1. 全景介绍
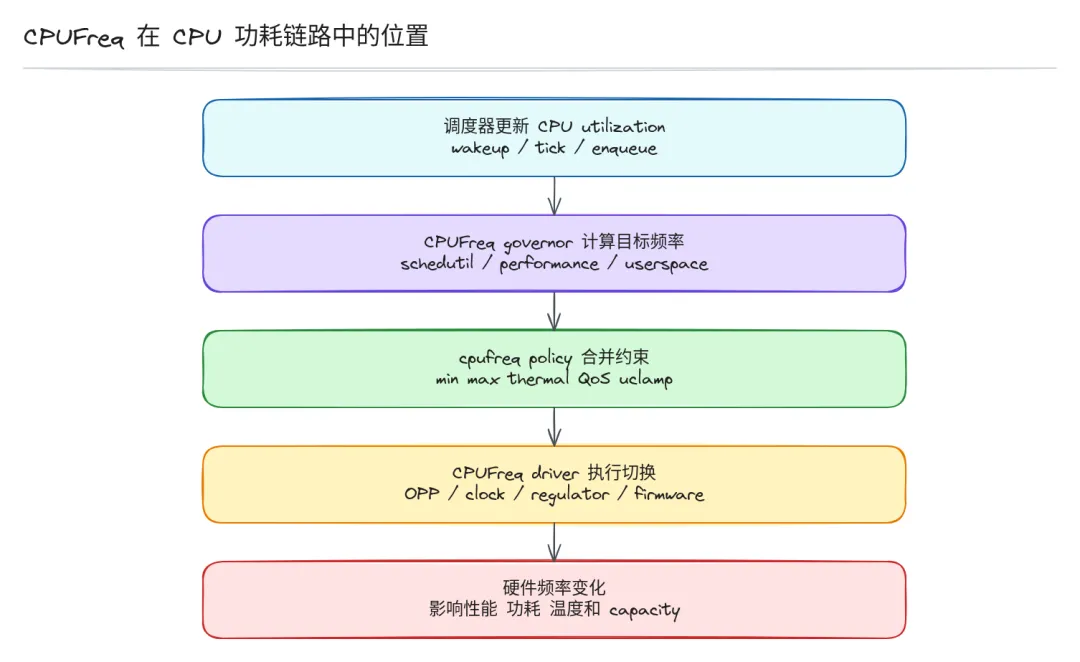
CPU 忙的时候要跑多快,闲的时候要睡多深,这是两个不同问题。CPUFreq 解决的是忙的时候跑多快:当任务堆满 runqueue,CPU 应该以什么频率运行,才能平衡性能和功耗。
它不是一个单纯的"降频开关",也不能解决所有功耗问题。空闲能不能深睡,那是 CPUIdle 的事;设备能不能挂起,那是 Runtime PM 的事;温度太高要不要压性能,那是 thermal 的事。CPU 已经忙起来了,在各种约束下选一个最合适的频率,这才是 CPUFreq 真正要做的。
如果你仔细读 Linux 源码会发现:CPUFreq 更像一个频率请求的约束合并框架,不是一个简单的频率切换驱动。调度器告诉你现在负载有多大,用户告诉你性能模式,thermal 告诉你温度限制,PM QoS 告诉你 latency 要求,最后这些输入都要合并成一个最终频率,才能送到硬件执行。
我们常说的 scaling_cur_freq,只是结果的一个读数,不是整个故事。这篇文章我们从问题本质出发,把框架分层和职责边界说清楚。
2. 实际情况
工程上遇到频率不对,很多人第一反应就是"CPUFreq driver 错了"。但实际情况是:大部分问题出在约束层,不是执行层。
- • 频率上不去:不一定是 governor 策略太保守。更可能是温度触发了 thermal 限制,把最高频率压下来了;或者用户自己在 sysfs 把
scaling_max_freq 限死了;也可能是硬件支持的 OPP 表里本来就没有你想要的那个频点;甚至 firmware 可能在 Linux 看不到的地方又做了一层裁剪。 - • 频率降不下来:不一定是 driver 没干活。更可能是某个任务或进程通过
