streamlit 这几年在数据科学圈子里火得很快。不用学前端,不用折腾路由,纯 Python 就能把数据分析脚本变成像模像样的 Web 应用。但真要拿它做点正事 —— 比如搭一个多页面的数据看板,接上数据库,处理用户上传的文件 —— 光看官方文档的入门示例是不够的。
这篇文章是我在实际项目中反复用到的模式总结。不讲花活,只写真正用得上的东西:多页面怎么拆、数据库怎么连、文件怎么读写。每个章节都配了可运行的代码,拿过去改改就能用。
一、多页面应用
单个脚本塞下所有逻辑,调试时翻半天找不着北 —— 这是每个 Streamlit 新手都会踩的坑。好在框架本身提供了两种拆分页面的方式,按需选用就行。
多页面不是什么新概念,但它确实是组织复杂应用最直接的手段:把不同的功能模块分开,用户导航清晰,你自己维护起来也省心。
1.1 使用Session State实现多页面交互
这是最原始也最灵活的做法 —— 页面切换逻辑完全由你自己控制,所有代码堆在一个文件里,靠 st.session_state 记住当前在哪个页面。
「思路很简单:」 拿一个变量(比如 session_state.page)记下当前选中的页面名,侧边栏放个 radio 或 selectbox 当导航用,根据变量值走到对应的渲染函数。
拆开来看就三块:
导航栏:用于切换页面的导航栏,可以是按钮、链接或下拉菜单等形式。
页面内容:不同页面的具体内容和功能模块,可以通过导航栏进行切换。
状态管理:保持和管理不同页面之间的状态数据,确保用户在切换页面时数据不会丢失。
以下示例实现了两个页面的切换 —— 主页和导航页,导航栏放在侧边栏,切换时只改 session_state['page'] 的值就行:
import streamlit as stHOME_PAGE_TITLE = "主页"ABOUT_PAGE_TILE = "导航"defpage_home(): st.title(HOME_PAGE_TITLE + "页面")defpage_about(): st.title(ABOUT_PAGE_TILE + "页面")defmain():# 设置初始页面为Home session_state = st.session_stateif'page'notin session_state: session_state['page'] = HOME_PAGE_TITLE# 导航栏 page = st.sidebar.radio('导航', [HOME_PAGE_TITLE, ABOUT_PAGE_TILE])if page == HOME_PAGE_TITLE: page_home()elif page == ABOUT_PAGE_TILE: page_about()if __name__ == '__main__': main()
这段代码跑起来是这样的:首次加载时 session_state 里还没有 page 这个键,于是默认切到 "主页";侧边栏渲染一个 radio,用户点哪个选项,page 就变成哪个值,if/elif 分支决定执行哪个页面函数。从头到尾都在一个脚本里完成,没什么黑魔法。
效果:
适合页面不多、页面之间需要频繁传参的场景 —— 函数调用传参比跨文件共享状态直观多了。
优点:
- 简单易用:不同页面之间传递和保存状态数据变得非常简单。只需使用字典来存储和访问状态数据,无需复杂的配置或额外的库。
- 跨页面数据共享:整个生命周期中保存和访问特定于会话的变量。多个页面之间共享数据,可以传递复杂的数据结构,如字典、列表等。
- 可扩展性:应用程序中添加新的页面,并在不同页面之间保持数据的一致性。易于管理和维护,可以随着需求的增长进行扩展和修改。
- 状态持久化:刷新应用程序或重新运行应用程序时保留状态数据。这对于用户来说非常方便,他们可以在应用程序的不同会话之间保持他们的工作状态。
缺点:
- 内存消耗:数据存储在应用程序的内存中,当应用程序的状态数据变得庞大时,内存消耗较大。
- 无持久化方案:数据存储在应用程序的内存中,仅在应用程序运行期间存在。应用程序停止运行或重新启动时数据将丢失。
- 难以调试:在应用程序的多个页面之间传递和共享数据,当出现问题时,追踪和调试可能会比较困难。特别是在复杂的多页面应用程序中,正确地处理和管理Session State变量可能会变得复杂。
1.2 Streamlit内置多页面方案
从 1.10 版本开始,Streamlit 把多页面做进了框架内部。你只管往 pages/ 目录扔 .py 文件,剩下的 —— 页面发现、导航生成、URL 映射 —— 框架全包了。
路由逻辑零代码,但代价是灵活性受限。后面会详细讲。
my_app/├── 首页.py # 入口文件(通常作为首页)"streamlit run" 命令来运行的文件└── pages/ ├── 01_页面A.py ├── 02_页面B.py ├── 03_页面C.py
每个页面对应一个独立的 Python 脚本,页面切换时前端不刷新,体验比传统的后端渲染流畅不少。
「首页」 —— 入口文件,用 st.page_link 给各子页面提供快捷跳转:
# 首页.pyimport streamlit as stst.set_page_config(page_title="首页", page_icon="🏠")st.title("🏠 首页")st.page_link("pages/01_页面A.py", label="→ 页面 A")st.page_link("pages/02_页面B.py", label="→ 页面 B")st.page_link("pages/03_页面C.py", label="→ 页面 C")
「页面 A」 —— 随手生成一组随机数画折线图,展示数据可视化的基本用法。
