期刊图片复现|Python回归分析全流程深度解析-回归拟合图、SHAP特征重要性总览图、交互作用强度气泡图、单特征依赖图、双特征交互效应图
- 2026-07-02 13:11:39
期刊图片复现|Python回归分析全流程深度解析-回归拟合图、SHAP特征重要性总览图、交互作用强度气泡图、单特征依赖图、双特征交互效应图

论文:Divergent responses of canopy structure and productivity to drought and their driving mechanisms in northern China’s grasslands 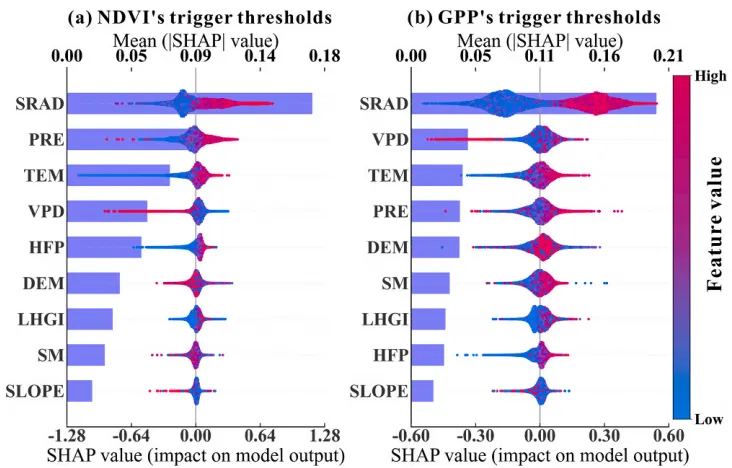
论文原图 本套代码构建了一个从数据摄取、模型调优到可解释性分析及分析出图的完整机器学习分析流程,首先读取数据集,划分训练集与测试集,通过网格搜索结合交叉验证自动探寻最佳超参数,从而构建出具备极强非线性捕捉能力的XGBoost回归模型;在完成初步的预测评估并绘制带有基准参考线的真实-预测拟合散点图后,切入核心的SHAP归因分析环节,利用TreeSHAP算法高效计算全局样本的主效应与交互SHAP值,绘制出融合宏观特征重要性与数据分布的组合图,以及直观揭示驱动因子间两两协同互作强度的气泡热力图;在单因素依赖图与双特征交互图中,内嵌了基于Bootstrap自举重采样的LOWESS非参数局部加权平滑算法,为散点趋势附上了严谨的95%置信区间,还能够自动探测并高亮标注出环境驱动因子作用于Y时触发阈值时由负转正的交叉点,在多维特征交互时能捕捉到次级因子状态改变所引发的共阈值突变现象,同时搭载了60种经典配色的定制颜色库。 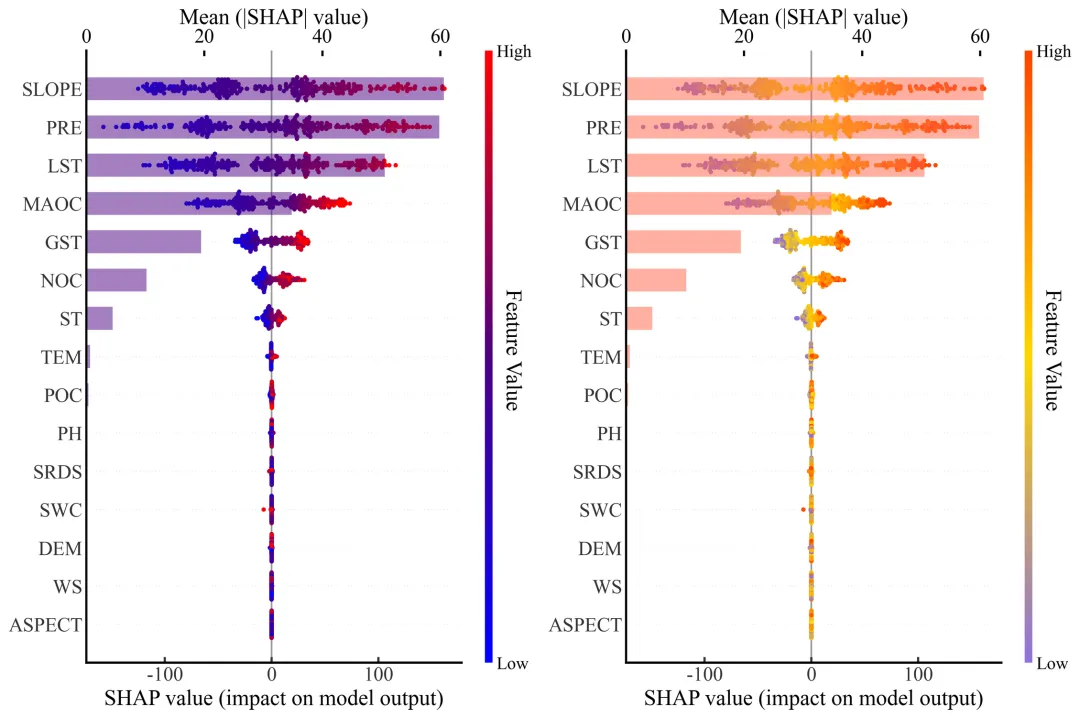
仿图 



