我做了这次手动报告实验,一共验证两个问题。
这次不是NotebookLM自动调研,是我自己上传Qwythos-9B的实验记录,指定公众号账号和「Charlie实验室」栏目,让Pipeline跳过NotebookLM,直接进入writer和self_review。
这个过程本身就是一次实验——当研究报告由人提供,AI写作系统还会不会把材料误当成外部引用。
结果确实暴露出问题:writer仍默认引入材料来源类表述,说明它没有真正理解,这里所有证据都是我上传整理的第一手实验内容,不需要额外找外部引用背书。
这次实验记录显示,Qwythos-9B已经能在4GB显存的普通笔记本上,完成基础Python代码生成和Three.js 3D游戏框架输出。
我在执行现场看到,它能顺利生成在线版Claude因内容规则限制拒绝输出的可用代码,这个效果和宣传完全一致。
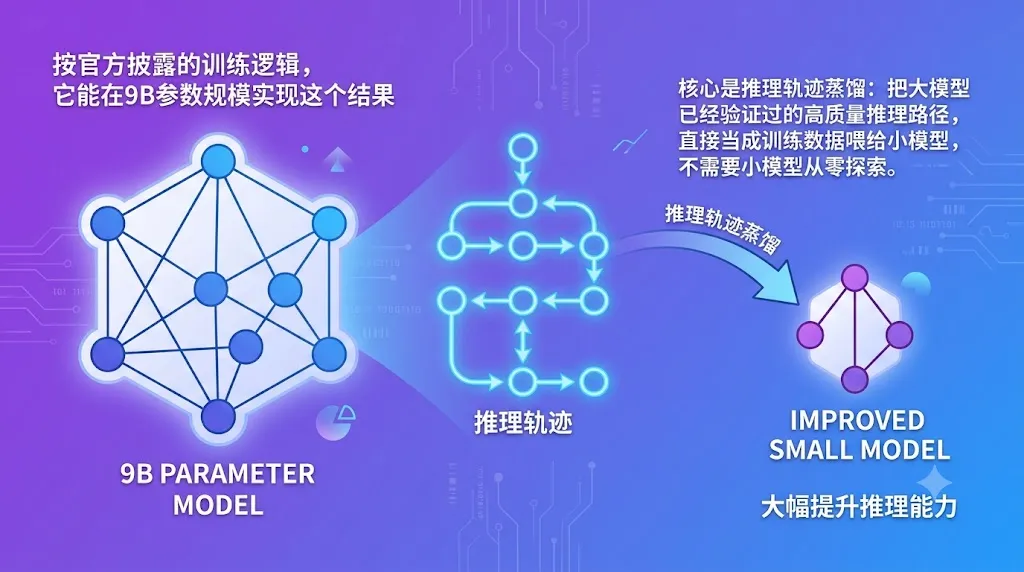
按官方披露的训练逻辑,它能在9B参数规模实现这个结果,核心是推理轨迹蒸馏:把大模型已经验证过的高质量推理路径,直接当成训练数据喂给小模型,不需要小模型从零探索。
Qwythos-9B的真正意义,是证明了小参数模型的能力上限由数据质量决定,不是由参数规模决定。
那它真的能替代在线版Claude吗?这次实验记录显示,分场景给出结论才成立。
目标拆解清晰的执行类任务,比如生成合规规则限制的代码,或者输出基础可运行的3D游戏框架,它完全能满足需求,而且本地部署不用付订阅费,数据不会外流,刚好解决特定场景痛点。
但处理复杂项目级开发需求时,它的稳定性差很多。
在线版Claude能自动拆分多模块需求,一步步输出可对接的代码,出错后也能按提示调整逻辑。
Qwythos-9B会把所有模块揉成一团输出,出现大量接口不对接、变量未定义的错误,反复调整后才得到可用版本,需要人工修改的地方远多于在线版Claude。