# 01_页面A.pyimport streamlit as stimport pandas as pdimport numpy as npst.set_page_config(page_title="页面A", page_icon="📊")st.title("📊 图表展示")df = pd.DataFrame(np.random.randn(20, 3), columns=["A", "B", "C"])st.line_chart(df)
「页面 B」 —— 一个输入框加一句问候,几行代码演示交互逻辑。
# 01_页面B.pyimport streamlit as stst.set_page_config(page_title="页面B", page_icon="📋")st.title("📋 输入组件")name = st.text_input("你的名字")if name: st.success(f"你好,{name}!")
「页面 C」 —— 一个按钮触发 loading 和气球,展示 Streamlit 自带的 UI 反馈效果。
# 01_页面C.pyimport streamlit as stimport timest.set_page_config(page_title="页面C", page_icon="⚙️")st.title("⚙️ 状态演示")if st.button("点我"):with st.spinner("加载中..."): time.sleep(1) st.balloons()
四个文件凑在一起就是一个完整的多页面骨架了,实际用的时候把里面的假数据换成真实查询就行。
效果:
动态路由与分配机制
内置方案有两层:「静态发现」是默认行为,「动态分配」给了你更大的控制权。
1. 静态发现(文件扫描)
启动时框架扫描 pages/ 目录,按文件名规则解析出每个页面的标题和排序:
pages/├── 01_📊_数据可视化.py → 排序: 1, 标题: "数据可视化", 图标: 📊├── 02_📋_数据表格.py → 排序: 2, 标题: "数据表格", 图标: 📋└── 03_📝_表单.py → 排序: 3, 标题: "表单", 图标: 📝
规则不复杂:{序号}_{图标/英文}_{标题}.py,序号管排序,剩余部分去掉下划线就是页面名。
2. 动态分配(st.navigation)
1.36 版本之后,可以用 st.navigation() 和 st.Page 在代码里显式声明页面列表。不用再依赖文件扫描,导航结构完全由你编程控制。
「最大的好处:」 可以根据条件决定显示哪些页面。比如管理员才看得到后台入口,普通用户根本不知道有这个页面存在。
# 首页.pyimport streamlit as st# 定义页面函数(或引用外部模块)defpage_dashboard(): st.title("仪表盘") st.metric("在线用户", 128)defpage_settings(): st.title("设置") st.toggle("深色模式")defpage_admin(): st.title("管理后台") st.write("仅管理员可见")# ---- 动态构建导航 ----# 根据用户角色决定哪些页面可用is_admin = st.session_state.get("is_admin", False)nav_pages = [ st.Page(page_dashboard, title="仪表盘", icon="📊"), st.Page(page_settings, title="设置", icon="⚙️"),]# 管理员才显示后台页面if is_admin: nav_pages.append(st.Page(page_admin, title="管理后台", icon="🔐"))# 通过 st.navigation 注册动态路由pg = st.navigation(nav_pages, position="sidebar")pg.run()
3. 引用外部文件作为 Page
st.Page 除了接收函数,也可以直接指向文件路径或外部模块:
import streamlit as st# 方式一:引用文件路径data_page = st.Page("pages/01_📊_数据可视化.py", title="数据看板", icon="📊")# 方式二:引用模块中的函数from my_pages import analytics, reportspg = st.navigation([ data_page, st.Page(analytics.main, title="分析", icon="📈"), st.Page(reports.main, title="报表", icon="📑"),])pg.run()
4. 路由分配原理
st.navigation() 内部做了四件事:
- 「收集」:接收
st.Page 对象列表,每个对象包含目标(函数或文件路径)、标题、图标。 - 「渲染导航」:根据
position 参数在侧边栏或顶部渲染导航组件。 - 「匹配路由」:解析当前 URL hash,匹配到对应 Page 后执行其函数或脚本。
- 「动态更新」:导航列表每次 rerun 都会重建,所以
st.session_state 一变化,菜单立刻跟着变。
