上下文切换:CPU 的"换脑"时刻
Linux 调度子系统技术文档系列 · 第 7 篇
今天我们要看context switch的内容了,那么先想象下:
生产环境中,你监控到一台机器的 vmstat 数据里 cs(context switch)数值异常偏高,达到了每秒 50 万次以上。与此同时,CPU 的 user% 并不高,但系统整体响应却明显变慢。
这是一个真实的性能陷阱。当 cat /proc/vmstat | grep cs 输出的数值过大时,意味着 CPU 正在把大量时间消耗在"context switch"上,而不是执行真正的业务逻辑。上下文切换的成本不是零,而且在高频率下,它的间接成本(TLB 刷新、缓存失效、分支预测器重置)远超直接成本(寄存器保存和恢复)。
理解上下文切换的机制,是排查这类性能问题的第一步,也是深入理解调度器的必经之路。
上下文的核心组成是什么?
进程上下文不是单一的数据结构,而是分散在多个内核结构中的状态集合。当进程被调度器选中或让出 CPU 时,内核需要精确地保存和恢复这些状态,否则进程就无法从暂停的位置继续执行。
进程上下文由以下核心组件构成:
| | |
|---|
| task_struct->thread / 内核栈 | |
| | |
| | |
| | |
| | |
| | |
在内核源码中,这些状态被组织在几个关键数据结构里。task_struct 是进程描述符,其中的 mm 指向用户空间地址空间,active_mm 用于内核线程借用地址空间。架构相关的寄存器状态保存在 thread_struct 中。
地址空间切换是上下文切换中最昂贵的操作。当切换发生在两个用户进程之间时,内核必须更新 CR3 寄存器指向新进程的页表基址,这会导致 TLB 失效。TLB 失效意味着接下来的内存访问都需要重新进行页表查找,每次 miss 会增加几十纳秒的延迟。而寄存器保存和恢复只需要几百纳秒,相比之下微不足道。
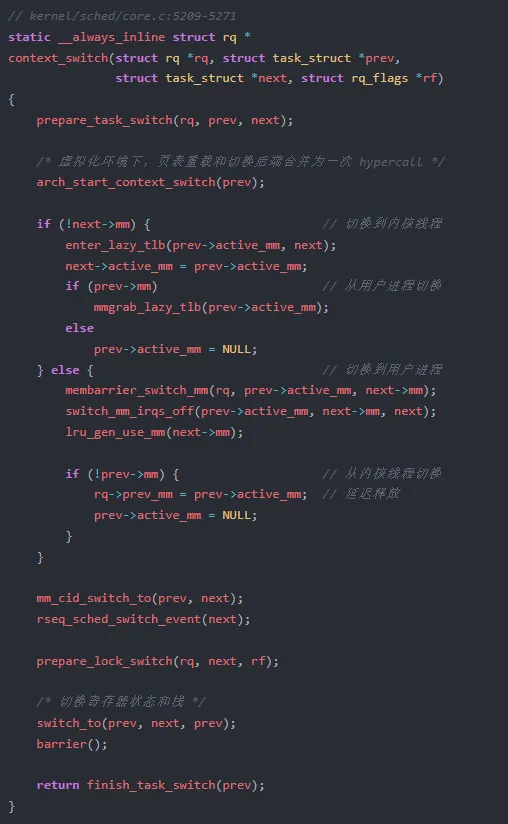
上下文切换的核心数据结构和入口函数
context_switch() 是上下文切换的核心入口,位于 kernel/sched/core.c。它的职责很明确:切换地址空间,然后切换寄存器和栈。但仔细看源码会发现,内核在这里做了大量精巧的设计决策。
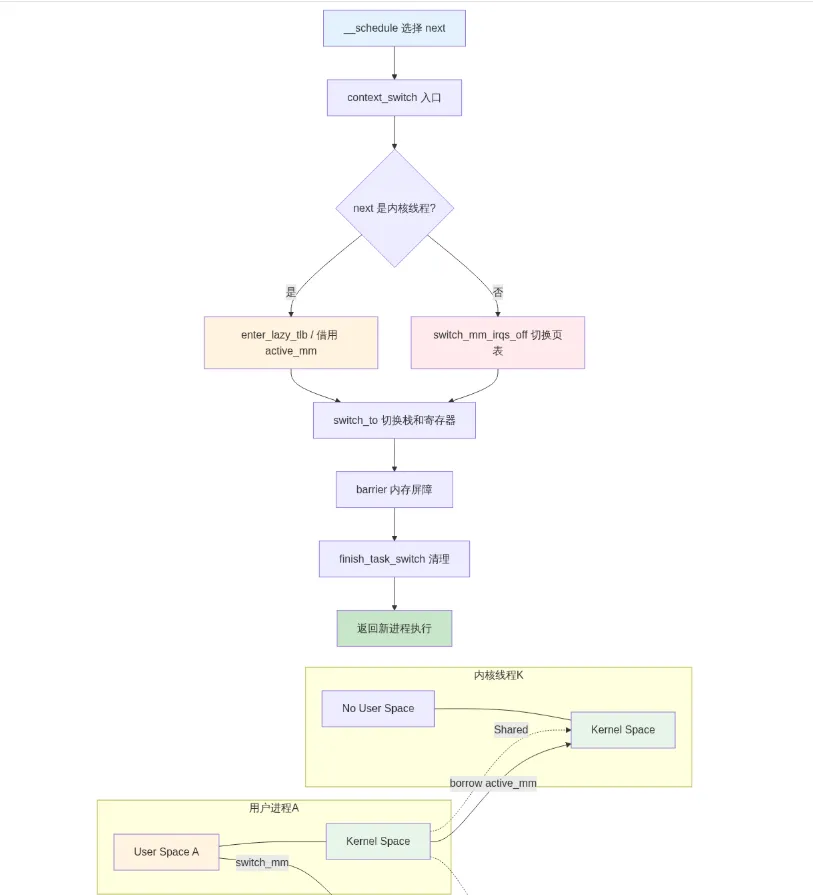
这段代码揭示了一个重要的设计哲学:内核线程和用户进程的切换路径是不同的。
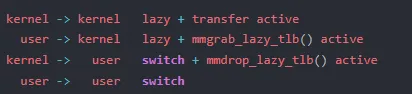
