我用 Python 写了一个网页转 Markdown 工具:终于不用再手动复制排版了
- 2026-06-29 15:31:43
灵感来源
复制一篇网页文章,最痛苦的不是复制本身。
是复制完以后,标题乱了、图片丢了、代码块散了,最后你花了半小时,只是在和格式较劲。
作为一个经常写技术文章的人,我一直有个很具体的痛点:
我想把网页内容干净地保存成 Markdown,而且图片也要能离线访问。
听起来很简单,对吧?
直到你真的开始做,才会发现网页世界并不温柔:
• 有的页面正文藏在一堆广告、导航、推荐流里 • 有的图片只放在 data-src里,复制出来就是空的• 有的网站是 SPA,直接请求只返回一个空壳 • 有的网站有 Cloudflare,普通爬虫一上来就被挡 • 有的平台还有自定义标签,Markdown 工具根本不认识
于是,我写了一个小工具:HtmlToMD。
简单的界面
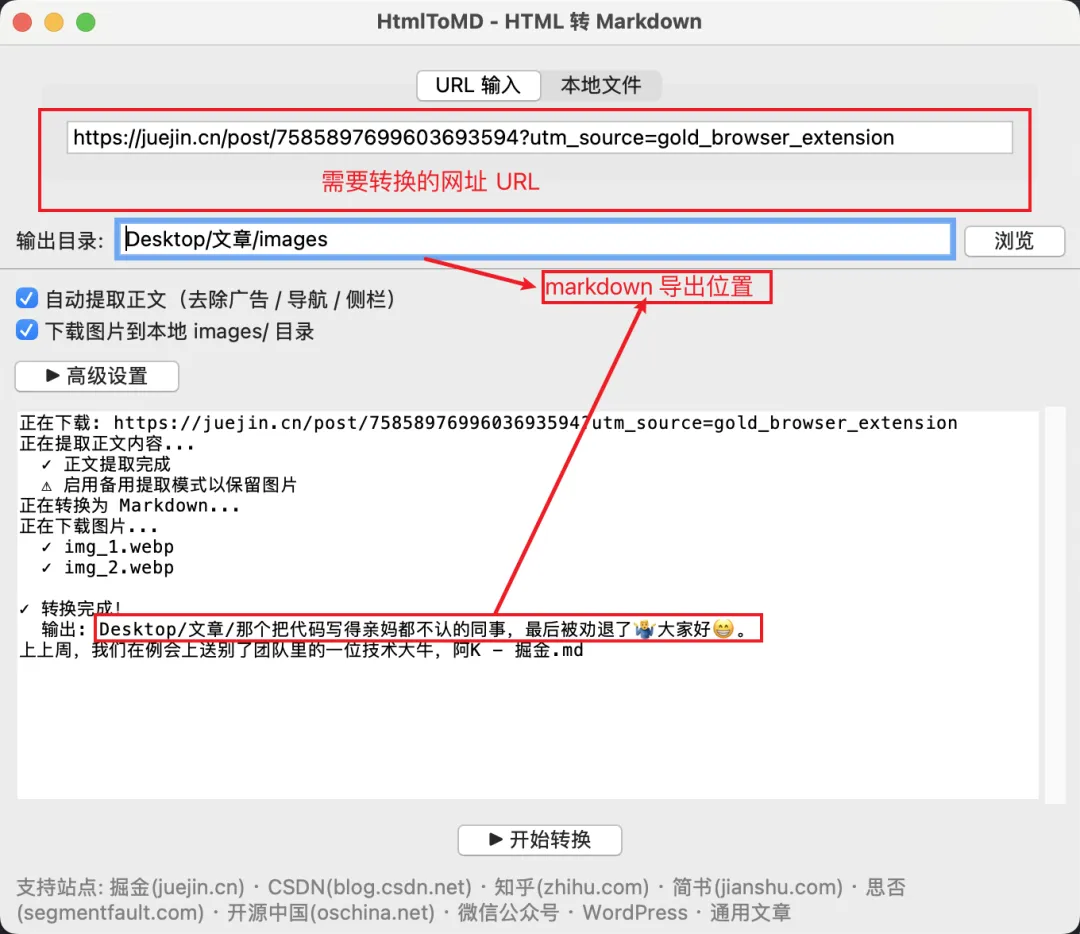
项目地址:https://github.com/zhugyGit/HtmlToMD-dic
它做的事情可以概括成一句话:
输入 URL 或 HTML 文件,自动提取正文,转换成干净的 Markdown,并把图片下载到本地。
一、为什么我要自己写一个?
