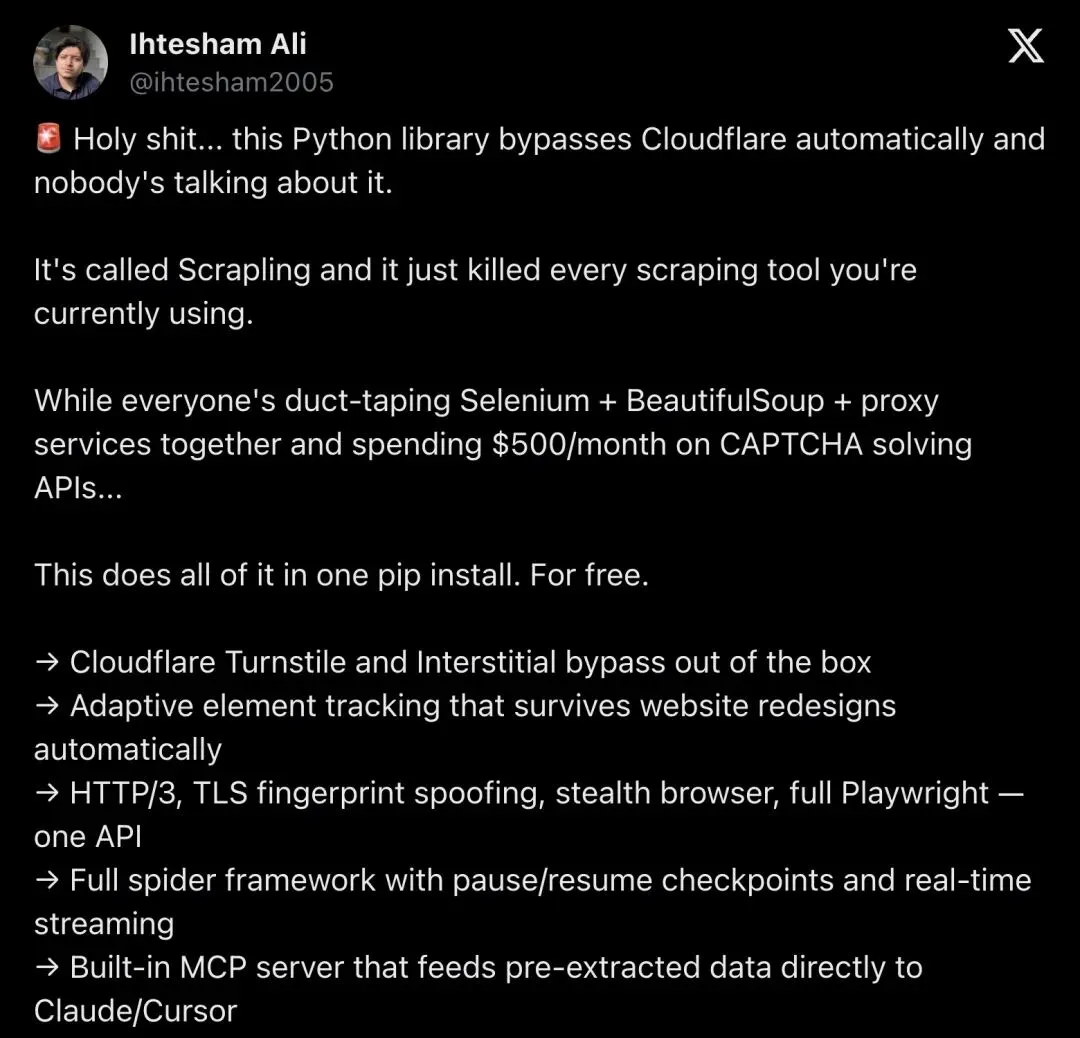
今年 3 月,一条英文推文直接炸开了开发者圈子:
"Holy shit… this Python library bypasses Cloudflare automatically and nobody's talking about it."
