Python+AI数据分析实战:带你玩转数据标注、图像识别与端云协作
- 2026-06-29 17:40:30
上篇文章我们聊了Python调用LLM API的四种方式,从原生 HTTP 到各种 SDK,把「怎么调」这件事掰扯清楚了。但光会调 API 只是起点,下面我们来看看怎么拿它来干活,从数据处理到图片识别,再到端云协作的隐私保护思路,一步步把 LLM API 从「玩具」变成「工具」。

前置准备

开始之前,确认一下我们的工具箱:
| Ollama | ||
| gemma3:270m | ollama pull gemma3:270m | |
| GLM-OCR | ollama pull glm-ocr | |
| Python库 | pip install pandas ollama Pillow |
其中 gemma3:270m 是个非常轻量的模型,普通笔记本就能跑。
而 GLM-OCR 专门用来识别图片中的文字,只有 0.9B 参数,效果也很棒。
关于 GLM-OCR 的一个坑:根据CSDN博主「方-」的教程,Ollama 默认上下文窗口只有 4096 token,处理图片时完全不够用。我们需要创建一个自定义模型来解决这个问题:
# 创建 Modelfilecat > ~/Modelfile <<EOFFROM glm-ocr:latestPARAMETER num_ctx 16384PARAMETER temperature 0TEMPLATE {{ .Prompt }}RENDERER glm-ocrPARSER glm-ocrEOF# 用这个配置重新创建模型ollama create glm-ocr-fix -f ~/Modelfile
后面我们用 glm-ocr-fix 这个名字来调用调整后的模型。
环境就绪,下面开工。