市面上当然有类似工具,比如浏览器插件、剪藏工具、网页转 Markdown 扩展。
但我真正使用下来,发现它们经常卡在三个地方。
1. 正文不够干净
很多工具会把导航栏、侧边栏、广告、相关阅读一起带进来。
结果看似“转换成功”,打开 Markdown 以后却像一锅大杂烩,还得手动删半天。
2. 图片依赖远程链接
Markdown 里保留的是远程图片地址。
当原站限制防盗链、图片过期、文章被删除,文档里的图也就没了。
对技术写作来说,这很致命。
3. 反爬和 SPA 越来越普遍
以前请求一个网页,HTML 里基本就有正文。
现在很多站点首屏只返回一个 #app 或 #root,内容靠前端脚本渲染。再加上 Cloudflare、登录态、Cookie,简单 requests.get() 已经不够用了。
所以 HtmlToMD 的目标不是做一个“万能爬虫”。
它更像是一个面向技术写作者的内容整理工具:
尽可能自动化,但失败时也要给用户一个清楚的处理路径。
二、这个工具到底怎么工作?
HtmlToMD 的主流程很朴素:
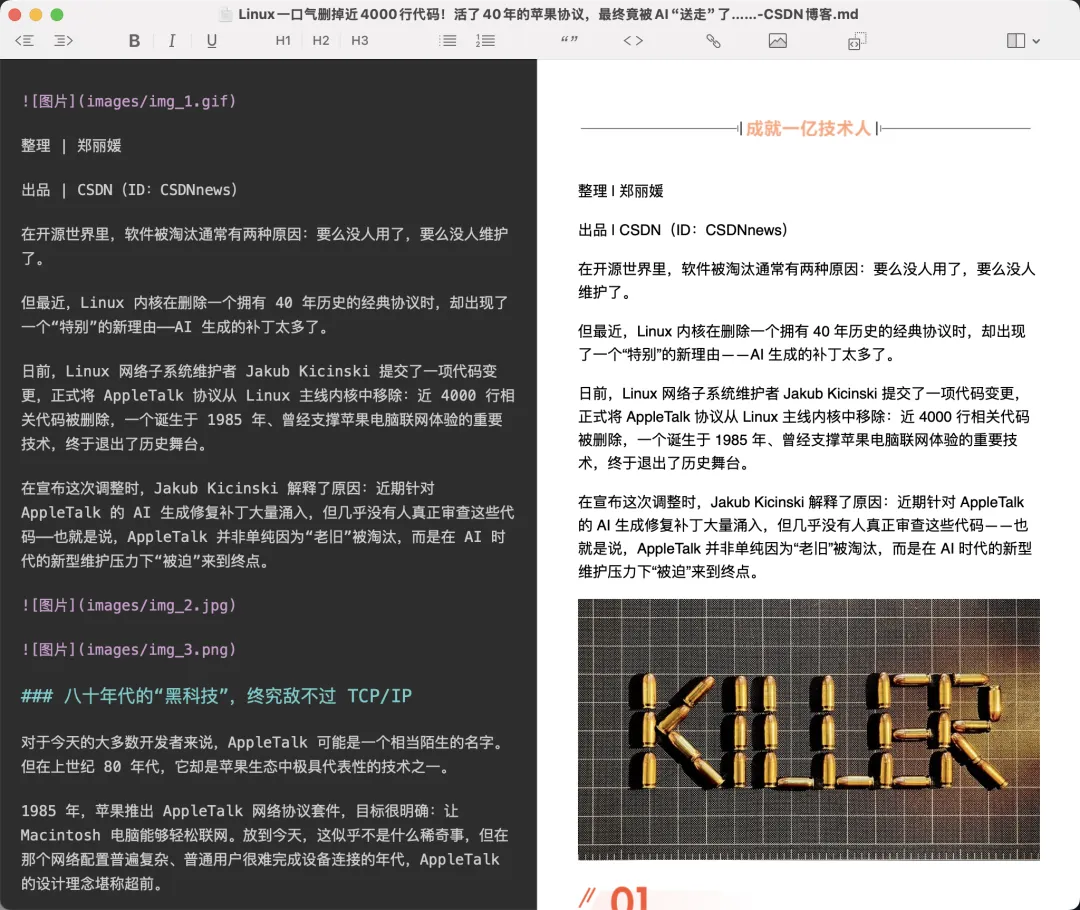
输入 URL / HTML 文件 ↓请求或读取页面 ↓提取正文 ↓清洗懒加载图片和特殊标签 ↓HTML 转 Markdown ↓下载图片到本地 ↓输出 .md 文件最终得到的是这样的结果:
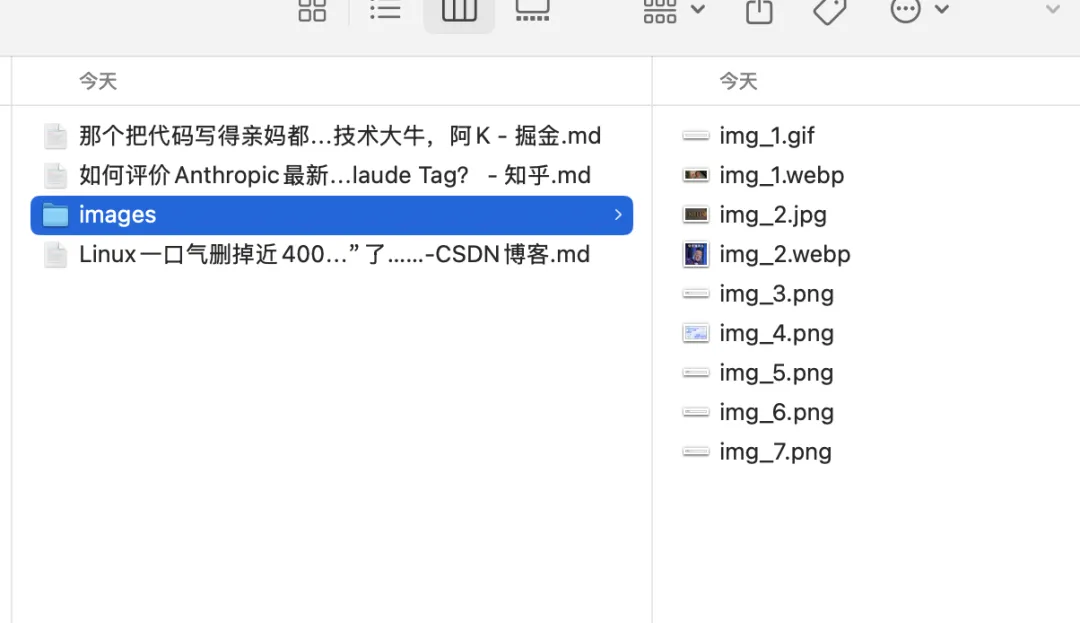
article.mdimages/ img_1.png img_2.jpg img_3.webpMarkdown 里的图片链接会被替换成本地路径。
也就是说,文章和图片是一起落盘的。即使原网页下线,这份 Markdown 依然可以独立保存和迁移。
三、技术选型:少即是多