"这个 Python 库能自动绕过 Cloudflare,居然没人讨论它。"
3300 多个点赞,30 多万次浏览。推文里列了一串惊人的卖点——比 BeautifulSoup 快 784 倍、开箱绕过 Cloudflare Turnstile、让价值 2 亿美元的验证码行业变得无关紧要。
▲ @ihtesham2005 的推文获得 3300+ 点赞,将 Scrapling 推上风口
这个被推上风口浪尖的项目叫Scrapling。一个开源 Python 爬虫框架,GitHub star 已经飙到 6.5 万。
784 倍速度?自动绕过 Cloudflare?干掉验证码行业?——每一条都像是 AI 时代的城市传说。但打开它的仓库一看,事情比想象中复杂得多,也有意思得多。
65000 Star 的爬虫,凭什么?
先看基本面。
Scrapling 由开发者 Karim Shoair(GitHub @D4Vinci)打造,BSD-3-Clause 开源协议。从 2024 年起步到今天,6.5 万 star、6500 fork,增长曲线极其陡峭。
▲ Scrapling GitHub 仓库,65k+ stars,多国语言 README
它把自己定位为自适应网页抓取框架(adaptive web scraping framework),一行pip install scrapling就能装好。但和传统爬虫库相比,它多了三个关键模块:
第一,三档 Fetcher。纯 HTTP 模式走 curl_cffi,支持 TLS 指纹和 HTTP/3,速度最快;StealthyFetcher 套了一层 Playwright 隐身补丁,专门应对 Cloudflare 等反爬;DynamicFetcher 则是全浏览器渲染,能处理重 JS 页面。
第二,完整 Spider 框架。类似 Scrapy 的异步并发架构,支持暂停恢复、流式输出、JSON 导出。规模化抓取不用再拼凑工具链。
第三,也是最核心的——自适应解析器。这个放后面单独讲,因为这可能是 Scrapling 真正甩开竞争对手的东西。
784 倍速度,怎么来的?
先处理那个最抓眼球的数字。
官方基准测试跑的是 5000 个嵌套元素的合成页面解析,100+ 次取平均。结果:
| | |
|---|
| Scrapling | 2.02 ms | 1x |
| | |
| | |
| | |
| | |
| | |
| BS4 + lxml | 1584 ms | ~784x |
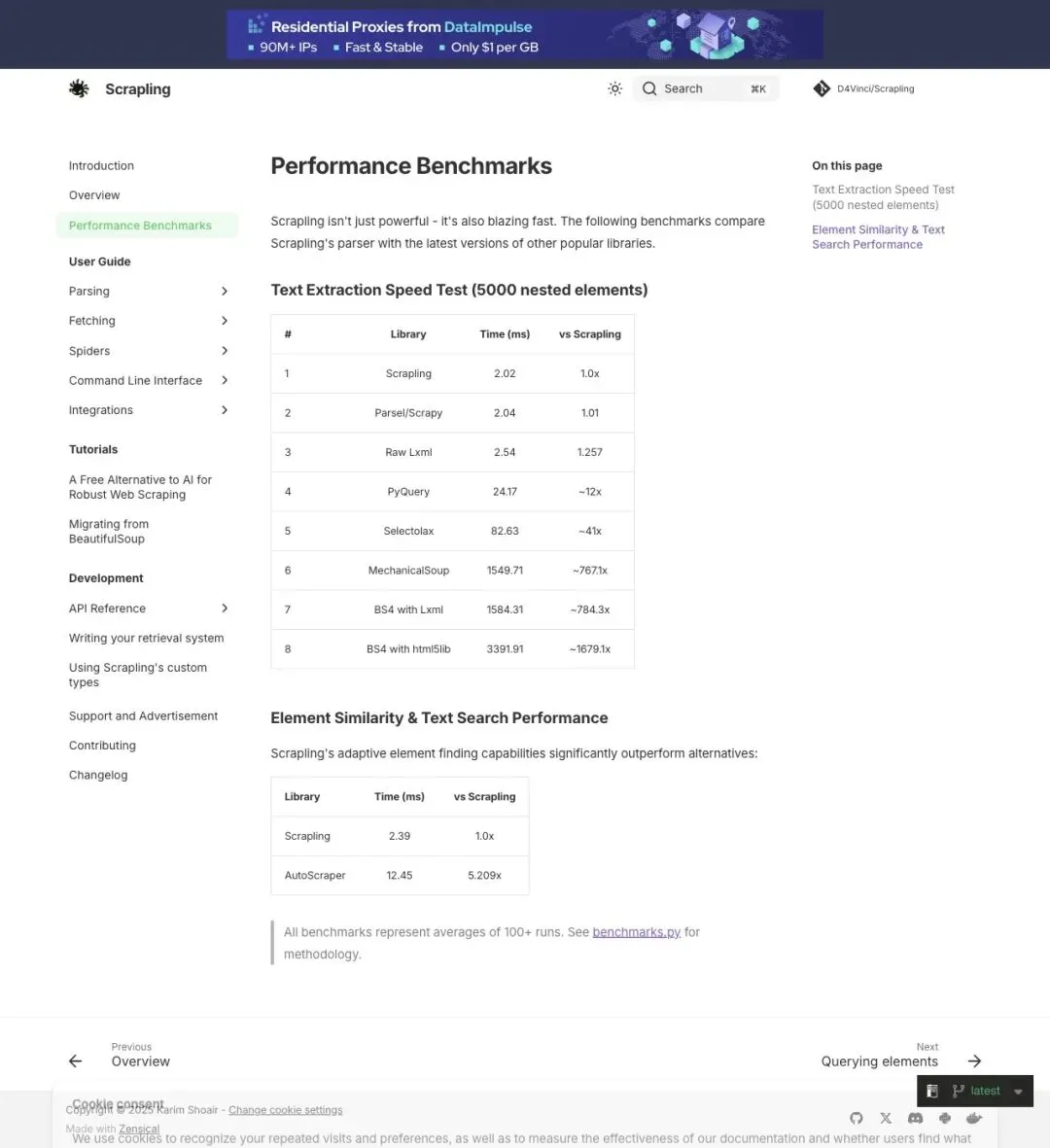
▲ 官方 benchmarks 页面,Scrapling 解析速度对比一目了然
784 倍的对比对象是 BeautifulSoup4——Python 爬虫圈最老牌也最慢的解析器。这个数字准确,但需要上下文:它测的是纯解析速度,不含网络请求和 JS 渲染。
也就是说,如果你的瓶颈在"请求网页等响应"上(大多数情况都是),784 倍不会让你的爬虫快 784 倍。但如果你要批量解析几十万个已经下载好的 HTML 文件,差距就是真实的——几小时变几十秒。
和 Parsel(Scrapy 的解析引擎)对比,Scrapling 几乎打平。所以严格说,速度优势主要体现在和老旧库的对比上。
老实讲,784 倍这个数字作为营销弹药确实够狠——但实际使用中,真正让人愿意切换过来的原因另有其他。
"绕过 Cloudflare"靠的是什么?
推文里最刺激的说法是"开箱绕过 Cloudflare Turnstile"。
翻开源码和文档,StealthyFetcher 的原理并不神秘:它在 Playwright 的基础上加了一层指纹伪装——TLS 指纹模拟真实浏览器、随机化 User-Agent 和 Canvas 特征、自动解决 Cloudflare 的 JavaScript 挑战页面。