批量标注实战

1.1 场景说明
假设我们从某图书馆拿到了一份藏书目录(Excel 格式,100 条示例记录),现在需要给每本书打上学科门类标签(工学、医学、文学……),方便后续做馆藏分析。
手动分类?要是有一万本书怎么办。
自定义各类别的关键词看命中率?能把 60% 的情况列举出来就够呛。
好在我们有擅长语义理解的 LLM,只要把摘要丢给模型,让它判断学科门类就行了。
而且模型还能顺手帮我们提取几个内容关键词,一眼了解这本书的要点。
看看数据长什么样:
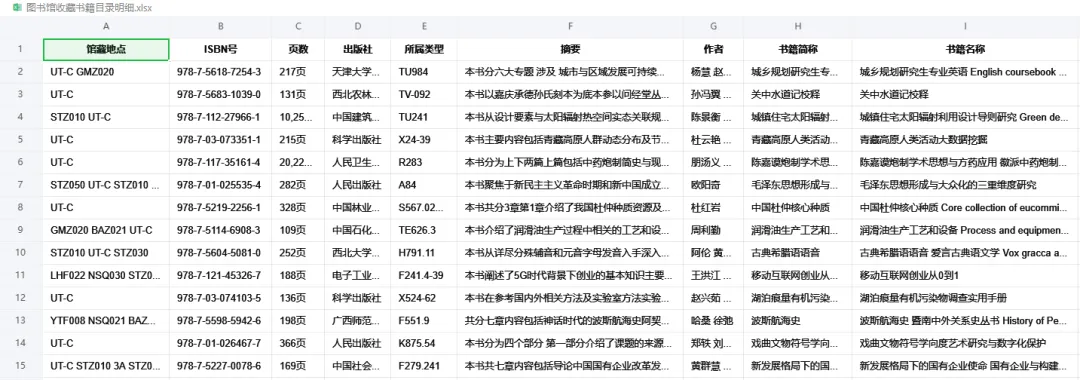
数据有 9 列:馆藏地点、ISBN号、页数、出版社、所属类型(中图分类号)、摘要、作者、书籍简称、书籍名称。
我们主要关注摘要字段,这是一段长短不一的非结构化文本,典型的需要LLM来「理解」的内容。
1.2 构造标注Prompt
标注的核心在于 Prompt 设计。我们给模型一个明确的选择题(从13个学科门类中选一个)和一个开放题(提取3个通俗关键词),并要求输出JSON格式以便程序解析。
def build_prompt(abstract):"""根据书籍摘要构造分类请求,要求返回JSON。"""return ("请根据以下书籍摘要完成两个任务:\n""1. 判断该书属于哪个大学科门类(从以下选一个:哲学、经济学、法学、教育学、""文学、历史学、理学、工学、农学、医学、管理学、艺术学、军事学)\n""2. 提取3个关键词,方便普通读者理解该书主题\n\n"f"摘要:{abstract}\n\n""请仅输出JSON,格式如下,不要输出任何其他内容:\n"'{"学科": "门类", "关键词": ["词1", "词2", "词3"]}')
Prompt 设计要点:
- 给出候选列表
学科门类是固定的13个选项,避免模型自由发挥而不统一,一会儿叫太空,一会儿叫宇宙。 - 限定输出格式
明确要求JSON,后续代码好解析。 - 强调「仅输出JSON」
小模型指令遵从差,有时候会忍不住加上「好的,我的分析如下……」之类的废话,这句话能压一压。
1.3 遍历标注
有了 Prompt,接下来就是逐行遍历 DataFrame,把每条摘要发给模型,解析返回的 JSON:
import ollamaimport jsonimport reMODEL = "gemma3:270m"def annotate(abstract):"""调用ollama本地模型进行标注,返回字典,失败返回None。"""prompt = build_prompt(abstract)resp = ollama.chat(model=MODEL, messages=[{"role": "user", "content": prompt}])text = resp["message"]["content"].strip()# 尝试直接解析JSONtry:return json.loads(text)except json.JSONDecodeError:pass# 兜底:提取```json ... ```代码块中的内容m = re.search(r'```(?:json)?\s*(\{.*?\})\s*```', text, re.DOTALL)if m:try:return json.loads(m.group(1))except json.JSONDecodeError:passreturn None
这里有个重要的兜底逻辑:小模型经常把 JSON 包裹在 markdown 代码块里,或者在 JSON 前后加上多余的文字。re.search 就是为了防止直接解析失败,利用正则从代码块里抠出 JSON 来。
然后循环遍历所有数据:
df["学科门类"] = ""df["通俗关键词"] = ""for i, row in df.iterrows():result = annotate(str(row["摘要"]))if result:df.at[i, "学科门类"] = result.get("学科", "未识别")df.at[i, "关键词"] = ", ".join(result.get("关键词", []))else:df.at[i, "学科门类"] = "未识别"if (i + 1) % 10 == 0:print(f"已标注 {i + 1}/{len(df)}")
来看看结果,牛魔的小模型还不如我读幼儿园的时候表现好