# 一个完整的登录/注销路由示例import streamlit as stdeflogin(): st.title("登录") user = st.text_input("用户名")if st.button("登录"): st.session_state.logged_in = True st.session_state.username = user st.rerun()defhome(): st.title(f"欢迎, {st.session_state.username}")deflogout(): st.title("已退出")if st.button("重新登录"): st.session_state.logged_in = False st.rerun()# ---- 动态路由分配 ----ifnot st.session_state.get("logged_in"): pg = st.navigation([st.Page(login, title="登录", icon="🔑")])else: pg = st.navigation([ st.Page(home, title="首页", icon="🏠"), st.Page(logout, title="退出", icon="🚪"), ])pg.run()
效果很直接:没登录时只有登录页,登录后变成首页和退出。页面里不需要写任何权限判断,路由层面就拦住了。
5. 静态发现 vs 动态分配对比
优点:
「零代码路由」:只需将 .py 文件放入 pages/ 目录即可自动注册为页面,侧边栏导航自动生成,无需手动编写路由逻辑。添加或删除页面只需操作文件,维护成本极低。
「按需加载,性能更好」:每个页面是独立脚本,Streamlit 仅在用户点击时加载目标页面,不会一次性加载所有页面代码。页面切换无需重新加载前端,速度极快。
「独立配置,互不干扰」:每个页面可以独立调用 st.set_page_config(),拥有自己的标题、icon、布局模式(wide/centered)和侧边栏状态。
「URL 天然隔离」:每个页面对应独立的 URL 路径(如 /首页、/pages/01_页面A),用户可以直接通过 URL 访问特定页面,也方便分享链接。
「降低耦合」:各页面代码位于不同文件,团队协作时可以并行开发不同页面,冲突更少。单个页面出错不会影响其他页面的渲染。
「文件名即文档」:通过编号前缀和文件名就能快速了解应用的页面结构和流程,无需查看代码即可理解导航层级。
缺点:
「跨页面通信隐式且脆弱」:页面之间没有显式的数据传递机制,完全依赖 st.session_state 共享数据。页面 A 写入的 key,页面 B 必须"魔法字符串"般精确匹配,缺乏类型检查和契约约束,重构时容易遗漏。
「无法直接传递参数」:内置方案不支持页面间路由参数(如 /page?id=123)。如果页面 B 需要页面 A 的某个值,只能通过 session_state 中转,无法从 URL 直接获取。
「不支持嵌套页面」:pages/ 目录仅支持一级,不能创建子目录实现层级导航。对于复杂应用(如"系统管理 → 用户管理 → 用户详情"),只能通过数字前缀扁平排列,导航结构不够直观。
「文件名影响运行时行为」:页面标题和排序由文件名决定,修改文件名意味着改变 URL 和导航栏显示。文件名既要兼顾可读性又要控制排序,中英文混用或 emoji 的使用受限于操作系统兼容性。
「无页面级守卫/中间件」:不能在页面加载前插入统一的鉴权、重定向或日志逻辑。如果某个页面需要登录才能访问,只能在每个页面脚本内重复编写校验代码。
「Session State 的"幽灵依赖"」:页面之间通过共享状态产生隐式耦合。排查问题时难以追踪哪个页面在何时修改了某个状态变量,调试跨页面 Bug 需要手动梳理数据流。
「冷启动慢」:虽然单页面加载快,但每个页面是独立的 Python 模块,首次加载仍有解释开销。页面数量多时,尽管不会一次加载,但用户遍历多个页面时的累计等待时间不可忽略。
二、数据库与数据源连接
数据应用离不开数据库。Streamlit 用 st.connection() 一个 API 统一了各类数据源的接入方式,自带连接缓存和 secrets 凭据注入,不用每次查询都重新建立连接。
支持数据库如下:
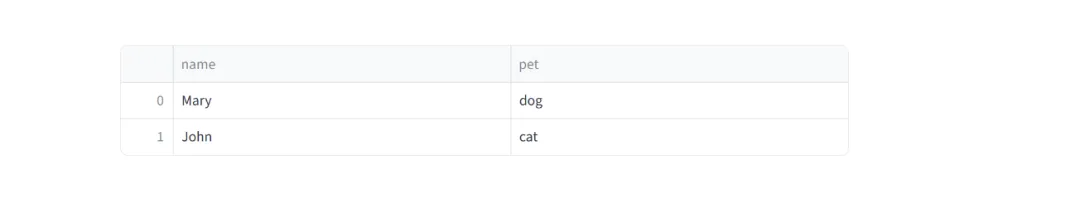
下面以最常用的 MySQL 为例,先建好测试表:
CREATEDATABASE pets;USE pets;CREATETABLE mytable (namevarchar(80), pet varchar(80));INSERTINTO mytable VALUES ('Mary', 'dog'), ('John', 'cat'), ('Robert', 'bird');
上面建了一个 pets 库和 mytable 表,塞了三条数据进去。
依赖安装:
pip install sqlalchemypip install mysqlclient
2.1 st.connection
st.connection 是目前推荐的连接方式,核心思路很简单:「一次定义,全局复用」。框架会自动缓存连接对象,并且优先从 secrets 文件里取配置。
基本用法 —— 指定连接名、类型和数据库 URL,然后就可以执行参数化查询:
import streamlit as stconn = st.connection("mysql", type="sql", url="mysql://root:123456@localhost:3306/pets")df = conn.query("SELECT * FROM mytable WHERE pet != :pet", params={"pet": "bird"})st.dataframe(df)