uclamp_min 要求保性能;或者任务频繁唤醒,让调度器计算的负载一直降不下来;也可能你切了性能模式,直接把 policy 固定在最高频了。 - • 频率抖动太大:不一定是 CPUFreq 算法不好。schedutil governor 直接用调度器的负载信号,任务迁移、中断集中、IO 等待 boost 都会让负载变化变快,自然频率跟着变。
所以定位频率问题,先看边界,再看 driver。哪些 CPU 共享同一个频率域?当前允许的最小/最大频率是多少?用的哪个 governor?thermal 有没有介入?先把这些边界确认清楚,再往下挖才有用。
3. 核心对象
理解 CPUFreq,要从几个核心数据结构入手:
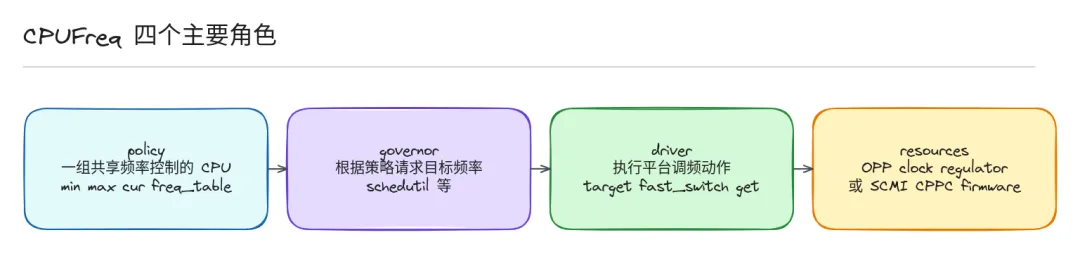
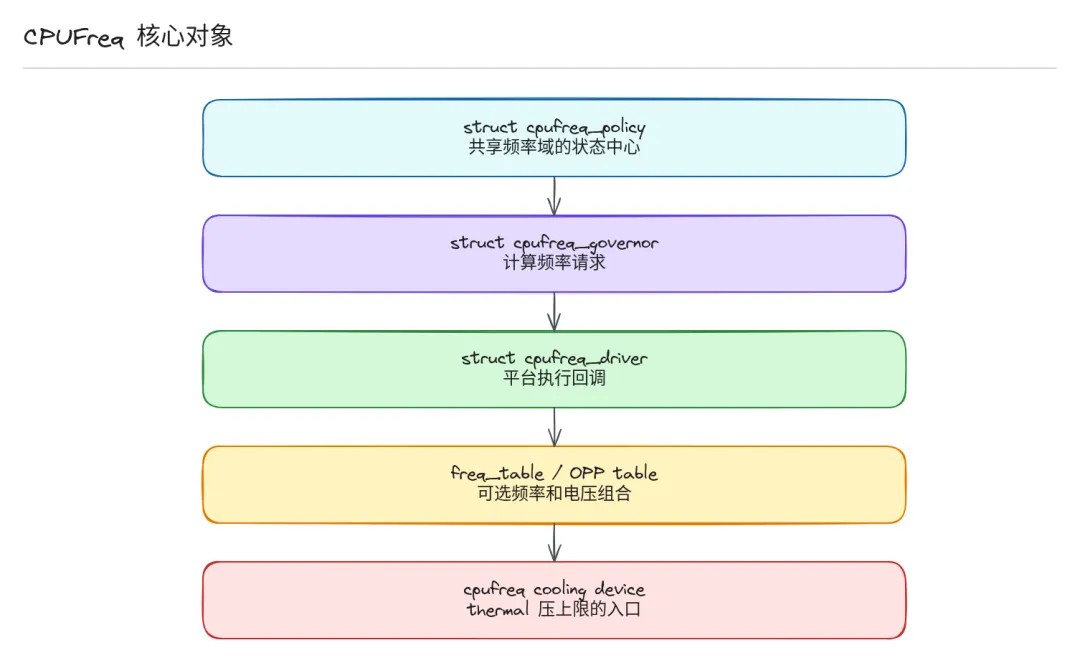
struct cpufreq_policy — 频率共享域
这是 CPUFreq 最核心的对象。它代表一组共享同一个频率控制的 CPU。很多 ARM SoC 设计中,同一个 cluster 里的多个 CPU 共享 PLL、电源轨和频率源,不能独立调频,所以 Linux 必须用 policy 把它们绑在一起。你在内核里看到的 policy0、policy4,通常就对应不同的 cluster 频率域。
policy 里记录了当前允许的最小频率、最大频率、使用的 governor、频率表、转换延迟等所有关键信息。