这个项目没有使用很重的框架。
我的原则是:能用稳定小工具解决,就不要把项目变复杂。
这套组合的好处是维护成本低。
项目规模不大,但每个库都只负责自己擅长的那部分。
四、最关键的设计:双引擎正文提取
网页正文提取是整个项目最核心的部分。
如果正文提错了,后面的 Markdown 转换和图片下载都没有意义。
一开始我只用了 trafilatura。
它对大多数文章页面效果很好,但也有一个问题:有些站点提取出的正文很干净,却把图片全部丢了。
这对技术文章尤其麻烦。因为很多内容不是文字能完全表达的,截图、流程图、代码运行结果都很重要。
所以我设计了一个双引擎策略:
# 主引擎:trafilaturaclean_html = trafilatura.extract(html, output_format="html")# 如果原文有图片,但提取结果没有图片,就启用备用引擎if orig_imgs > 0 and clean_imgs == 0: clean_html = _extract_article_html(html)备用引擎的思路很直接:
为常见技术平台维护一组正文 CSS 选择器。
_ARTICLE_SELECTORS = [ "#article-root .article-viewer", # 掘金 "#js_content", # 微信公众号 "#article_content", # CSDN ".article-detail", # OSChina ".RichContent-inner", # 知乎 "article", # 通用兜底]这里有一个很重要的小细节:
选择器的顺序就是优先级。
先匹配站点特定结构,再走通用 article 兜底。这样既能照顾主流中文技术社区,又不会把逻辑写死在某一个平台上。
五、反爬不是硬刚,而是分层降级
