱", "心理", "支持", "协作"])if academic in {"稳中向上", "优势突出"}:categories.update(["方法", "拔高", "协作"])if stability == "波动较大":categories.update(["方法", "支持"])if attendance in {"需要提醒", "重点关注"}:categories.update(["习惯", "支持"])if consumption == "高频高额":categories.add("生活")
这一步体现了推荐系统里的业务约束。
比如,一个学生考勤异常明显,那么系统应该优先考虑“习惯”“支持”类资源,而不是只根据语义相似度推荐学科训练。
然后,查询 Chroma 时会带上类别过滤:
where = {"category": {"$in": categories}} if categories else None完整查询代码如下:
return collection.query(query_embeddings=[query_embedding],n_results=n_results,where=where,include=["documents", "metadatas", "distances", "embeddings"],)
如果元数据过滤失败,代码还提供了兜底查询:
except Exception:return collection.query(query_embeddings=[query_embedding],n_results=n_results,include=["documents", "metadatas", "distances", "embeddings"],)
这个设计可以提高系统鲁棒性。即使某些 Chroma 版本或元数据条件不兼容,系统仍然能返回推荐结果。

14. 向量分数如何计算
Chroma 返回的是距离,代码把距离转换成语义分:
semantic_score = max(0.0, 1.0 - float(distance))然后构造候选资源:
candidates.append({"resource": resource,"embedding": np.asarray(embedding, dtype=float),"semantic_score": semantic_score,})
这里每个候选资源包含:
resource 资源信息embedding 资源向量semantic_score 语义相似分
这个分数只说明资源和学生画像在语义上是否接近,还没有考虑学生画像规则的额外加权。
15. 画像加权:让推荐更贴近教育场景
接下来代码会给候选资源加上画像加权分:
bonus = _profile_bonus(profile, item["resource"])item["profile_bonus"] = bonusitem["base_score"] = item["semantic_score"] + bonus
画像加权规则如下:
if academic in {"重点帮扶", "需要巩固", "基础中等"} and category == "补弱":bonus += 0.25if academic == "优势突出" and category == "拔高":bonus += 0.22if stability == "波动较大" and topic in {"错题系统", "考试节奏"}:bonus += 0.24if attendance in {"需要提醒", "重点关注"} and topic in {"考勤改善", "家校沟通"}:bonus += 0.28if consumption == "高频高额" and topic == "消费管理":bonus += 0.18