库的导入以及字体设置 

设置颜色库 

边框与刻度设置辅助函数 

结果图保存辅助函数 

拟合线和置信区间计算函数:为散点图生成LOWESS拟合曲线及其置信区间。通过有放回地抽取数据子集,对每一个子集进行LOWESS平滑拟合,并统一映射到一个标准的X轴上。然后计算原始数据的中心拟合线以及95%置信区间上下界。 

阈值点寻找函数:在SHAP依赖图中寻找特征对模型预测从负面影响(SHAP < 0)转向正面影响(SHAP > 0)的零界点或阈值。 

阈值点绘制以及标注函数:找到交点阈值后在X坐标处绘制一条垂直虚线。同时循环检查新标签位置是否与已存在的标签重叠。如果有重叠,就将标签自动下移,直至找到空位。最后在这个位置绘制带有背景框的文本。 

回归拟合图绘制函数:回归模型拟合图,横轴代表真实值,纵轴代表模型的预测值,其中圆形散点表示训练集数据,三角形散点表示验证集数据,贯穿图表的黑色虚线为1:1基准线,散点越贴近该虚线说明模型的预测结果越准确,同时右下角的浅色文本框详细列出了模型在验证集和训练集上的决定系数、均方根误差以及平均绝对误差等关键性能评估指标,直观地呈现了模型整体的预测精度和拟合优度。 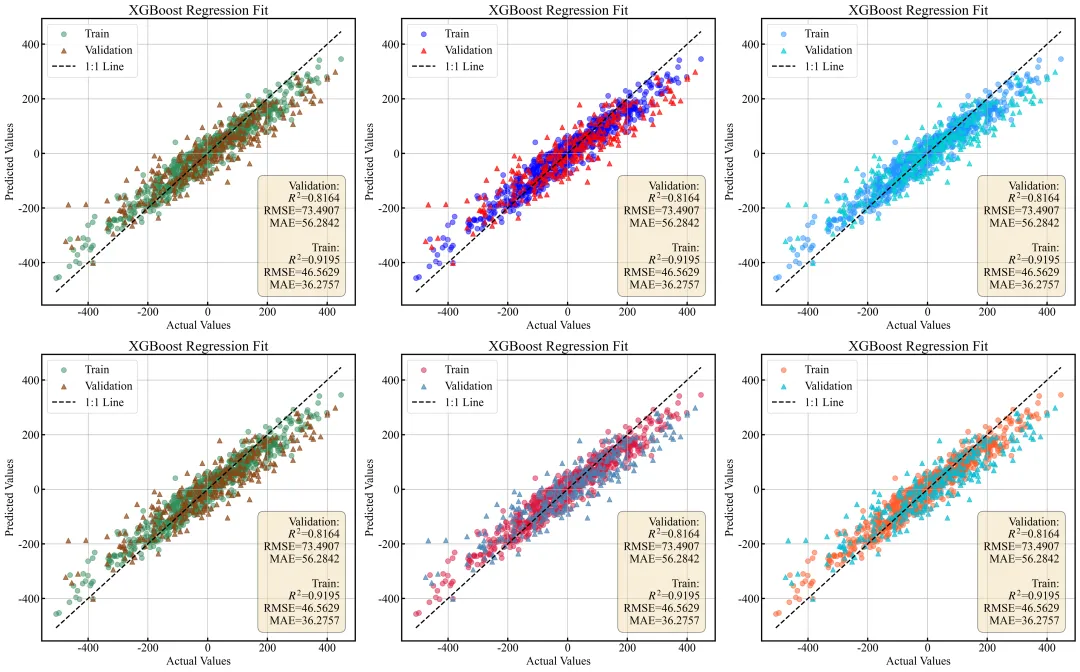