换其他数据库也一样,改 URL scheme 就行。st.connection 底层走 SQLAlchemy,所以理论上支持所有它兼容的数据库。下面是 SQLite 和 PostgreSQL 的例子,顺便演示了如何用底层 session 执行写入操作:
import streamlit as st# SQLite(内置支持,直接用)conn = st.connection("my_db", type="sql", url="sqlite:///data.db")# PostgreSQL(需要 pip install psycopg2)conn = st.connection("pg", type="sql", url="postgresql://user:pass@localhost:5432/mydb")# 查询df = conn.query("SELECT * FROM users WHERE age > :min_age", params={"min_age": 18})st.dataframe(df)# 写入(使用底层连接)with conn.session as s: s.execute("INSERT INTO logs (msg) VALUES (:msg)", {"msg": "hello"}) s.commit()
2.2 Secrets 管理
密码和 API Key 写死在代码里是给自己埋雷。Streamlit 的做法是把敏感信息放到 .streamlit/secrets.toml 里,运行时通过 st.secrets 字典读取。更省事的是,st.connection 会自动查找 [connections.xxx] 下的配置并注入,你连手动传参都省了。
「文件位置:」
# 项目根目录下 .streamlit/secrets.toml
# .streamlit/secrets.toml[connections.mysql]url = "mysql://root:123456@localhost:3306/pets"[api_keys]openai = "sk-xxxxxxxx"
代码里两种读取方式:手动取和自动注入。前者适合临时用一下,后者配合 st.connection 最省事。
import streamlit as st# 读取连接配置(嵌套结构)mysql_url = st.secrets["connections"]["mysql"]["url"]# 读取简单键值openai_key = st.secrets["api_keys"]["openai"]# 也可以用点号访问(st.secrets 本质是 TOML 的字典映射)mysql_url = st.secrets.connections.mysql.urlopenai_key = st.secrets.api_keys.openai# ============================================================# 方式二:st.connection() 自动从 secrets 读取# ============================================================# st.connection 会自动去 secrets.toml 里找 [connections.mysql]# 无需手动传 url,框架替你读取并注入conn = st.connection("mysql", type="sql")# 查询示例df = conn.query("SELECT * FROM mytable LIMIT 10")
两种方式各有适用场景:手动读取适合需要临时使用配置值的场合,自动注入适合标准化连接管理,代码更简洁。
2.3 自定义连接
内置的 sql 连接能搞定大多数关系型数据库,但 Redis、MongoDB 这类非关系型数据源就得自己动手了。做法不复杂:继承 BaseConnection,实现 _connect() 方法,框架就会自动帮你处理缓存和 secrets 注入。
「步骤一:」 在 secrets.toml 里配好 Redis 的连接信息。_connect() 方法里的 self._secrets 就是这个配置块的字典,直接解包传进去就行。
# .streamlit/secrets.toml[connections.redis]host = "localhost"port = 6379protocol = 2
# redis_connection.pyimport streamlit as stfrom streamlit.connections import BaseConnectionimport redisimport jsonclassRedisConnection(BaseConnection):"""Streamlit Redis 连接封装"""def_connect(self, **kwargs):return redis.Redis(**self._secrets, **kwargs)# ---- 字符串操作 ----defget(self, key: str) -> str | None: val = self._instance.get(key)return val.decode() if val elseNonedefset(self, key: str, value: str, ex: int = None) -> bool:return