这一步很关键。
如果只看向量相似度,推荐结果可能“语义相关但不够针对”。 加入画像加权后,系统会更倾向于推荐和学生问题匹配的资源。
比如:
学业层级低 + 补弱资源:加分; 成绩优秀 + 拔高资源:加分; 成绩波动大 + 错题系统:加分; 考勤异常 + 家校沟通:加分; 消费偏高 + 消费管理:加分。
这样推荐结果更容易解释,也更适合写进实验报告。
16. MMR 重排:避免推荐结果太重复
如果只按照 base_score 排序,Top3 结果可能都集中在同一种类型,比如全是补弱资源。 为了避免推荐结果过于单一,代码使用了 MMR 思想进行重排:
score = (mmr_lambda * item["base_score"]+ 0.15 * query_alignment- (1 - mmr_lambda) * diversity_penalty)
这个公式可以拆开理解:
最终分数 =相关性权重 × 基础分+ query 对齐分- 多样性惩罚
其中:
diversity_penalty = max(_cosine(item["embedding"], chosen["embedding"])for chosen in selected)
表示当前候选资源和已选资源之间的相似度。 如果它和已经选中的资源太像,就会被扣分。
query_alignment = _cosine(item["embedding"], query_vec)表示候选资源和学生画像 query 的向量相似度。
mmr_lambda 默认值是:
mmr_lambda: float = 0.72它控制相关性和多样性的平衡。数值越高,越重视相关性;数值越低,越重视多样性。
最后,代码每次选出当前分数最高的资源:
chosen = remaining.pop(best_idx)chosen["final_score"] = best_scoreselected.append(chosen)
直到选够 TopK。
这一步让推荐结果既相关,又不会全是同质化资源。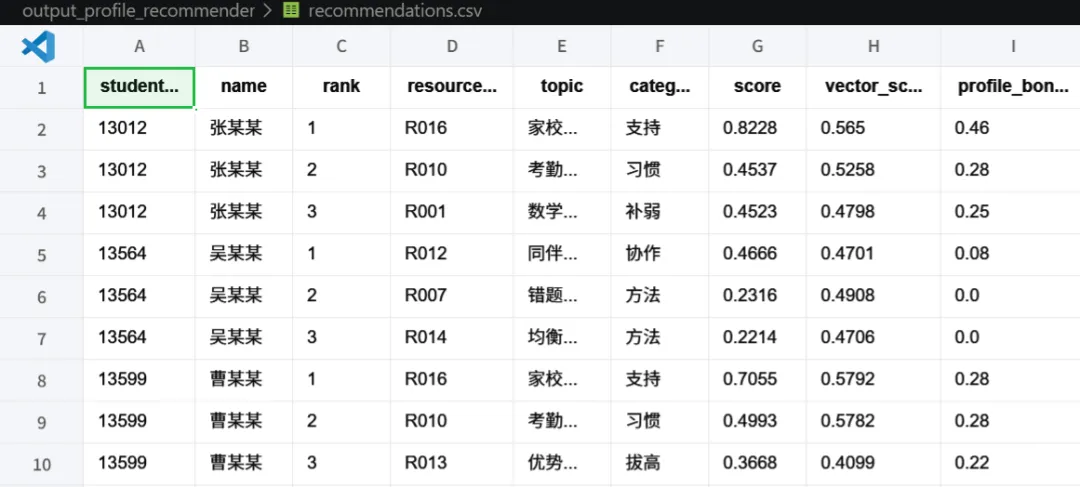
17. 推荐结果表:不只输出资源,还输出解释字段
推荐完成后,代码会把每条推荐结果整理成 DataFrame 行:
rows.append({"student_id": profile["student_id"],"name": profile.get("name", ""),"rank": rank,"resource_id": resource["resource_id"],"topic": resource["topic"],"category": resource["category"],"score": round(float(item["final_score"]), 4),"vector_score": round(float(item["semantic_score"]), 4),"profile_bonus": round(float(item["profile_bonus"]), 4),"retrieval_method": "chroma_dashscope_embedding_mmr","retrieval_filter": "、".join(categories) if categories else "none","reason": _reason(profile, resource),"content": resource["content"],})
这里我认为设计得比较完整,因为它不只给出推荐资源,还保留了推荐过程中的解释信息:
其中 reason 由 _reason() 生成:
def _reason(profile: pd.Series, resource: dict[str, object]) -> str:signals = [f"学业层级: {profile.get('academic_level')}",f"稳定性: {profile.get('stability_level')}",f"考勤: {profile.get('attendance_level')}",f"消费: {profile.get('consumption_level')}",]return (f"该资源属于「{resource['category']}」方向,""向量检索命中后结合画像信号重排:"+ ",".join(signals)+ "。")
这段代码让推荐结果更可解释。 老师看到推荐结果时,不只是知道“推荐了什么”,还能知道“为什么推荐”。
18. 薄弱学科分析:让推荐更具体
如果成绩明细数据存在,代码还会分析学生的薄弱学科:
def weak_subject_suggestions(detail: pd.DataFrame | None,students: pd.DataFrame,max_subjects: int = 2) -> pd.DataFrame:
如果成绩明细为空,直接返回空结果:
if detail is None or detail.empty or "mes_sub_name" not in detail.columns:return pd.DataFrame(columns=["student_id", "weak_subjects", "subject_reason"])
如果有明细数据,代码先整理出每个学生每个学科的均分:
subject_scores = usable.pivot_table(index="student_id",columns="mes_sub_name",values="score_clean",aggfunc="mean",)
然后取主要学科中分数最低的若干个:
available = row[[s for s in MAIN_SUBJECTS if s in row.index]].dropna()weakest = available.sort_values().head(max_subjects)
最后生成字段:
subjects = "、".join(weakest.index.tolist())reason = ";".join(f"{subj}均分{score:.1f}" for subj, score in weakest.items())
输出效果类似:
weak_subjects: 数学、英语subject_reason: 数学均分65.2;英语均分68.5
如果学生没有明细成绩,则返回:
"暂无明细成绩,先按综合画像推荐。"这一步让推荐结果更细。 比如同样是“需要巩固”的学生,如果薄弱学科是数学,就可以在推荐说明里补充数学基础训练;如果薄弱学科是英语,就可以补充英语阅读训练。
19. 缓存设计:减少重复调用大模型
项目中还写了一个轻量级 JSON 文件缓存:
class JsonCache:def __init__(self, root: Path):self.root = rootself.root.mkdir(parents=True, exist_ok=True)
读取缓存:
def get(self, namespace: str, payload: dict[str, Any]) -> dict[str, Any] | None:path = self._path(namespace, payload)if not path.exists():return Nonereturn json.loads(path.read_text(encoding="utf-8"))
写入缓存:
def set(self, namespace: str, payload: dict[str, Any], value: dict[str, Any]) -> None:path = self._path(namespace, payload)path.parent.mkdir(parents=True, exist_ok=True)path.write_text(json.dumps(value, ensure_ascii=False, indent=2),encoding="utf-8")
最核心的是 _path():
def _path(self, namespace: str, payload: dict[str, Any]) -> Path:raw = json.dumps(payload, ensure_ascii=False, sort_keys=True)digest = hashlib.sha256(raw.encode("utf-8")).hexdigest()return self.root / namespace / f"{digest}.json"
这里把请求参数 payload 转成 JSON,再计算 SHA256 哈希值,作为缓存文件名。
这样做的好处是: 只要输入内容相同,就能命中同一个缓存文件。实验调试时不用反复调用大模型,可以节省时间和调用成本。
20. 报告输出:让实验结果可以直接查看
最后,项目使用 reporting.py 输出运行结果。
20.1 输出 run_summary.json
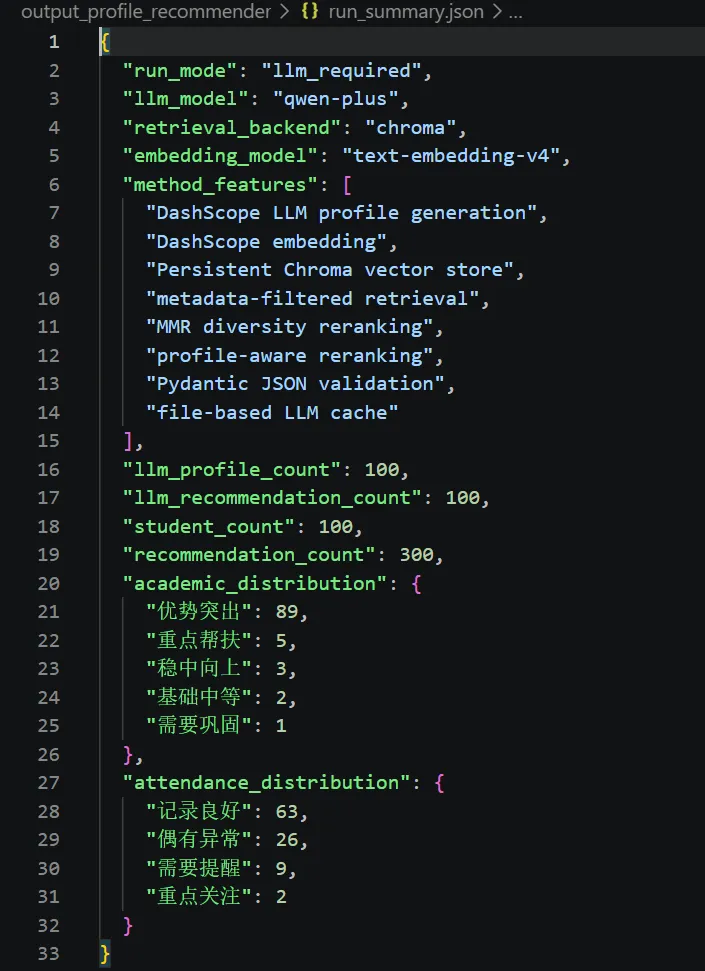
summary = {"run_mode": "llm_required","llm_model": model,"retrieval_backend": "chroma","embedding_model": embedding_model,"method_features": ["DashScope LLM profile generation","DashScope embedding","Persistent Chroma vector store","metadata-filtered retrieval","MMR diversity reranking","profile-aware reranking","Pydantic JSON validation","file-based LLM cache",],"student_count": int(len(profiles)),"recommendation_count": int(len(recommendations)),"academic_distribution": profiles["academic_level"].value_counts().to_dict(),"attendance_distribution": profiles["attendance_level"].value_counts().to_dict(),}
这份 JSON 主要用于记录本次实验运行情况,包括:
使用的大模型使用的 embedding 模型检索后端学生数量推荐数量学业画像分布考勤画像分布
写入文件:
(output_dir / "run_summary.json").write_text(json.dumps(summary, ensure_ascii=False, indent=2),encoding="utf-8")
20.2 输出 Markdown 推荐报告
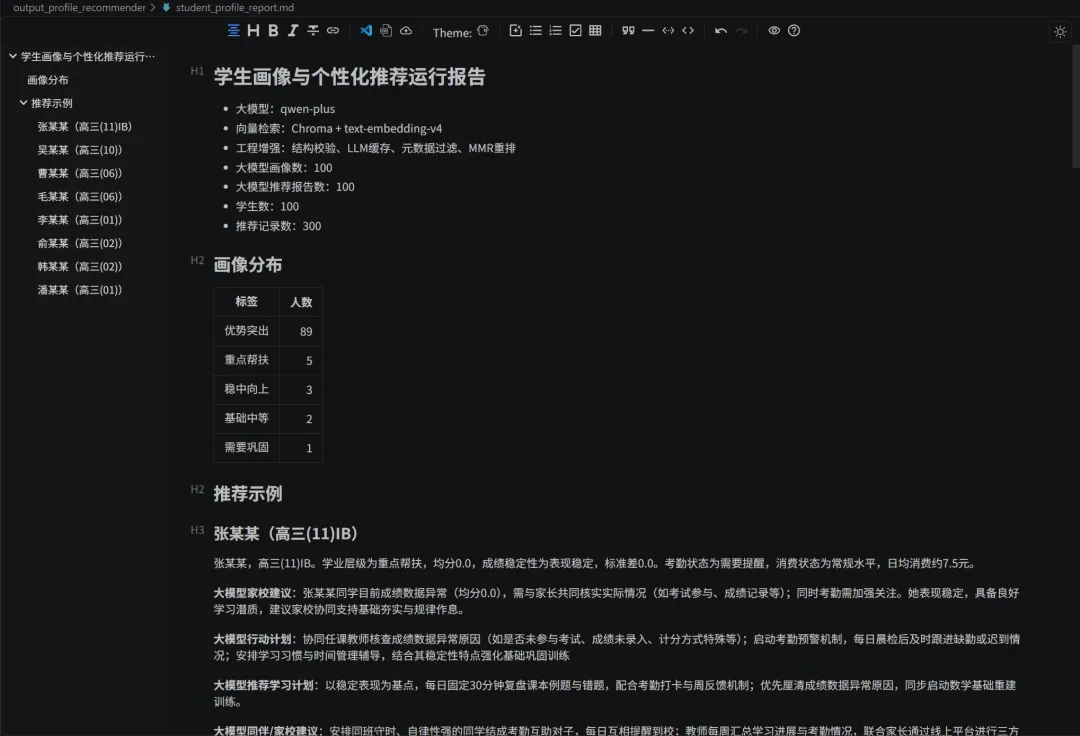
代码还会生成 student_profile_report.md:
lines = ["# 学生画像与个性化推荐运行报告","",f"- 大模型:{model}",f"- 向量检索:Chroma + {embedding_model}",f"- 工程增强:结构校验、LLM缓存、元数据过滤、MMR重排",f"- 学生数:{len(profiles)}",f"- 推荐记录数:{len(recommendations)}",]
然后针对每个学生输出画像和推荐资源:
for _, row in profiles.head(n).iterrows():recs = recommendations[recommendations["student_id"] == row["student_id"]].head(3)
学生画像部分:
lines.append(f"### {row.get('name', '')}({row.get('class_name', '')})")lines.append(row["profile_summary"])
大模型建议部分:
if row.get("llm_parent_note", ""):lines.append(f"**大模型家校建议**:{row.get('llm_parent_note')}")
推荐资源部分:
lines.append(f"- Top{rec['rank']}:{rec['topic']} / {rec['category']},"f"综合分 {rec['score']},向量分 {rec.get('vector_score', '')}")
20.3 输出画像分布图
图表输出代码如下:
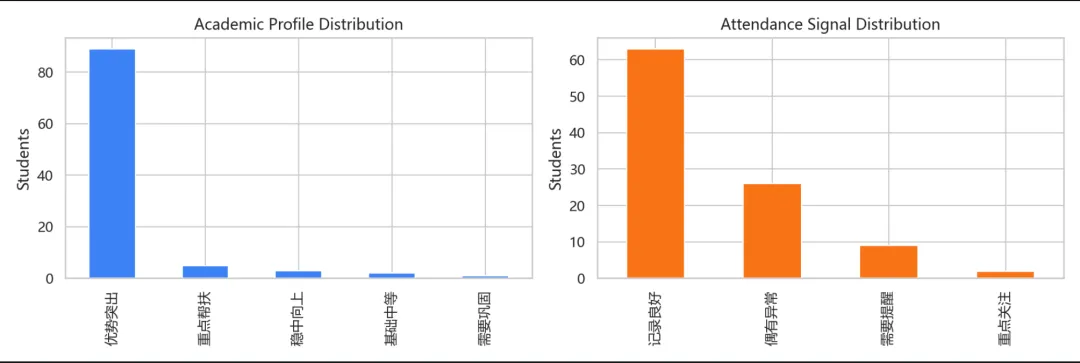
profiles["academic_level"].value_counts().plot.bar(ax=axes[0], color="#3b82f6")axes[0].set_title("Academic Profile Distribution")
考勤分布图:
profiles["attendance_level"].value_counts().plot.bar(ax=axes[1], color="#f97316")axes[1].set_title("Attendance Signal Distribution")
最后保存图片:
fig.savefig(output_dir / "profile_distributions.png", dpi=160)生成的图片可以用来观察整体学生群体的画像分布,比如“需要巩固”的学生比例是否较高,或“考勤重点关注”的学生数量是否异常。
21. 实验结果分析
本次实验最终输出了三类结果。
第一类是运行摘要文件:
run_summary.json它用于记录本次实验的运行模式、模型名称、推荐方法、学生数量和画像分布。
第二类是学生画像推荐报告:
student_profile_report.md它会展示学生画像摘要、大模型建议、Top3 推荐资源和推荐分数。 这份报告更适合给老师或项目评审查看。
第三类是画像分布图:
profile_distributions.png它可以直观看出学生整体分布情况,例如不同学业层级的人数、不同考勤状态的人数。
推荐结果中的核心字段包括:
从结果设计来看,这个系统不是只给出“推荐了什么”,而是同时保留“为什么推荐”和“怎么计算出来的”。这对教育场景比较重要,因为老师通常需要解释依据,而不是只看黑盒结果。
22. 实验中遇到的问题与解决方法
问题一:大模型 API Key 没有配置
问题现象:
运行时报错:
大模型未配置:请先设置环境变量 DASHSCOPE_API_KEY。问题原因:
create_llm_client() 中强制要求读取环境变量:
api_key = os.environ.get("DASHSCOPE_API_KEY")if not api_key:raise RuntimeError(...)