特征重要性条形图与SHAP蜂巢图组合图绘制函数:特征重要性条形图与SHAP蜂巢图,图表自上而下按照特征对模型全局重要性的大小进行了降序排列,水平条形图对应上方的坐标轴,代表各特征的平均绝对SHAP值,即宏观上的全局重要性大小;而表层的蜂群散点图对应下方的坐标轴,展示了每个数据样本在特定特征下的具体SHAP值分布情况,散点的颜色反映了该特征本身数值的高低,从而清晰地揭示了某个特征的高值或低值是如何微观且具体地对模型预测结果产生正向或负向驱动影响的。 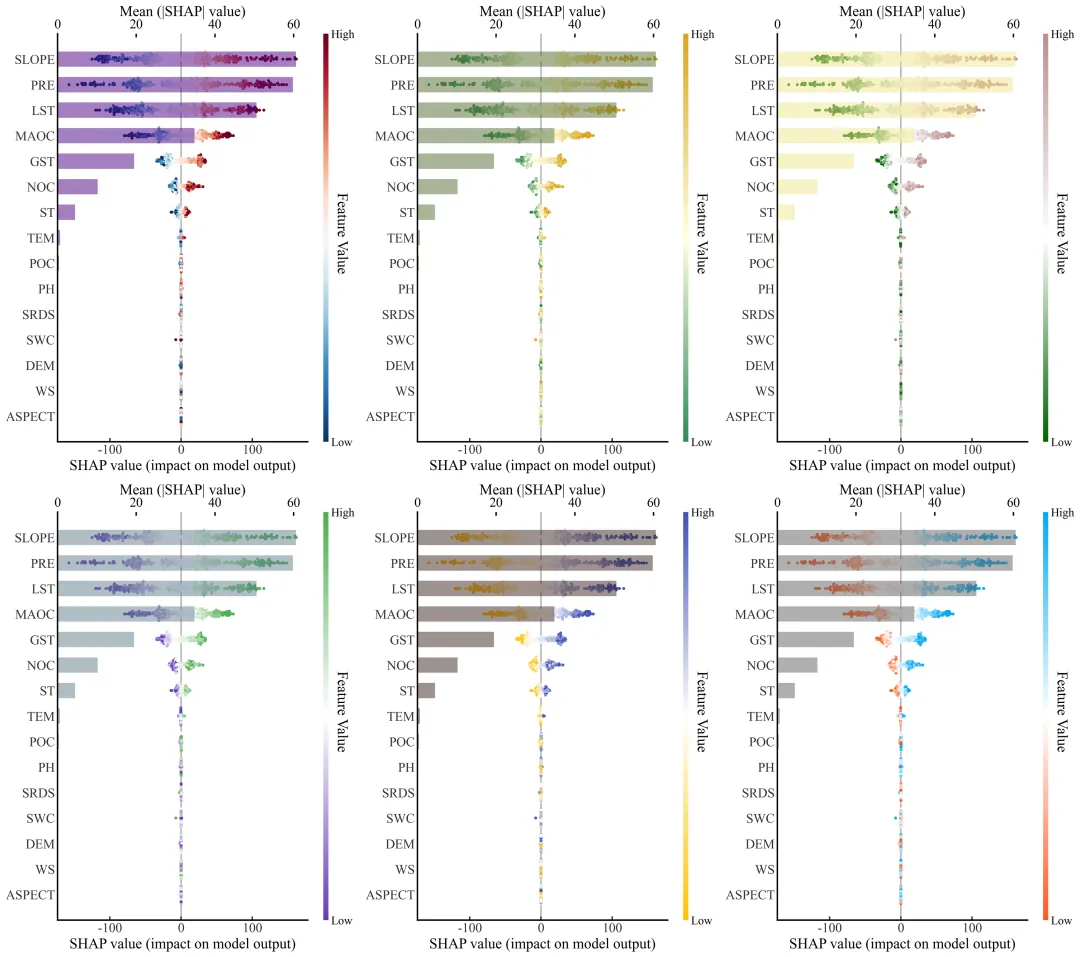