为什么内核线程不需要切换地址空间?因为所有进程的内核空间是共享的,内核线程只运行在内核态,不访问用户空间内存。它只需要一个合法的页表来访问内核空间的数据结构。内核通过 active_mm 借用前一个进程的地址空间,避免了切换页表和刷新 TLB 的开销。
源码注释里用四行字概括了四种切换场景的内存管理策略:
这个设计直接回答了生产中的一个关键问题:为什么高并发线程池的性能通常优于多进程模型?因为线程共享同一个 mm_struct,线程切换时不需要调用 switch_mm_irqs_off(),CR3 寄存器保持不变,TLB 缓存完全有效。而进程切换需要刷新 TLB,后续的内存访问会经历大量 page walk。
寄存器切换的底层实现:switch_to 汇编代码
switch_to 宏是架构相关的,负责完成最底层的栈和寄存器切换。在 x86_64 上,它最终调用 __switch_to_asm 这个汇编函数。
这段汇编代码是理解上下文切换的关键。switch_to 只保存 callee-saved 寄存器(rbx、rbp、r12-r15),而不是所有寄存器。这是因为根据 x86_64 的 System V ABI 调用约定,被调用函数负责保存这些寄存器,而 caller-saved 寄存器(rax、rcx、rdx 等)由调用者自己保存。内核态的上下文切换发生在 schedule() 函数内部,此时 caller-saved 寄存器已经保存在内核栈上了。
切换栈指针是整个操作的核心。TASK_threadsp(%rdi) 是 prev->thread.sp 的偏移量,TASK_threadsp(%rsi) 是 next->thread.sp 的偏移量。两条 movq 指令完成了栈的切换:先将当前栈顶保存到 prev 的 thread.sp,再将 next 的 thread.sp 加载到 rsp。从这一刻起,CPU 使用的就是新进程的内核栈了。
注意代码中的 jmp __switch_to 而不是 call。这是一个关键优化:switch_to 宏的调用者不希望看到返回值在调用者栈上,因为栈已经切换了。jmp 直接跳转到 __switch_to C 函数,后者负责设置新进程的返回地址,确保新进程从上次暂停的位置继续执行。
完整的上下文切换执行路径
上下文切换不是孤立发生的,它嵌套在 __schedule() 函数的深处。追踪完整的切换路径,才能理解每一步的前置条件和后续清理工作。
整个切换路径可以分解为三个阶段:
第一阶段是 prepare,由 prepare_task_switch() 完成。它会触发 perf 事件、通知 KVM 等外部子系统、处理 kmap_local 的映射。这些操作在切换前完成,因为切换后栈就不再是旧进程的了。