宣传里的百万上下文卖点,实际用在跨文件项目推理时,速度会明显衰减,找依赖关系的准确率也远达不到在线版Claude的水平。
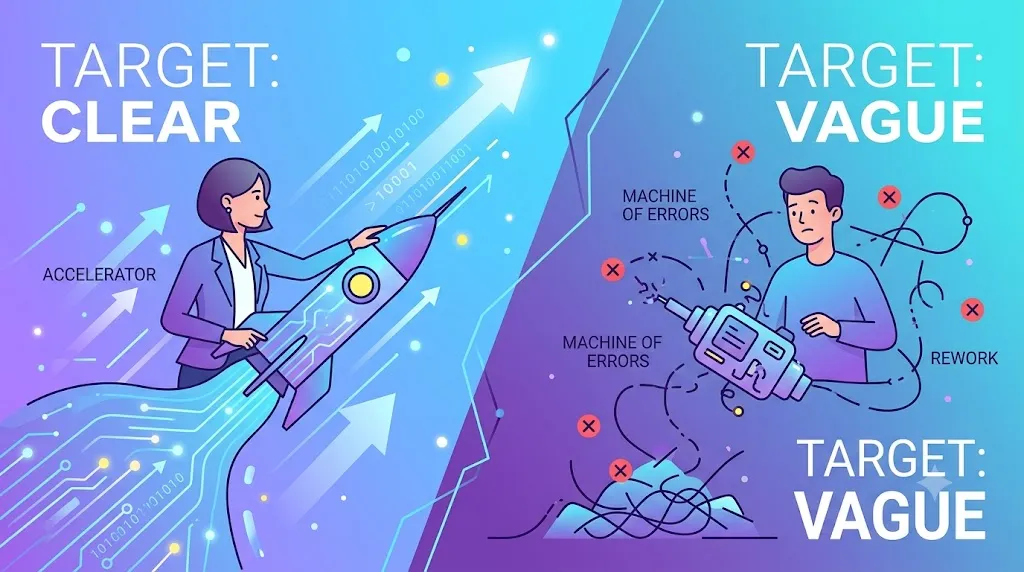
这件事对我最直接的提醒是,这个结果刚好印证了一个明确的观察:同一个工具,在目标明确的人手里是加速器,目标含混时就会变成制造错误和返工的机器。
Default模式下AI全权执行,Auto-review模式下AI输出后人做校准,Full Access模式下只让AI做分层拆分,三种责任分配方式,对应完全不同的结果。
Workspace Mode本质是可回滚的责任缓冲,不是单纯让操作更方便的功能。
多模型协作的核心从来不是模型越多越强,而是入口、记忆、执行、审查和验收分层清晰。
Agent时代正在发生的变化是,AI能力越来越强,执行成本越来越低,最后留在人手里的工作,就是定义目标、判断对错、校准结果。
AI越能接近执行现场,越考验人能不能说清楚责任分配:谁提供训练数据,谁做结果判断,谁对最终输出负责。
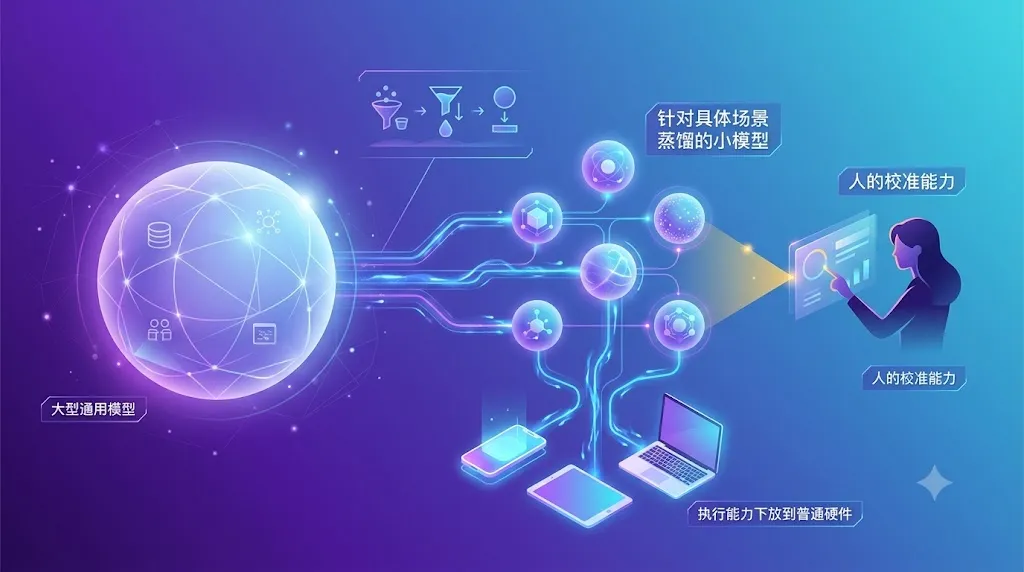
判断Qwythos-9B能不能替代Claude还早,但方向已经清楚:未来会有越来越多针对具体场景蒸馏的小模型,把大模型的执行能力下放到普通硬件,而人的校准能力,会变得越来越稀缺。
这件事背后,职业形态的变化已经开始出现:过去写代码的核心能力是亲手敲出正确逻辑,未来写代码的核心能力是给AI说清需求、校准结果、验收质量,专业开发者会从亲手执行的工程师,变成给AI定标准的校准师。
你在本地部署AI模型的时候,遇到过最头疼的问题是什么?
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