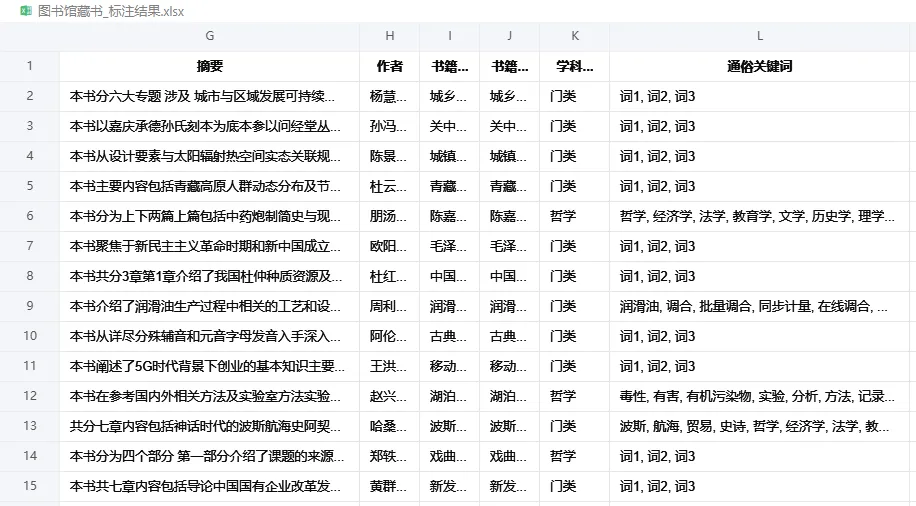 咳咳,预料之中,gemma3:270m 虽然快,但「智商」有限,在开发时用于快速调试流程,跑通了后再用更大的模型(4B及以上效果较好)即可。
咳咳,预料之中,gemma3:270m 虽然快,但「智商」有限,在开发时用于快速调试流程,跑通了后再用更大的模型(4B及以上效果较好)即可。
看看切换 qwen2.5:0.5b 的结果,虽仍有瑕疵,但已好了许多。
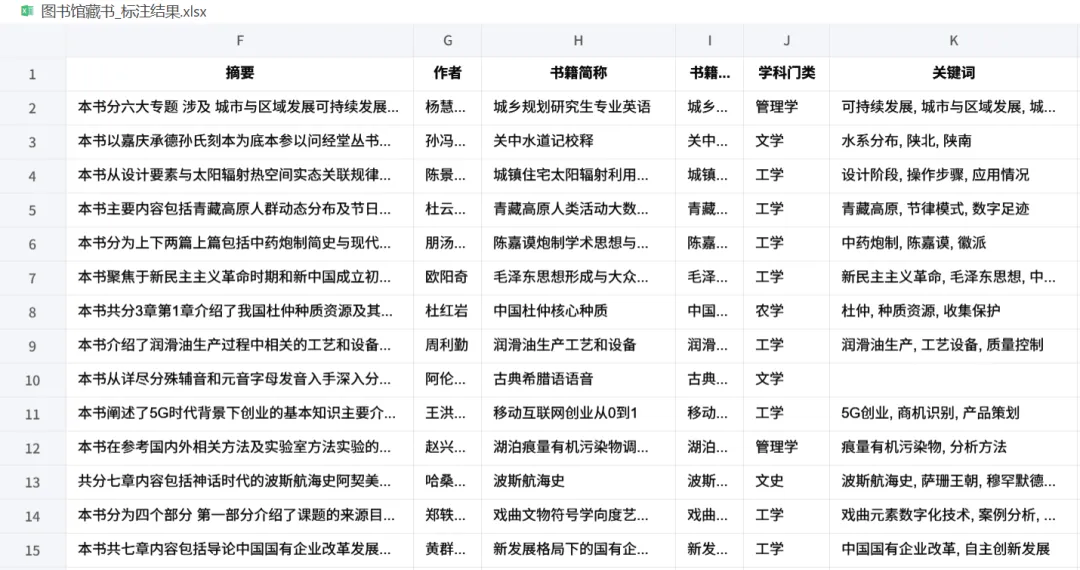 若受限于设备,无法使用更大的模型,对于小模型,我们也可以通过优化提示词、增加前置处理来尝试改善效果。
若受限于设备,无法使用更大的模型,对于小模型,我们也可以通过优化提示词、增加前置处理来尝试改善效果。
1.4 统计与解读
标注完了,100 本书分属哪些学科?统计一下分布:
stats = df["学科门类"].value_counts()stats_text = "【图书馆藏书学科分布统计】\n"for cat, count in stats.items():stats_text += f" {cat}:{count}本({count / len(df) * 100:.0f}%)\n"print(stats_text)
输出:
【图书馆藏书学科分布统计】工学:59本(59%)管理学:14本(14%)文学:10本(10%)文史:4本(4%)哲学:3本(3%)教育学:2本(2%)法学:2本(2%)农学:1本(1%)医学:1本(1%)未识别:1本(1%)文学院:1本(1%)文理:1本(1%)理学:1本(1%)...
到这里,如果只是一串数字,好像少了点什么。我们不妨再调一次LLM,把统计文本喂给它,让它写一段「馆藏特色分析」:
analysis_prompt = ("以下是一所高校图书馆的藏书学科分布数据:\n\n"f"{stats_text}\n""请用200字左右分析该馆藏的学科特色、覆盖情况,并给出优化建议。")analysis_resp = ollama.chat(model=MODEL,messages=[{"role": "user", "content": analysis_prompt}],)analysis = analysis_resp["message"]["content"].strip()print("\n===== LLM生成的馆藏分析 =====")print(analysis)
小模型没有完全遵从 200 字的限定,balabala了一大堆,看起来有理有据:
根据图书馆藏书学科分布统计,工学、管理学和文学分别占全馆藏书总数的59%,管理学和文史占38%,人文社科类占比约41%。而医学、法学等专业类别在各门类中占据了较高的比例。### 学科特色分析- 工学:以工学学科为主,涵盖多个领域如机械工程、软件工程等,显示出较强的技术背景和应用能力。- 管理学:管理学涵盖了商业管理和行政管理等多个方面,强调政策制定和执行层面的理论与实践。- 文学:文学学科包括汉语言文学、新闻学、传播学等,注重对文本的解读和分析,具备丰富的文化内涵和社会价值。- 文史:文史涵盖历史学、文学、哲学等领域,重视传统文化和现代思想的交融,反映了一个国家的文化底蕴。### 覆盖情况该馆藏书主要涵盖了工学、管理学和文学等多个专业领域,并且各个类别之间的平衡性较好。然而,在某些细分领域如医学、法学等学科中,存在一些 较为薄弱的分类。例如,对于“法律”这样的主题,由于其复杂性和多样性的特点,可能需要进一步加强与该领域的关联。### 优化建议1. **完善专业领域划分**:针对“法律”、“医学”等专业领域,增加与其相关的其他学科或类目,以提高馆藏的专业覆盖范围和深度。2. **细化分类标准**:在现有的学科类别中加入更多细分的科目,如将历史学、哲学与法学相结合,形成一个更加全面的学术体系。3. **优化学科布局**:根据图书馆馆藏实际情况,合理规划各类资源的分布,确保每个专业领域都有相对独立的图书馆空间和信息流。通过上述措施,可以更好地展示该馆的学术特色,并提升其服务质量,吸引更多的读者群体。
这就体现了LLM的两种用法:第一次调用是做数据清洗,第二次调用是做分析解读。需要精确统计的部分,依然交给 Python。
至此,我们完成了一个基础的数据分析流水线:加载数据 → 构造Prompt → 批量遍历 → 统计结果 → LLM解读。