struct cpufreq_governor — 策略算法
governor 就是"决定频率的策略"。它根据负载信号算出一个目标频率:
- •
performance:永远跑最高频,性能优先 - •
schedutil:直接用调度器算出的负载,现代系统默认用这个
struct cpufreq_driver — 硬件执行层
driver 负责把最终选好的频率送到硬件。不同平台路径不一样:
- • 很多 ARM64 平台把调频权交给固件,driver 只负责发请求
频率表与其他
- •
freq_table / OPP table:列出硬件支持的所有可用频率,CPUFreq 不能凭空变出频率 - •
cpufreq_cooling_device:给 thermal 框架用的桥,让 thermal 可以通过压低频率上限来降温
4. 整体模型
CPUFreq 的工作流可以拆成四层,每层职责非常清晰:
- • 其他 governor 通过采样或者固定策略得到目标
- 策略层:governor 根据请求算出目标频率,policy 保存共享域的基本信息。
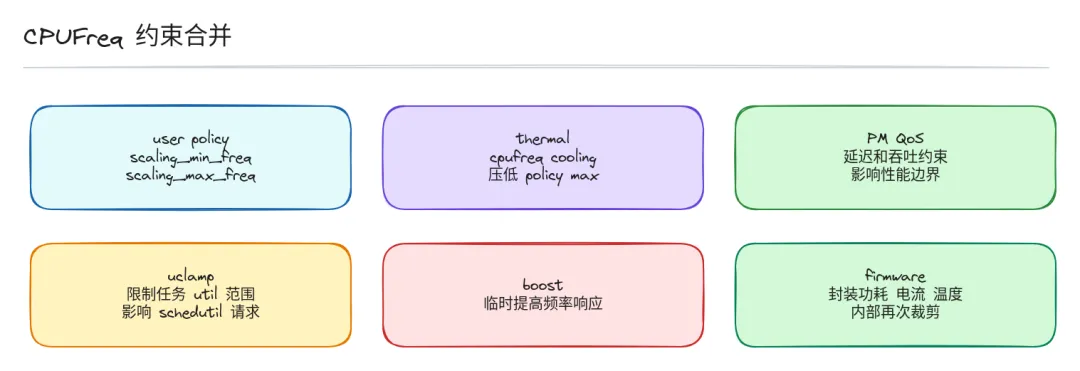
- 约束层:这是 CPUFreq 最容易被忽略的部分 — 目标频率不是直接给硬件,还要经过层层裁剪:所有这些约束合在一起,才能得到最终允许的频率。
- • driver 和 firmware 的安全边界
关键点:governor 算出来的频率,不是最终硬件上跑的频率。所有请求都要经过约束层聚合裁剪,最终结果是所有约束共同作用的产物。
5. 数据流
整个数据流其实很线性:
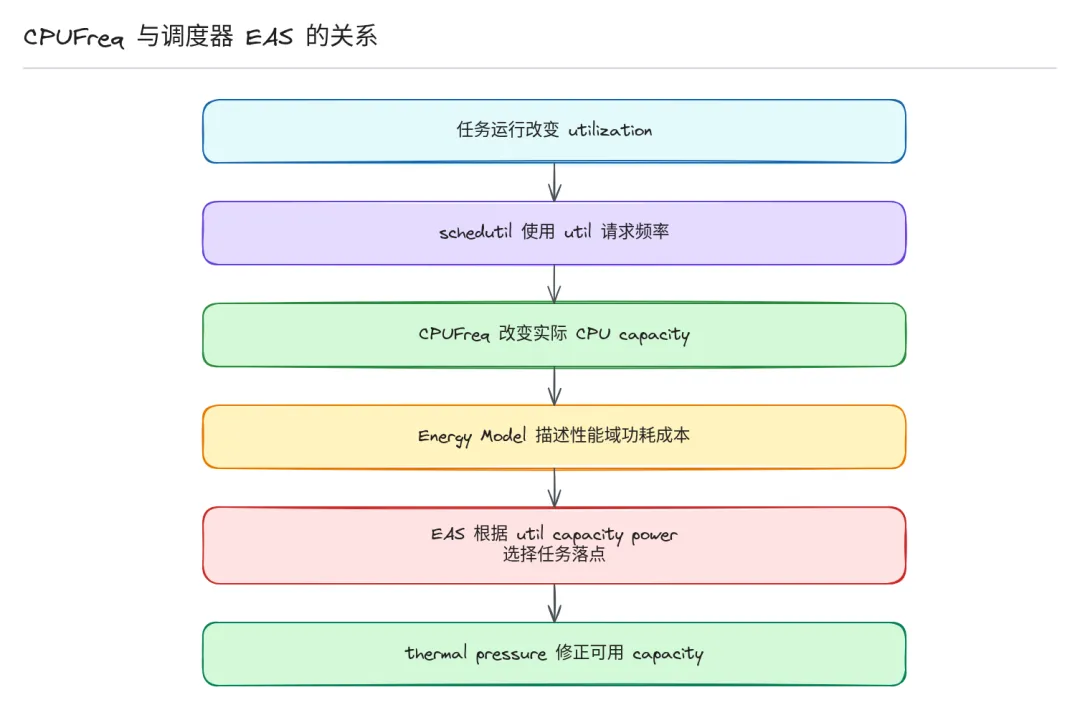
- 负载更新:调度器在任务入队、出队、tick、唤醒等路径更新当前 CPU 的负载估计。
- 频率请求:schedutil governor 读取负载、CPU 能力、I/O 等待、uclamp 等信息,算出一个目标频率。
- 边界更新:用户可以通过 sysfs 修改 governor、最小/最大频率、boost 开关,这些会直接更新 policy 边界。
- thermal 约束:温度高了以后,thermal 框架通过 cpufreq cooling device 压低 policy 的最高频率,不需要知道 CPUFreq 内部细节,改个上限就够了。核心合并:CPUFreq core 把所有约束和请求合在一起,根据频率表选出一个硬件支持的目标频点。
- 硬件执行:driver 把最终频率设置到硬件,更新统计状态。
如果你的平台把调频权完全交给固件(比如通过 SCMI/CPPC 接口),Linux 发出去的请求到了固件那里,可能还会再被裁剪一次。这种情况 Linux 只能看到最终结果,具体固件为什么改,就得看平台文档了。
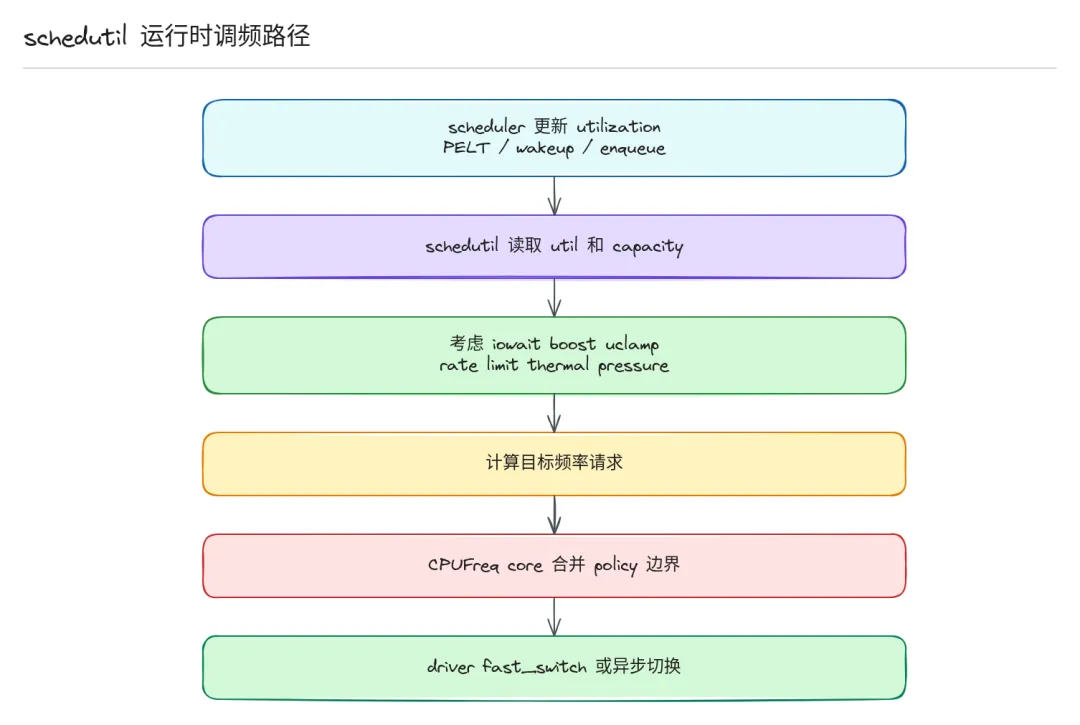
6. 运行时流程
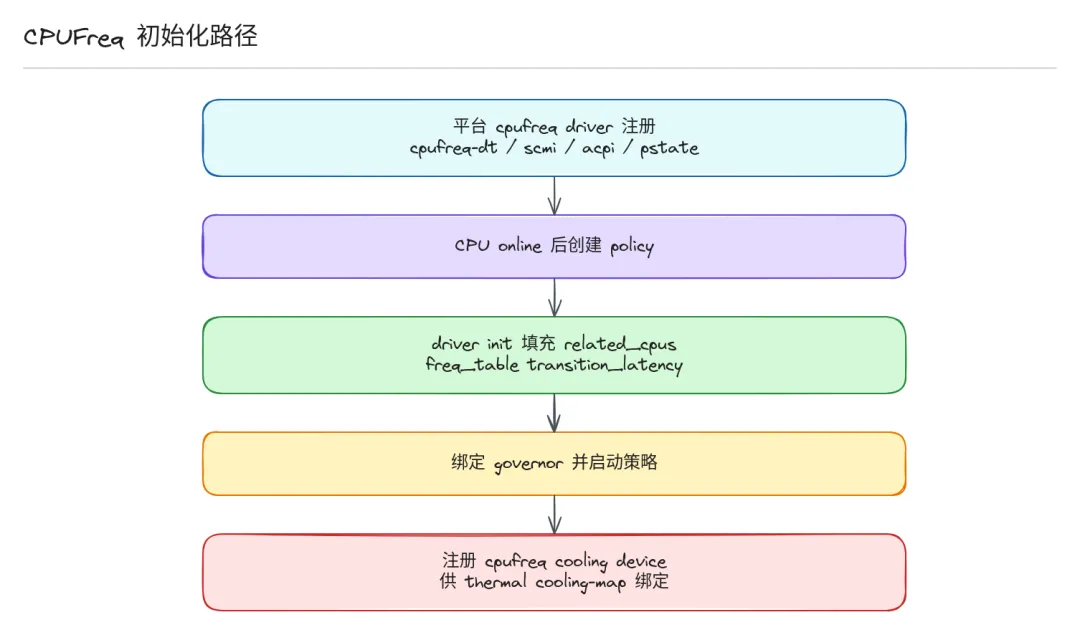
初始化顺序是这样的:
- 1. 平台 CPUFreq driver 先注册到内核 core
- 2. CPU 上线的时候,driver 初始化 policy,把哪些 CPU 共享、支持哪些频率、转换延迟这些信息填好