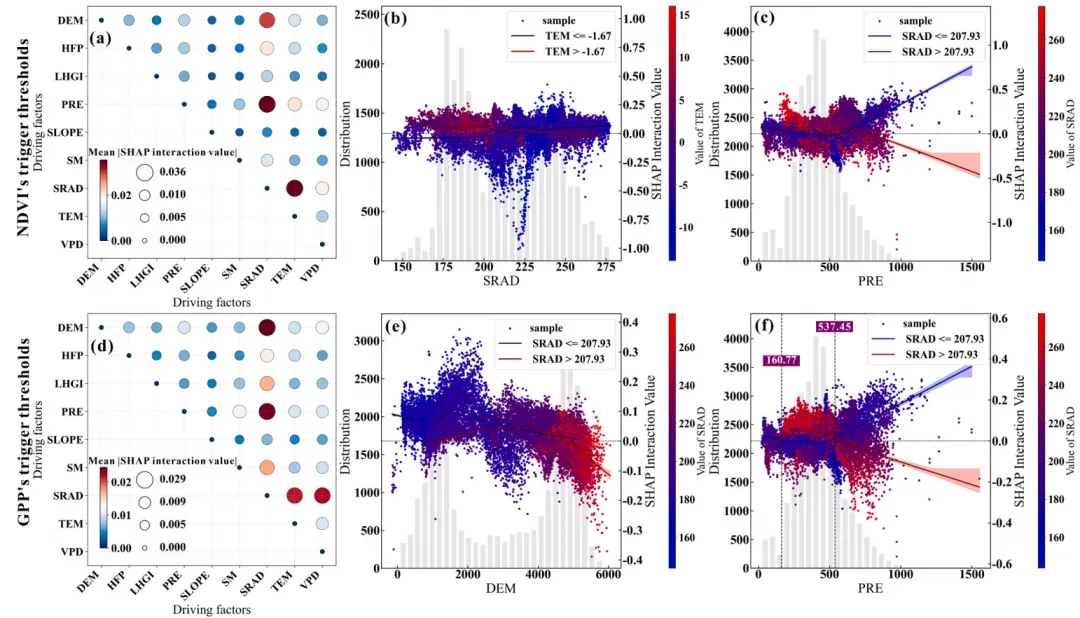
特征交互强度气泡热力图绘制函数:特征交互强度的气泡热力图,横纵坐标为影响预测目标的各个驱动因子,右上三角矩阵展示了任意两个特征之间的平均SHAP交互效应绝对值,图中气泡的大小和颜色深浅共同映射了交互作用的强度,气泡尺寸越大且颜色越偏向红色代表两个特征间的协同交互作用越强烈,偏向蓝色或气泡极小则代表交互作用微弱,而对角线位置的自交互项被强制设为零,旨在直观且突出地反映不同特征两两之间对模型预测结果影响。 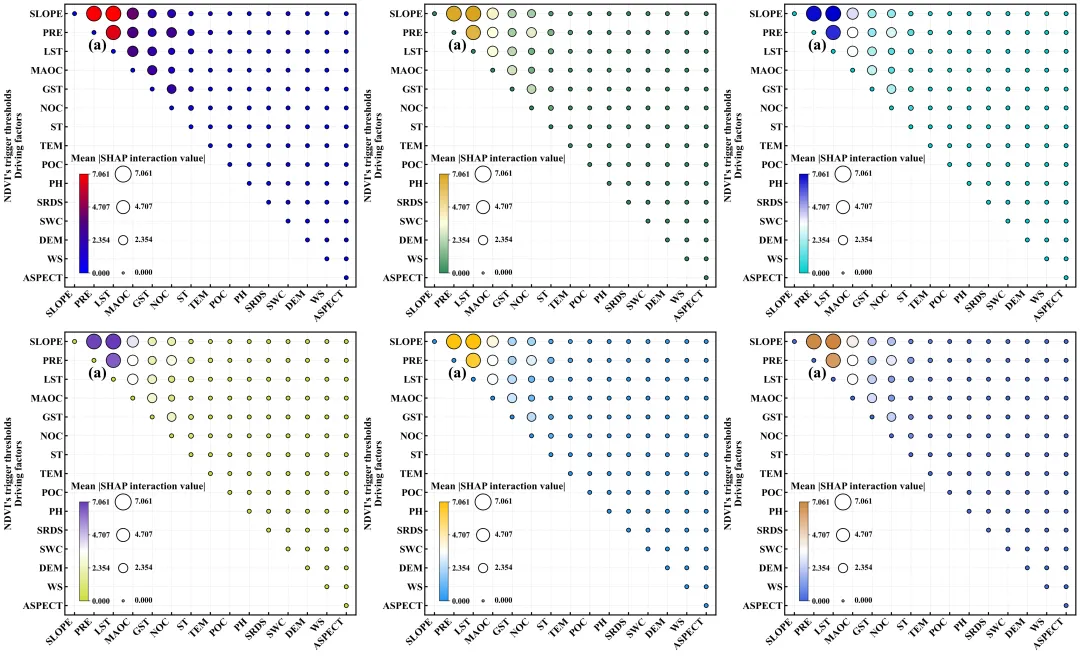