简历解析实战

2.1 场景说明
以前(这得是多久以前,总之假设一个场景啦),HR部门可能会面临一个头疼的问题:收到的简历五花八门,有PDF的、有Word的、甚至还有拍照截图的。要把这些简历信息录入管理系统,人工逐份敲进去效率极低。
我们来看这几份 AI 生成的模拟简历截图:有中文有英文、排版复杂、信息密度很高。

目标也很明确:把图片变成结构化的表格数据。
这个任务分两步走:
- 文字识别
用 GLM-OCR 模型把图片里的文字「抠」出来 - 结构化提取
用 LLM 从识别的文本中提取统一字段,合并到一个 DataFrame
GLM-OCR 也有一定的思考能力,可以直接整理格式,为了更好的效果,只让它做原文提取,整理则交给其他模型。
2.2 从图片到文字
首先创建两个基础函数:一个把图片转 Base64,一个调用视觉模型。
import base64from io import BytesIOfrom PIL import Imageimport ollamaOCR_MODEL = "glm-ocr-fix"def image_to_base64(img: Image.Image, fmt: str = "PNG") -> str:"""将PIL Image转换为Base64字符串,供Ollama API使用。"""buffer = BytesIO()img.save(buffer, format=fmt)buffer.seek(0)return base64.b64encode(buffer.read()).decode("utf-8")def ocr_image(img: Image.Image, page_num: int) -> str:"""使用本地glm-ocr模型对图片进行文字识别。"""img_b64 = image_to_base64(img)prompt = ("请对图片中的所有文字进行完整识别,""按照原始布局顺序输出全部文本内容,""不要遗漏任何字段,不要添加解释或总结,""直接输出识别到的文字。")response = ollama.chat(model=OCR_MODEL,messages=[{"role": "user","content": prompt,"images": [img_b64],}],)text = response["message"]["content"].strip()print(f" [OCR] 第 {page_num} 张识别完成,字符数: {len(text)}")return text
打开一张简历试试:
img = Image.open("模拟简历1.png")ocr_text = ocr_image(img, 1)print(ocr_text[:500])