如果没有配置 API Key,就无法调用大模型和 embedding 接口。
解决方法:
在系统环境变量中配置:
DASHSCOPE_API_KEY=自己的 API KeyWindows 命令行中可以临时设置:
set DASHSCOPE_API_KEY=自己的APIKey问题二:成绩字段类型不对
问题现象:
画像划分时,部分学生显示为“暂无成绩”,或者分位数计算异常。
问题原因:
CSV 中的成绩字段可能被读取成字符串,或者包含异常值。
解决方法:
代码中使用:
pd.to_numeric(value, errors="coerce")把无法转换的值变成空值。 成绩明细中如果出现负数,也会被处理为空值:
detail.loc[detail["score_clean"] < 0, "score_clean"] = pd.NA问题三:大模型输出格式不稳定
问题现象:
模型有时会把 strengths、risks、action_plan 输出成字符串,而不是列表。
问题原因:
大模型虽然被要求输出 JSON,但字段类型仍可能不完全稳定。
解决方法:
使用 Pydantic 的字段校验器:
@field_validator("strengths", "risks", "action_plan", mode="before")def _listify(cls, value):...
将字符串自动转换成列表。
问题四:大模型可能生成不存在的资源 ID
问题现象:
推荐报告中可能出现候选资源库中没有的 resource_id。
问题原因:
大模型存在生成性,可能会根据上下文生成看似合理但实际不存在的资源编号。
解决方法:
在 normalize_recommendation_output() 中过滤资源 ID:
filtered = [itemfor item in parsed.recommended_resourcesif item.resource_id in allowed_resource_ids]
这样可以保证最终推荐结果只来自已有资源库。
问题五:推荐结果可能过于相似
问题现象:
如果只按向量相似度排序,Top3 推荐可能全部集中在同一类资源上。
问题原因:
向量检索重视语义相似,但不一定保证结果多样性。
解决方法:
使用 MMR 重排:
score = (mmr_lambda * item["base_score"]+ 0.15 * query_alignment- (1 - mmr_lambda) * diversity_penalty)
通过加入 diversity_penalty,降低与已选资源过于相似的候选项得分。
23. 总结:这个系统真正做了什么
这次实验不是简单地“调用大模型生成学生建议”,而是实现了一条比较完整的教育推荐 pipeline:
我认为这个项目中比较值得保留的设计有四点。
第一,规则画像先行。 平均分、标准差、考勤次数、消费金额先经过规则转换成画像标签,保证系统有稳定的判断基础。
第二,大模型只做增强,不做全部决策。 大模型负责生成自然语言建议,但画像判断、资源过滤和结果校验仍然由代码控制。
第三,推荐过程保留解释字段。 推荐结果中包含 vector_score、profile_bonus、retrieval_filter 和 reason,方便分析推荐依据。
第四,工程细节比较完整。 代码中考虑了配置管理、数据缺失、异常值处理、缓存、Pydantic 校验、索引复用和报告输出,这些都是从实验代码走向项目原型时需要考虑的问题。
如果后续继续扩展,我会考虑加入:
班级画像:统计一个班整体的学业层级、考勤状态和薄弱学科; 教师端筛选:按班级、学科、风险类型筛选学生; 学生反馈数据:根据资源点击和反馈优化推荐; 推荐效果评估:统计推荐资源是否真正改善成绩或行为表现; 前端展示页面:把 Markdown 报告改成可交互的可视化面板。
整体来看,这个实验已经具备一个教育智能推荐系统的基本雏形。它的核心价值不是“用了大模型”,而是把大模型放进了一个可解释、可校验、可复用的数据推荐流程中。
#Python #教育数据分析 #学生画像 #推荐系统 #大模型应用 #向量检索 #Chroma #Pandas #Pydantic #技术实践
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 二级Python刷题顺序+高频易错点总结
- 看到 Python 代码就头大?7 个符号让你读懂 80%
- 自学编程第46课:python 调用AI大模型接口(API)——让电脑回答你的问题
- linux内存管理详解
- 让手机上运行 Linux 系统,这个开源神器有点猛...
- Python网络安全实战(3/10):HTTP请求分析与伪造
- 数据科学不是只学 Python,而是在学如何把问题变成模型
- 四千行 Python 的 Nanobot,凭什么在个人 AI Agent 里有一席之地
- Python科研绘图:半对数刻度折线图,绘制幅频响应曲线(0.1、1、10三个刻度等间距)
- Python大语言模型发人生第一篇ABS3!