第二阶段是 核心切换,分为地址空间切换和寄存器切换。地址空间切换先于寄存器切换,因为寄存器切换后栈指针就变了,不能再访问旧进程的 mm 字段。寄存器切换是最"原子"的一步,两条 movq 指令切换栈指针后,CPU 就运行在新进程的上下文中了。
第三阶段是 finish,由 finish_task_switch() 完成。这里有一个精巧的设计:如果 prev 是内核线程,它的 active_mm 不会被立即释放,而是保存到 rq->prev_mm 中,延迟到 finish_task_switch() 中释放。这是因为切换地址空间时需要锁保护,而 finish_task_switch() 在 runqueue 锁释放后执行,避免了在持锁状态下调用 mmdrop() 可能引发的死锁。
上下文切换的成本:纳秒级的代价
一次上下文切换的直接成本大约在 1-5 微秒之间,具体取决于是否需要切换地址空间。
不需要切换地址空间的场景(线程切换或内核线程切换)成本较低,主要是保存和恢复 6 个 callee-saved 寄存器,加上切换栈指针的指令开销。在 x86_64 上,__switch_to_asm 中的 push/pop 指令大约消耗 20-30 个时钟周期。
需要切换地址空间的场景(用户进程切换)成本显著更高。switch_mm_irqs_off() 不仅要更新 CR3 寄存器,还要刷新 TLB。TLB 刷新后,新进程的前几次内存访问都会触发 page walk,每次 page walk 需要访问多级页表,增加数十纳秒的延迟。
间接成本更加隐蔽但影响更大。CPU 的 L1/L2 缓存中存储的是旧进程的代码和数据,新进程需要重新加载数据到缓存,导致大量缓存未命中。CPU 的分支预测器也需要重新学习新进程的分支模式,流水线效率会暂时下降。这些"冷启动"效应可能让新进程在切换后的几微秒内运行效率低下。
这就是为什么高 cs 值会导致系统性能下降。当每秒上下文切换次数超过 10 万时,累积的开销就会明显影响系统吞吐量。排查这类问题时,可以结合 perf sched 工具分析调度延迟,或者使用 pidstat -w 查看哪些进程的 voluntary/involuntary context switch 次数异常。
总结
上下文切换是调度器的核心操作,它将进程拆分为地址空间和寄存器状态两个独立维度。内核线程通过 active_mm 借用地址空间,避免了页表切换的开销;线程共享 mm_struct,切换成本低于进程。switch_to 汇编代码只保存 callee-saved 寄存器,利用 ABI 约定减少保存量。
互动问题:在你的生产环境中,有没有遇到过因为上下文切换频率过高导致的性能问题?你是如何定位和解决的?欢迎在评论区分享你的经验。
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