GLM-OCR 的识别效果相当不错,中英文混排下,姓名、电话、邮箱、工作经历等,基本都能准确识别出来。
2.3 从文字到字段
GLM-OCR 给了我们一大坨文本,但我们需要的是结构化的字段:姓名、电话、学历、工作经历……每份简历的排版不一样,字段顺序也不一样,手动用正则去匹配要费老大劲儿。
下面我们定义了10个统一字段,无论简历是中文还是英文、是产品经理还是数据分析师,都往同一个模板里填。
LLM 自己会「归纳」,不需要我们针对不同格式的简历写不同的解析规则。
因简历原始文本都超过千字,这里切换了 9B 的 glm4:latest 模型来确保智力下限。
LLM_MODEL = "glm4:latest"FIELDS = ["姓名", "电话", "邮箱", "求职岗位", "学历","毕业院校", "工作经历", "项目经历", "核心技能", "个人评价",]def extract_fields(ocr_text):"""将OCR文本交给LLM提取统一的结构化字段,返回字典。"""prompt = ("以下是一份简历的文字内容,请提取以下字段并以JSON格式输出,""不要输出任何其他内容:\n\n"'{"姓名": "", "电话": "", "邮箱": "", "求职岗位": "", ''"学历": "", "毕业院校": "", "工作经历": "", "项目经历": "", ''"核心技能": "", "个人评价": ""}\n\n'"注意事项:\n""- 工作经历和项目经历将多段经历合并为一段概述文字\n""- 核心技能用左斜杠分隔\n""- 找不到的字段填:未知"f"\n简历内容:\n{ocr_text}")resp = ollama.chat(model=LLM_MODEL,messages=[{"role": "user", "content": prompt}],)text = resp["message"]["content"].strip()try:return json.loads(text)except json.JSONDecodeError:pass# 兜底逻辑(同第一章)m = re.search(r'```(?:json)?\s*(\{.*?\})\s*```', text, re.DOTALL)if m:try:return json.loads(m.group(1))except json.JSONDecodeError:passreturn None
2.4 批量处理与合并输出
最后把图像识别和结构化提取串起来,循环处理每份简历,合并成一个DataFrame:
resumes = []for idx, filename in enumerate(["模拟简历1.png", "模拟简历3.png"]):print(f"\n--- 处理: {filename} ---")# 第一步:OCR识别img = Image.open(filename)ocr_text = ocr_image(img, idx + 1)# 第二步:LLM结构化提取info = extract_fields(ocr_text)if info:row = {field: info.get(field, "未知") for field in FIELDS}resumes.append(row)print(f" 解析成功:{row['姓名']}")else:print(f" 解析失败:{filename},跳过")# 合并为DataFrame并输出Exceldf = pd.DataFrame(resumes, columns=FIELDS)df.to_excel("简历汇总.xlsx", index=False)print(f"\n共处理 {len(resumes)} 份简历,已保存至 简历汇总.xlsx")
整个流程也是一条清晰的流水线:图片 → 识别原文 → 整理格式 → DataFrame → Excel。
每份简历的每个字段都整整齐齐地躺在表格里,想筛选、想统计、想导入系统,或进一步处理都方便。

为什么不直接让多模态大模型一步到位地看图提取字段?答案是为了解耦。
视觉模型(VLM)专职做文字识别,精度高且可控;LLM 专职做信息提取,专注于语义理解。
两步拆开,哪步出了问题都好排查,而且图像识别结果可以存档复用,后续换个 LLM 或者换套提取规则,不需要重新跑识别。