代码用起来确实简单:
from scrapling.fetchers import StealthyFetcher page = StealthyFetcher.fetch( "https://protected-site.com", headless=True, solve_cloudflare=True ) headline = page.css_first("h1::text").get()
四行代码,过 Cloudflare。对个人开发者和小团队来说,这确实省掉了大量折腾。
但社区的反应很分裂。
支持者说"终于不用手动处理 Cloudflare 了"。质疑者则指出一个核心问题:Cloudflare 也在进化。
在那条 3300 赞的推文下面,一条高赞评论写道:
"Give it 2 days and Cloudflare will patch it."
"给它两天,Cloudflare 就会修补。"
这并非危言耸听。反爬和绕过本质上是军备竞赛。Scrapling 的 StealthyFetcher 今天能过的保护,明天可能就需要更新。Cloudflare 的 Turnstile 一直在迭代,指纹检测越来越精细。
官方文档也很坦率地提到:极端防护场景下仍然需要代理服务。仓库的赞助商列表里就有好几家专业代理商——DataImpulse、Proxidize——说明开发者自己也清楚,纯工具不能解决所有问题。
真正的杀手锏:网站改了选择器,它自己"记得回来"
如果只看速度和反爬,Scrapling 跟 Playwright + Camoufox、Crawlee、Firecrawl 等竞品比并不算碾压级优势。
但自适应解析器(adaptive parser)几乎没有对手做到这个程度。
传统爬虫的噩梦是什么?你花半天写好选择器,跑了三周,某天早上发现网站改版——class="price-old"变成了class="product-price"、DOM 层级调了一下——脚本直接报废,又得重新调试。
Scrapling 的做法是给元素建"指纹":记录它的标签类型、属性组合、文本内容、兄弟节点和父节点路径。首次抓取时用auto_save=True保存指纹,之后就算 class 名改了、结构位移了,用adaptive=True去找,它能通过相似度匹配把元素"认回来"。
# 第一次:保存指纹 page = Fetcher.get(url) price = page.css_first(".price-tag", auto_save=True) # 网站改版后:自动找回 page = Fetcher.get(url) price = page.css_first(".price-tag", adaptive=True) # 即使 class 变了,仍能定位到同一个元素
ScrapingBee(一家做抓取 API 的公司)在 2026 年 2 月发了一篇深度评测,核心观点就是:自适应功能是 Scrapling 的真正差异化卖点,显著降低了维护循环的成本。

▲ ScrapingBee 评测认为自适应选择器显著降低维护成本
不过这篇评测也加了一个注脚:Scrapling 仍然是个年轻项目,某些边角场景还比较粗糙。
这个"自愈"能力到底多强?它能处理 class 改名、属性调整、层级小幅位移。但如果一个网站做了彻底的 DOM 重构——整个页面模板换掉——指纹匹配也会失效。
所以更准确的理解是:它把"每周手动修脚本"变成了"偶尔检查一下成功率"。维护成本没有归零,但降了一个数量级。
社区怎么看? "真香"和"别吹了"两边都有
翻 Reddit 的 r/webscraping 和 X 上的讨论,Scrapling 的评价呈现出典型的开源项目分化:
看好的人觉得它降低了抓取门槛,尤其是中小团队和独立开发者。"终于不用每周修脚本了"——这是出现频率最高的赞美。
质疑的人集中在几个点:
一是 Cloudflare 绕过的持久性。多个老手表示,Playwright + Camoufox 的组合在实战中更可控,Scrapling 的 StealthyFetcher 封装了太多细节,出问题时难以调试。
二是性能数字的上下文。784 倍的合成测试在实际爬虫场景中意义有限,"真到要爬的时候,瓶颈是 I/O"。
三是"无需代理"的说法。纯 HTTP 模式的 Fetcher 速度最快,但绕不过保护;浏览器模式能过保护,但速度和资源消耗都上去了。对于大批量任务,代理仍然跑不掉。
比较理性的评价来自一条 Reddit 评论(大意):"对新手友好,对老手是补充工具——但不要以为装了它就什么站都能抓。"
AI Agent 需要"网页眼睛",这事是真的
抛开争议,Scrapling 踩中的一个趋势无可否认:AI Agent 需要从网页获取结构化数据的能力。
Scrapling 内置了 MCP(Model Context Protocol)Server。接入后,Claude、Cursor 等 AI 工具可以直接让 Scrapling 先提取干净的结构化片段,再喂给 LLM——省 token、数据更准确。
想象一个场景:你让 AI Agent 监控竞品的定价页面。传统做法是把整个 HTML 页面扔给 LLM,token 消耗巨大且容易出错。用 Scrapling 的 MCP Server,Agent 调用 Scrapling 提取"价格 + 产品名 + 时间戳",只把清洗后的结构化数据交给 LLM 处理。
这条路径上,Scrapling 的自适应能力就变得格外重要——你不能让一个 7x24 运行的 Agent 因为网站改了一个 class 名就停摆。
价格监控、新闻聚合、产品图片抓取——这三个场景恰好是 AI Agent 落地最密集的方向。Scrapling 的 Spider 框架支持异步并发、暂停恢复、流式输出,对接这类持续运行的自动化任务天然契合。
65000 Star 的含金量
回过头看,Scrapling 的 6.5 万星增长曲线背后有两股力量在推。
一股是真实需求。每个写过爬虫的人都经历过"选择器又废了""Cloudflare 又升级了""脚本跑着跑着就挂了"的痛苦。Scrapling 把这些痛点打包成一个pip install,门槛足够低。
另一股是社交媒体的放大效应。"784 倍速度""绕过 Cloudflare""干掉验证码行业"——每一条都是高转发素材。从 3 月的英文爆款帖到 6 月的西班牙语帖子,这些数字被反复引用,驱动了持续增长。
这些数字被简化了吗?当然。"784 倍"省掉了"合成测试 + 纯解析场景"的限定词;"绕过 Cloudflare"省掉了"军备竞赛 + 可能需要代理"的后半句。
但项目本身是扎实的:92% 的测试覆盖率、活跃的版本迭代(v0.4.9 持续更新中)、完整的类型提示、多语言文档。官方 README 底部也加了免责声明——仅用于教育和研究目的,请遵守 robots.txt 和当地法律。
如果你的工作里有"定期从网页抓数据"这件事,Scrapling 值得花半小时试一下。它不会让反爬军备竞赛消失,但它确实让普通开发者在这场竞赛中多了一个趁手的武器。
65000 个 Star 里,有多少是被营销数字吸引来的?大概不少。但留下来的人,多半是因为自适应选择器帮他们少修了几十个破掉的脚本。
而这件事,比"784 倍速度"实在多了。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