- 3. DT 平台一般在这里解析 CPU node,把 OPP table、clock、 regulator 这些资源绑好
- 4. policy 建好,才能启动 governor,开始根据负载请求频率
运行时:
- • schedutil 拿到负载,经过速率限制(避免太频繁切换),算出目标频率
- • 支持快速切换的平台走
fast_switch() 路径,延迟更低;不支持的走异步 workqueue - • driver 执行切换的时候,一般遵循"先升压再升频,降频后再降压"的顺序,避免电压不够导致不稳
- • 如果交给 firmware 处理,driver 只需要发请求,剩下的固件来做
异常情况也很常见:OPP 找不到、regulator 设置失败、clock 切换失败、firmware 拒绝请求、thermal 突然压上限...这些都会让最终频率和 governor 请求的不一样,这也是为什么一定要先看约束边界再定位问题。
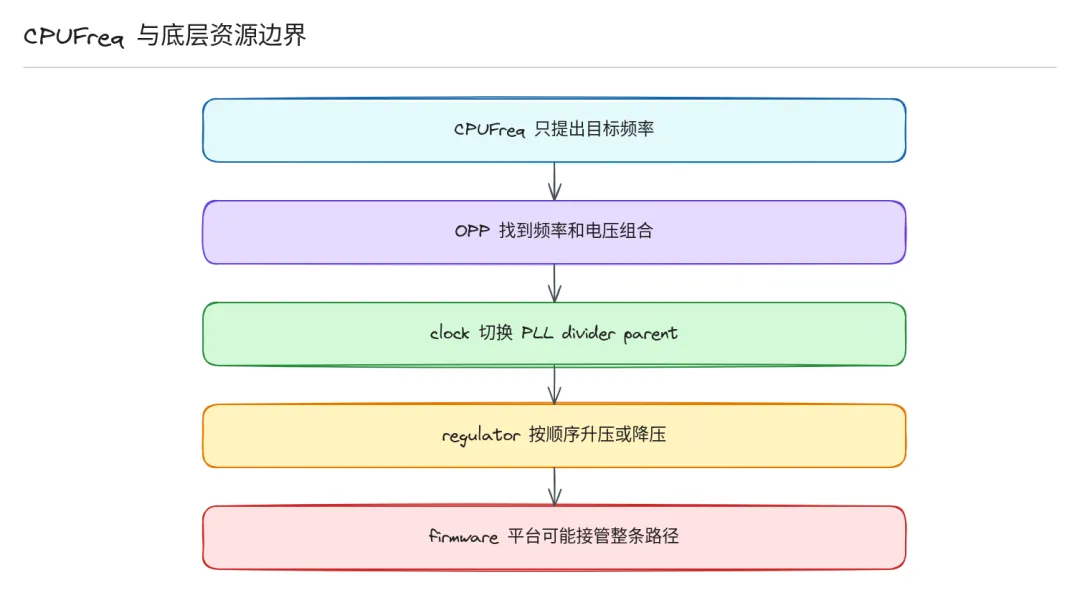
7. 案例:两种典型平台路径
我们用两个实际案例,把前面说的分层走一遍:
案例一:标准 ARM 平台 — schedutil + OPP + regulator
这是现在开源 Arm 平台最常见的路径:
- 1. 请求:schedutil 从调度器拿到当前负载,算出一个目标频率
- 2. 约束:thermal 已经把最高频率压到 1.5GHz,uclamp 要求最低不能低于 800MHz → 目标频率落在这个区间里
- 3. 执行:CPUFreq driver 通过 OPP 框架查到这个频率对应的电压 → 先让 regulator 把电压升到对应值 → 再让 clock 把频率切过去 → 完成。