self._instance.set(key, value, ex=ex)defdelete(self, *keys: str) -> int:return self._instance.delete(*keys)defexists(self, key: str) -> bool:return bool(self._instance.exists(key))defexpire(self, key: str, seconds: int) -> bool:return self._instance.expire(key, seconds)defttl(self, key: str) -> int:return self._instance.ttl(key)defkeys(self, pattern: str = "*") -> list:return [k.decode() for k in self._instance.keys(pattern)]# ---- 计数器 ----defincr(self, key: str, amount: int = 1) -> int:return self._instance.incr(key, amount)defdecr(self, key: str, amount: int = 1) -> int:return self._instance.decr(key, amount)# ---- JSON 序列化 ----defset_json(self, key: str, data: dict, ex: int = None) -> bool:return self._instance.set(key, json.dumps(data), ex=ex)defget_json(self, key: str) -> dict | None: val = self._instance.get(key)return json.loads(val) if val elseNone# ---- 列表操作 ----deflpush(self, key: str, *values) -> int:return self._instance.lpush(key, *values)deflrange(self, key: str, start: int = 0, end: int = -1) -> list:return [v.decode() for v in self._instance.lrange(key, start, end)]defllen(self, key: str) -> int:return self._instance.llen(key)# ---- 哈希操作 ----defhset(self, name: str, key: str, value: str) -> int:return self._instance.hset(name, key, value)defhget(self, name: str, key: str) -> str | None: val = self._instance.hget(name, key)return val.decode() if val elseNonedefhgetall(self, name: str) -> dict:return {k.decode(): v.decode() for k, v in self._instance.hgetall(name).items()}
「步骤二:」 导入自定义连接,拿来就用。下面是一个完整的 Redis 可视化管理界面示例 —— 侧边栏搜 key 和新增,主区域用表格展示所有 key 的类型、值预览、大小和 TTL,选中后可以编辑、删除、改 TTL、重命名。
调用示例:
import streamlit as stfrom redis_connection import RedisConnectionst.set_page_config(page_title="Redis 管理工具", page_icon="🔴", layout="wide")conn = st.connection("redis", type=RedisConnection, ttl=0)defvalue_preview(key, key_type):"""返回值的简短预览"""if key_type == "string": v = conn.get(key) or""return v[:50] + "..."if len(v) > 50else velif key_type == "hash":returnf"{{...}} {conn._instance.hlen(key)} fields"elif key_type == "list":returnf"[...] {conn._instance.llen(key)} items"return"-"defkey_size(key, key_type):"""获取 key 大小"""if key_type == "string":return conn._instance.strlen(key)elif key_type == "hash":return conn._instance.hlen(key)elif key_type == "list":return conn._instance.llen(key)return0defttl_display(key): t = conn.ttl(key)if t == -1:return"永不过期"elif t == -2:return"已过期"returnf"{t}s"# ---- 主区域 ----keys = st.session_state.get("keys", conn.keys("*"))# 构建表格数据rows = []for k in sorted(keys)[:200]: # 限制 200 条防止性能问题 kt = conn.type(k) rows.append({"Key": k,"类型": kt.upper(),"值预览": value_preview(k, kt),"大小": key_size(k, kt),"TTL": ttl_display(k), })# ---- 表格 ----edited = st.data_editor( rows, use_container_width=True, hide_index=True, column_config={"Key": st.column_config.TextColumn("🔑 Key", width="medium"),"类型": st.column_config.TextColumn("📦 类型", width="small"),"值预览": st.column_config.TextColumn("💬 值预览", width="large"),"大小": st.column_config.NumberColumn("📏 大小", width="small"),"TTL": st.column_config.TextColumn("⏳ TTL", width="small"), }, disabled=["Key", "类型", "值预览", "大小", "TTL"], key="data_editor",)
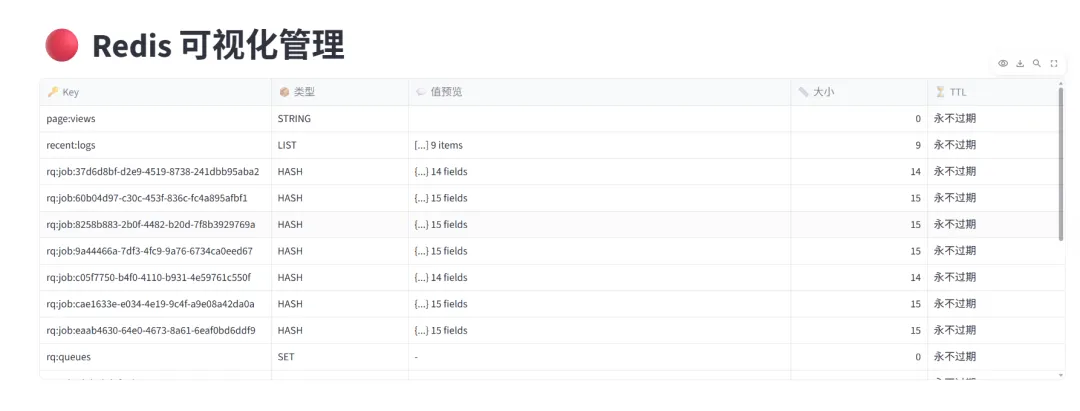
几个要点:st.data_editor 做表格浏览,侧边栏搜 key 加新增,操作栏集中了编辑、删除、TTL 和重命名。
三、文件操作
Streamlit 内置了文件上传、下载和常见媒体格式的展示组件,覆盖了日常数据应用里的大多数文件处理场景。
3.1 st.file_uploader:文件上传
st.file_uploader 是 Streamlit 最常用的文件输入组件,支持拖拽或点击上传,可限制文件类型和数量。上传后返回 UploadedFile 对象,可直接读取为 bytes 或传递给 Pandas、PIL 等库处理。
import streamlit as stimport pandas as pd# 单文件上传uploaded = st.file_uploader("选择文件", type=["csv", "xlsx", "png", "jpg"])if uploaded isnotNone:# 读取为 DataFrameif uploaded.name.endswith(".csv"): df = pd.read_csv(uploaded) st.dataframe(df)elif uploaded.name.endswith((".xlsx", ".xls")): df = pd.read_excel(uploaded) st.dataframe(df)else:# 图片直接展示 st.image(uploaded)# 多文件上传files = st.file_uploader("批量上传", type=["csv"], accept_multiple_files=True)for f in files or []: df = pd.read_csv(f) st.write(f"**{f.name}** — {len(df)} 行")
效果:
3.3 st.image:图片展示
st.image 支持从文件路径、PIL Image 对象、bytes 或 URL 加载图片,可调节尺寸和添加标题。
import streamlit as stfrom PIL import Image# 方式一:本地文件image = Image.open("sunrise.jpg")st.image(image, caption="山间日出", width=400)# 方式二:URLst.image("https://streamlit.io/images/brand/streamlit-logo.png", width=200)# 方式三:上传后直接展示(已在上传章节演示)
3.4 st.audio:音频播放
支持播放本地音频文件和通过代码生成的音频数据。传入 bytes 对象时需指定 format,传入 NumPy 数组时需指定 sample_rate。
import streamlit as stimport numpy as np# 播放音频文件with open("music.mp3", "rb") as f: st.audio(f.read(), format="audio/mp3")# 播放生成的音频(440Hz 正弦波,持续 2 秒)sample_rate = 44100t = np.linspace(0, 2, 2 * sample_rate, False)wave = np.sin(440 * t * 2 * np.pi)st.audio(wave, sample_rate=sample_rate)
3.5 st.video:视频播放
支持本地视频文件和在线视频 URL(如 YouTube)。本地视频需以 bytes 传入。