很多人一听到“反爬”,第一反应就是上更复杂的工具。
但这个项目的定位不是批量采集,而是帮用户整理自己需要引用和保存的内容。
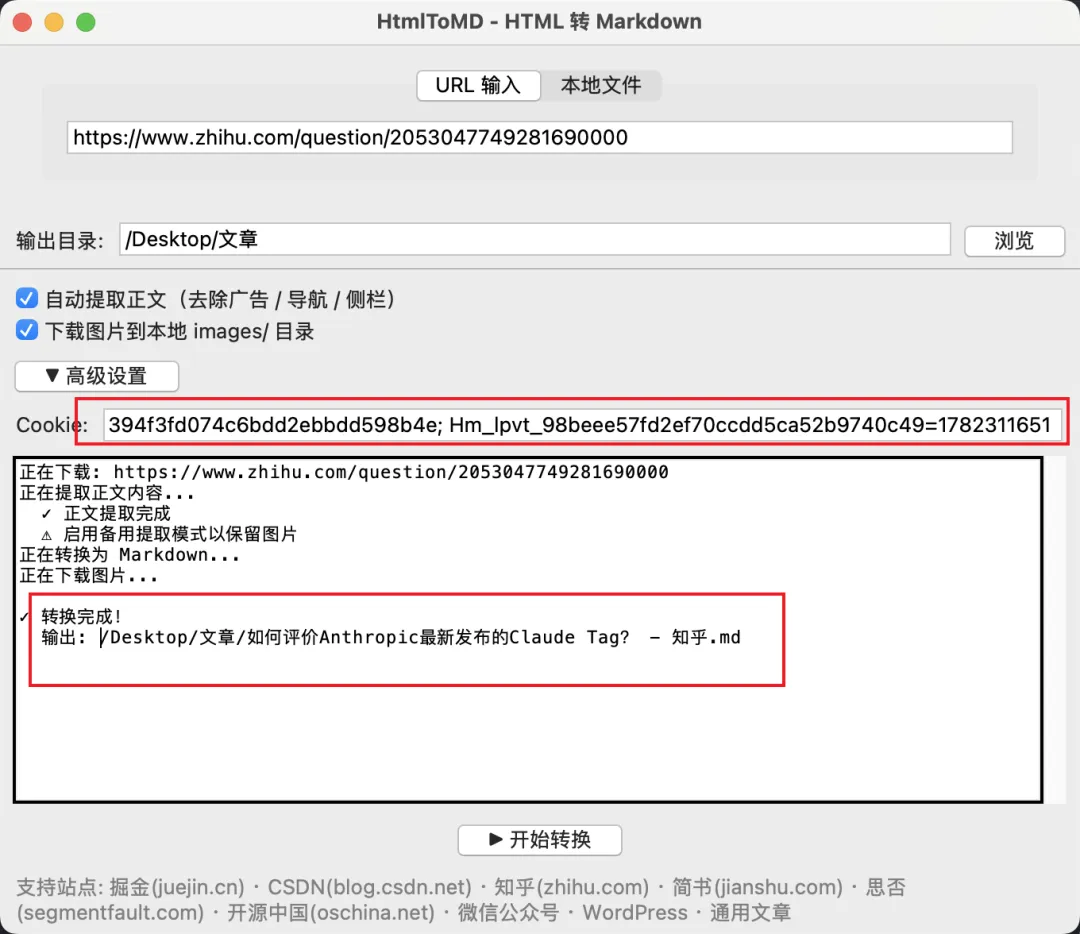
所以我的策略是:
先用最普通的方式请求,遇到问题再逐层升级。
第一层:模拟正常浏览器请求
默认使用较新的 Chrome User-Agent,并补充常见请求头:
headers = { "User-Agent": "... Chrome/120 ...", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",}这一步能覆盖很多普通站点。
第二层:识别 SPA 空壳页面
有些站点返回的 HTML 看起来请求成功了,但里面只有一个空容器:
<div id="app"></div>这种页面直接转换没有意义。
于是我加了一个简单的检测:
def _is_spa_shell(html: str) -> bool: if len(html) > 10000: return False if re.search(r'<div\s+id=["\']app["\'][^>]*>\s*</div>', html): return True if re.search(r'<div\s+id=["\']root["\'][^>]*>\s*</div>', html): return True return False检测到 SPA 空壳后,会尝试使用 Googlebot UA 重新请求。
一些站点会给搜索引擎返回服务端渲染版本,这时就能拿到完整正文。
第三层:Cloudflare 场景用 cloudscraper
如果遇到 403 或 503,再尝试 cloudscraper:
try: import cloudscraper scraper = cloudscraper.create_scraper() resp = scraper.get(url, timeout=30)except ImportError: pass这里我没有把 cloudscraper 做成强依赖。
原因很简单:它在某些平台上可能有兼容性问题。作为可选能力更稳妥,导入失败就回退到普通请求。
这也是我在这个项目里反复提醒自己的原则:
工具可以不万能,但不要因为一个增强能力不可用,就让整个流程崩掉。
六、图片处理:真正麻烦的地方在细节
图片下载看起来只是“找到链接,然后保存”。
但实际写起来,坑不少。
1. 懒加载图片不在 src 里
很多平台的图片并不直接写在 src,而是放在这些属性里:
_IMG_ATTRS = ( "data-original", "data-original-src", "data-src", "data-actualsrc",)所以在转换 Markdown 之前,需要先把这些懒加载地址统一还原成标准 src。
否则 Markdown 转换器根本看不到图片。
2. 防盗链需要 Referer
不少图片 CDN 会校验 Referer。
如果下载时不带来源页面地址,浏览器能打开,程序却下载失败。
所以下载图片时要把原文章 URL 带上:
headers = { "Referer": base_url, "User-Agent": browser_ua,}3. 扩展名不能只看 URL
有些图片 URL 没有 .jpg、.png 这种后缀,甚至是一串参数。
更可靠的方式是读取响应头里的 Content-Type,再决定保存成什么扩展名。
这一点会影响后续 Markdown 预览、图床迁移和静态站点生成。
七、微信公众号、知乎、掘金这些平台怎么适配?