端云协作启示

3.1 隐私问题:数据里的「炸弹」
在简历解析中,我们提取到了姓名、电话、邮箱等个人信息。这些数据有个专业名词叫PII(Personally Identifiable Information,个人可识别信息)。
如果我们的 LLM 是跑在本地的,那没问题,数据从头到尾没出过这台机器。
但如果我们把简历原文直接丢给某个云端 AI 来做分析呢?那这些敏感信息就被传到了别人的服务器上。
对于个人项目来说可能无所谓,但如果是政府、金融、医疗等领域,数据安全就不是小事了。
但本地模型需要的硬件配置太高,小模型又太笨怎么办?
3.2 端云协作:鱼与熊掌兼得
聪明如我们,已经掌握了本地模型和云端模型的调用方法。那我们就可以设计一个本地脱敏 + 云端分析的协作流程:
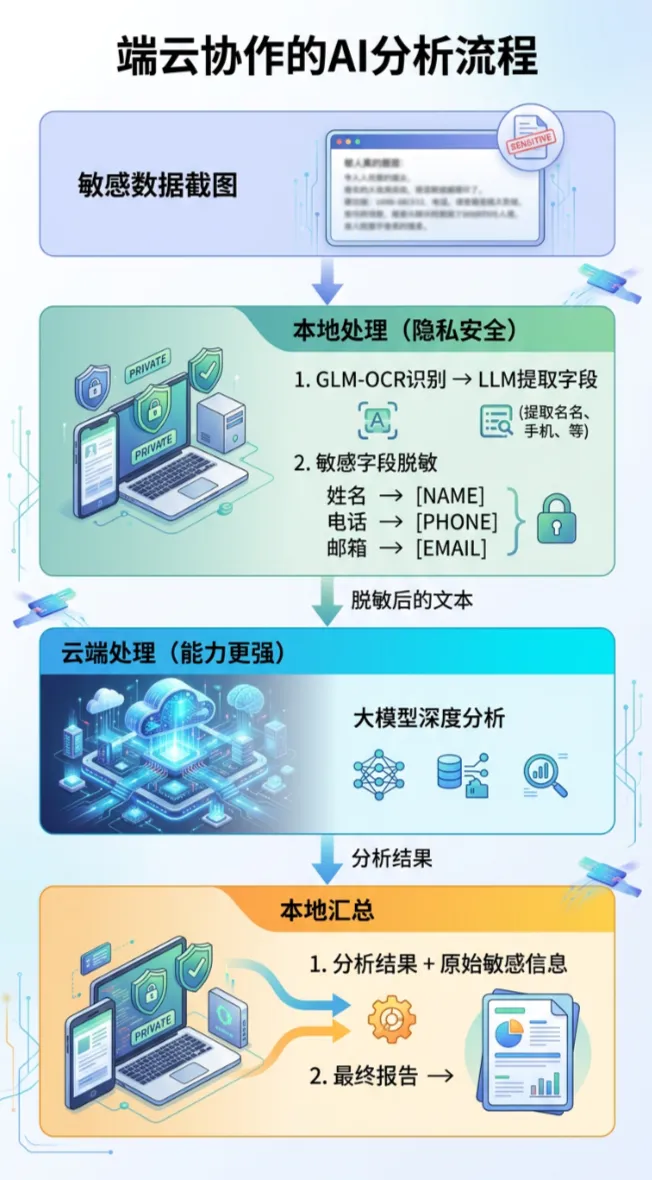
基于这两期的内容,相信大家已经能自己动手实现,快去试试吧!~
3.3 适用场景延伸
这种「端云协作」的思路,凡是对数据隐私有要求、同时又不想放弃云端大模型强大分析能力的场景,都可以套用这个模式:
医疗场景:本地模型从病历中提取患者信息并脱敏,云端模型基于脱敏病历做辅助诊断建议,本地再把建议和患者信息关联。患者隐私不出医院,诊断质量不打折。
法律场景:本地模型从合同文本中提取当事方信息和敏感条款并脱敏,云端模型做合同风险评估和条款合规性分析。客户的商业机密始终留在本地。
金融场景:本地模型处理客户的账户流水和身份信息并脱敏,云端模型做投资偏好分析和理财建议。金融数据的安全性得到保障。
本质上,这是一种数据分级分类处理的策略:敏感数据用本地小模型处理(够用就行),非敏感数据交给云端大模型增值(能力拉满)。
在AI落地的过程中,隐私合规往往是最后一道门槛,而端云协作恰好给了我们一个既安全又强大的解决方案。

后记

快速回顾:
第一章我们用一个轻量模型完成了 100 本书的批量学科标注,体验了 LLM 在非结构化数据处理中的「打标」能力。核心收获:Prompt 设计和模型参数规模影响标注质量,兜底逻辑决定系统健壮性。
第二章我们用 GLM-OCR + LLM 的两步流水线,把简历截图变成了结构化的 Excel 表格。核心收获:VLM负责「看」,LLM负责「懂」,解耦设计让每一步都可控
第三章我们从隐私角度出发,梳理了端云协作的设计思路。核心收获:本地做脱敏,云端做分析,安全与能力可以兼得。
当我们把 LLM 当成数据处理流水线中的一个环节,一个能理解语义、能结构化输出的超级函数,它的应用场景就能无限延伸了。
希望这篇文章能给大家一些启发,在自己的业务场景中找到 LLM API 的用武之地。vibe coding 吧,下一篇见!~
这里是 Seon塞翁,emmm接下来写什么好呢,整点不用自己编码的 vibe coding 吧,下一篇见!~

谢谢阅读, 如果本文对你有帮助, 随手点赞、收藏、转发吧!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 我用AI+Python做了一个数据分析智能体
- Linux:虚拟机静态IP网络配置步骤
- Mac 上跑 Linux 容器不再靠 Docker!苹果开源 container,每个容器独立虚拟机VM
- 2026年星芒算法挑战赛(Python中学组)—预选赛—51~60题解题思路
- Rocky Linux 9 SSH登录后中文不显示?一篇教会你完整排查与修复
- Linux 串口调试痛点,终于有人解决了.
- Linux Initcall 机制完全解析
- 保姆级教程:在 WSL2 Linux 上交叉编译 Windows 程序(含 6 个真实踩坑)
- 【Java编程巅峰赛】一赛双证!考试原题练习!
- 20个,强大的Python办公自动化库!