import streamlit as st# 播放本地视频with open("demo.mp4", "rb") as f: st.video(f.read())# 播放在线视频 URLst.video("https://www.youtube.com/watch?v=your_video_id")
3.6 PDF 文档展示
Streamlit 没有内置 PDF 查看器,但可以通过以下方式实现:
import streamlit as st# 方式一:提供下载链接with open("report.pdf", "rb") as f: st.download_button("📄 下载 PDF", f, "report.pdf", "application/pdf")# 方式二:用 iframe 嵌入在线 PDFst.markdown('<iframe src="https://example.com/report.pdf" ''width="100%" height="600"></iframe>', unsafe_allow_html=True)# 方式三:用 PyPDF2 读取文本内容展示from PyPDF2 import PdfReaderuploaded = st.file_uploader("上传 PDF", type="pdf")if uploaded: reader = PdfReader(uploaded)for i, page in enumerate(reader.pages): st.text(f"第 {i+1} 页:\n{page.extract_text()[:500]}")
3.7 Excel / CSV 读写
与 Pandas 结合,Streamlit 可以轻松实现表格数据的导入导出与分析。
import streamlit as stimport pandas as pdfrom io import BytesIO# ---- 导入 ----uploaded = st.file_uploader("上传表格", type=["csv", "xlsx", "xls"])if uploaded: df = pd.read_csv(uploaded) if uploaded.name.endswith("csv") else pd.read_excel(uploaded) st.dataframe(df)# ---- 导出 ----@st.cache_datadefto_excel(df): buf = BytesIO()with pd.ExcelWriter(buf, engine="openpyxl") as w: df.to_excel(w, index=False, sheet_name="Sheet1")return buf.getvalue()df_sample = pd.DataFrame({"Name": ["Alice", "Bob"], "Score": [90, 85]})st.download_button("📥 导出 Excel", to_excel(df_sample), "output.xlsx")
3.8 远程 URL 文件获取
结合 requests 或 urllib,可以从远程 URL 下载文件并直接在 Streamlit 中展示或处理。
import streamlit as stimport requestsfrom PIL import Imageurl = st.text_input("输入图片 URL")if url:try: resp = requests.get(url, stream=True) resp.raise_for_status()# 根据 Content-Type 判断处理方式 content_type = resp.headers.get("Content-Type", "")if"image"in content_type: st.image(resp.content)elif"csv"in content_type:import pandas as pdfrom io import StringIO df = pd.read_csv(StringIO(resp.text)) st.dataframe(df)else: st.write(f"文件大小: {len(resp.content) / 1024:.1f} KB")except Exception as e: st.error(f"获取失败: {e}")
3.9 文件操作速查表
| | |
|---|
st.file_uploader | | type |
st.download_button | | data |
st.image | | caption, width, use_container_width |
st.audio | | format, sample_rate, start_time |
st.video | | format |
PdfReader | | pages |
pd.read_csv/Excel | | sheet_name |
结语
这篇文章把 Streamlit 最常用的三块内容串了一遍:多页面怎么组织、数据库怎么连、文件怎么处理。多页面部分对比了手动路由和内置方案各自适合什么场景,数据库部分从 st.connection 讲到 secrets 管理再到自定义连接类,文件部分涵盖了图片、音视频、PDF、表格和远程 URL 的全流程。
这些东西掌握了,用纯 Python 搭一个像样的数据应用基本没啥问题了。剩下的就是动手写,踩几个坑就熟了。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