整个链路每个模块只做自己的事,分工非常清楚:调度给负载,thermal 给温度约束,OPP 给频点电压,regulator 管电压,clock 管频率,CPUFreq core 只做聚合裁剪。
案例二:固件主导平台 — SCPI/SCMI 路径
很多 ARM64 手机/平板平台把频率和电压控制完全交给固件:
- 1. 前面约束聚合和上面一样,Linux CPUFreq core 算出最终允许的性能等级
- 2. driver 不直接碰 clock/regulator,把请求通过 SCPI/SCMI 协议发给固件
- 3. 固件拿到请求可能再做一轮裁剪(比如功耗预算不够)→ 最终频率由固件决定,Linux 只读回结果。
这种设计下,Linux CPUFreq 框架还是做约束聚合,只是把最后执行权交给了平台固件。
8. 总结
理解 CPUFreq,记住三条线就够了:
- 1. 先看 policy 边界:哪些 CPU 共享频率?当前允许的最小/最大频率是多少?支持哪些频点?
- 2. 再看请求怎么来:governor 为什么选这个频率?负载是多少?有没有 uclamp 约束?
- 3. 最后看执行路径:是 Linux 直接操作 OPP/clock/regulator,还是交给固件再裁一轮?
CPUFreq 本质就是个多层约束合并框架,不是一个简单的频率切换驱动。任何频率异常,先从上到下过一遍边界,大部分问题其实都出在约束被修改,不是执行层 driver 坏了。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
