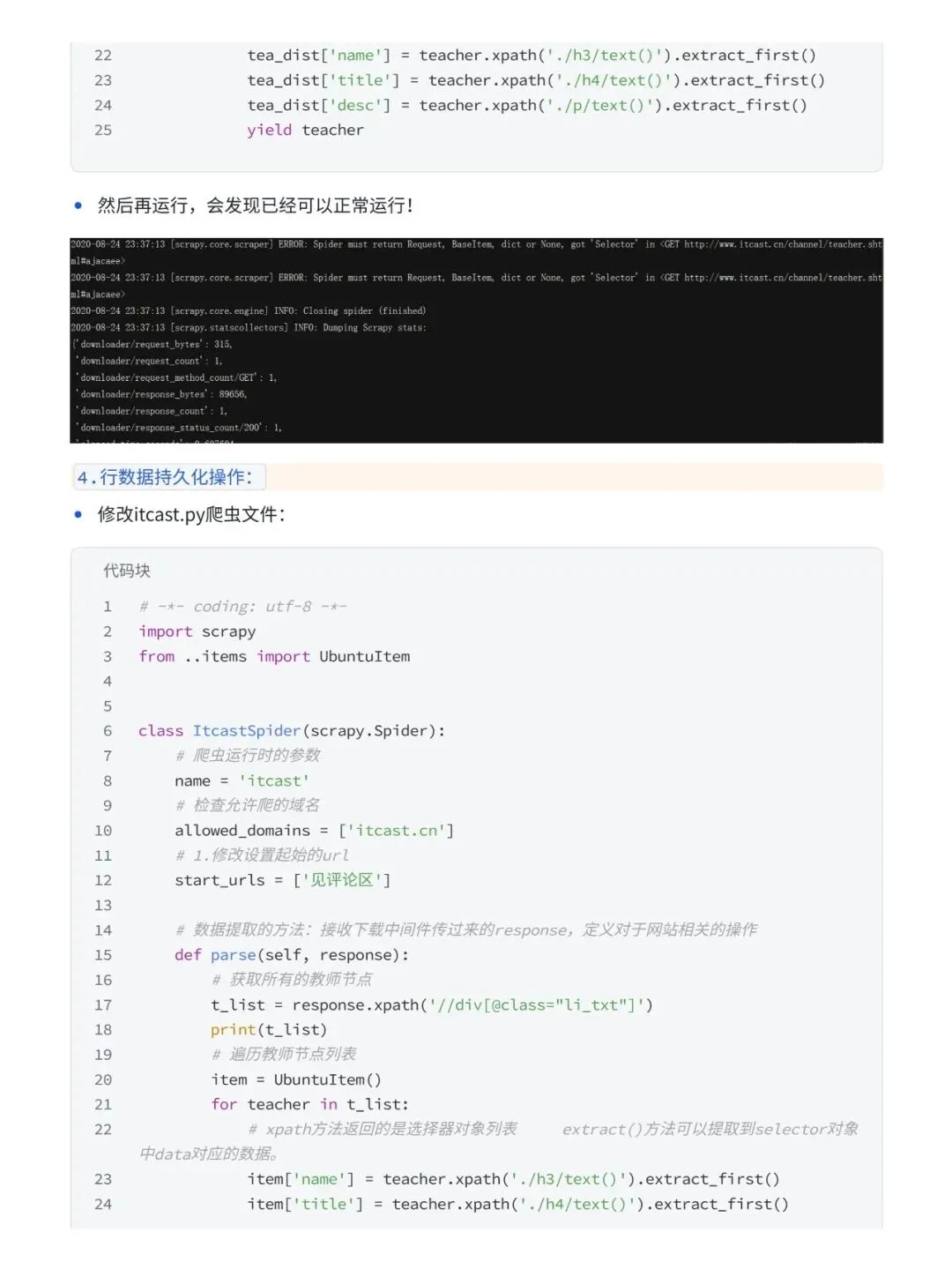
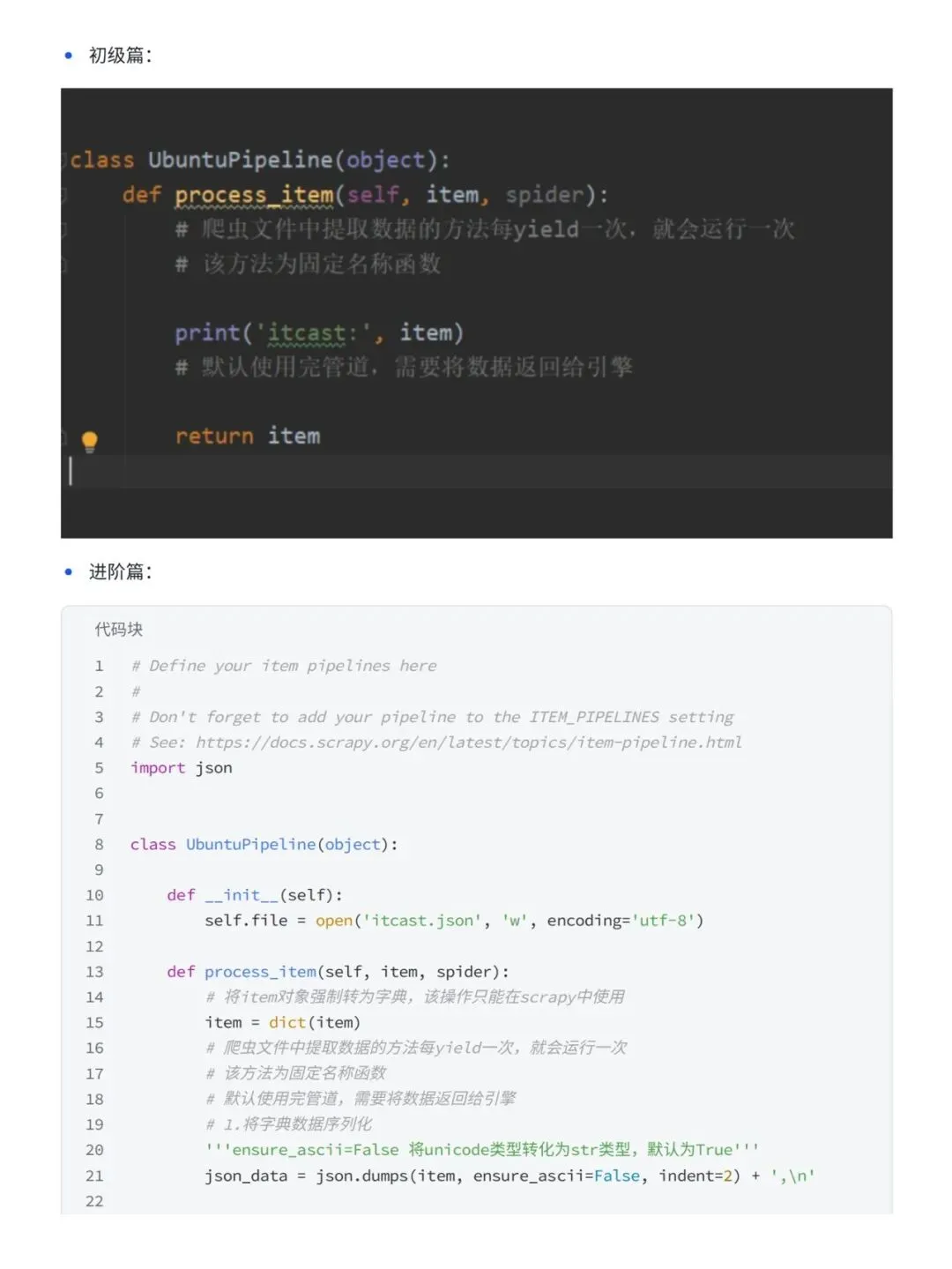
很多人学 Python 爬虫,第一步就卡住了。
不是不会写代码,而是不知道 请求怎么发、网页怎么解析、数据怎么提取、反爬怎么处理。
这次整理了一份Python 爬虫实战解析,覆盖:
HTTP/HTTPS、HTML解析、XPath/CSS选择器、Robots协议、反爬机制、数据清洗、数据存储、Scrapy框架。
从基础概念到完整案例都有,适合新手入门,也适合想做数据采集、自动化处理的小伙伴。
学爬虫别只抄代码,先把流程跑通。
~