不同平台的问题不一样。
我的做法不是为每个平台写一整套复杂逻辑,而是把差异拆成两类:
第一类:正文容器不同。
这部分交给 CSS 选择器列表解决。
比如:
第二类:图片和特殊标签不同。
这部分通过统一预处理解决。
比如微信公众号里的视频占位标签:
<mp-common-videosnap></mp-common-videosnap>它不是标准 HTML,直接丢给 markdownify 会产生奇怪内容。
所以需要在转换前用 BeautifulSoup 把它替换成更适合 Markdown 的文本或链接。
这个思路很适合做工具类项目:
不要一上来追求完美抽象,先把差异收敛到少数几个稳定入口。
八、桌面 GUI:别让界面卡死
HtmlToMD 用的是 Tkinter。
它的优点是简单、内置、跨平台。
但它有一个典型问题:主线程负责界面刷新,不能直接跑耗时任务。
网页请求、正文提取、图片下载都可能很慢。
如果直接在主线程执行,用户点击按钮后窗口就会卡住,看起来像程序崩了。
解决方式是 threading + queue:
def task(): try: html, base_url = self._fetch_url(url) convert(html, base_url, output_dir, self._log) except Exception as e: self._log(f"错误: {e}") finally: self._msg_queue.put("__DONE__")threading.Thread(target=task, daemon=True).start()后台线程负责干活。
主线程只做两件事:
• 定时从队列里取日志 • 更新界面状态
这样界面不会卡死,日志也能实时显示。
九、开发过程中最值得记录的 4 个坑
坑 1:正文很干净,图片全没了
这是 trafilatura 在部分页面上的取舍问题。
它追求正文纯净,但有时会把图片一起过滤掉。
我的解决方案是:
先统计原始 HTML 的图片数量,再统计提取结果的图片数量。
如果原文有图、结果没图,就自动切到 CSS 选择器备用引擎。
坑 2:SPA 页面请求成功,但没有正文
HTTP 状态码是 200,不代表内容真的拿到了。
很多页面返回的是前端应用空壳。
所以不能只看状态码,还要检查 HTML 结构。
坑 3:微信公众号特殊标签会污染 Markdown
微信文章里有一些非标准标签。
它们在浏览器里正常,但转换成 Markdown 时会变得很奇怪。
这类问题最适合在 HTML 预处理阶段解决,而不是等 Markdown 生成后再用字符串硬修。
坑 4:跨平台打包比写功能更磨人
PyInstaller 能把 Python 程序打成可执行文件,但 macOS 还要考虑 Apple Silicon 和 Intel 架构。
CI 里需要分别处理不同架构环境,尤其是依赖库里带原生扩展时,问题会更多。
这也提醒我:
桌面工具的难点不只在代码,还在交付。
十、这个项目给我的 3 个工程启发
写完 HtmlToMD,我最大的感受不是“爬虫多难”,而是工具类项目最考验边界感。
1. 不要把主路径做复杂
普通页面就走普通请求。
只有遇到 SPA、403、503、Cookie 场景时,才进入更复杂的分支。
这样用户遇到 80% 的普通场景时,工具会很快、很稳。
2. 每一层都要有 fallback
正文提取有 fallback。
图片下载失败要继续转换正文。
cloudscraper 不可用也不能影响基础功能。
好的工具不一定永远成功,但应该尽量优雅失败。
3. 面向真实用户,而不是面向理想网页
真实网页不会按照你的预期写 HTML。
它可能结构混乱、标签不规范、图片懒加载、内容异步渲染。
所以这类工具不能只在“干净样例”上跑通,而要在真实站点里反复测试。
十一、接下来还想做什么?
目前 HtmlToMD 已经能覆盖很多日常写作场景,但后续还有几个方向可以继续增强:
• 支持批量 URL 转换 • 增加 CLI 命令行模式 • 提供自定义 Markdown 输出模板 • 持续补充中文技术社区的选择器规则 • 优化失败提示,让用户更快知道该补 Cookie 还是该换 HTML 文件
这些功能不一定都复杂,但都能明显提升工具的实用性。
最后
HtmlToMD 不是一个宏大的项目。
它只是从一个很具体的痛点出发:
我不想再为了保存一篇技术文章,手动清理半小时格式。
但也正是这种小痛点,最容易长出真正有用的工具。
如果你也经常写技术文章、整理资料、搭建个人知识库,应该很能理解这种需求:
内容已经够难写了,格式就别再折磨人了。
项目已开源,欢迎试用、提 Issue 或一起完善站点适配:
https://github.com/zhugyGit/HtmlToMD-dis
如果你也有“现有工具不好用,不如自己写一个”的经历,欢迎在评论区聊聊。
需要工具的私信发送 HtmlToMD