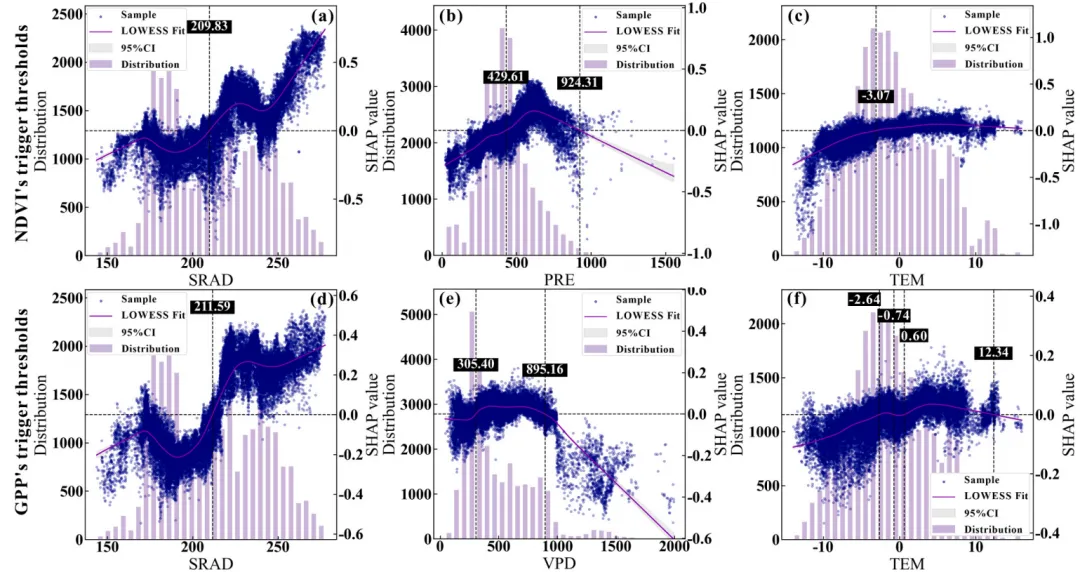
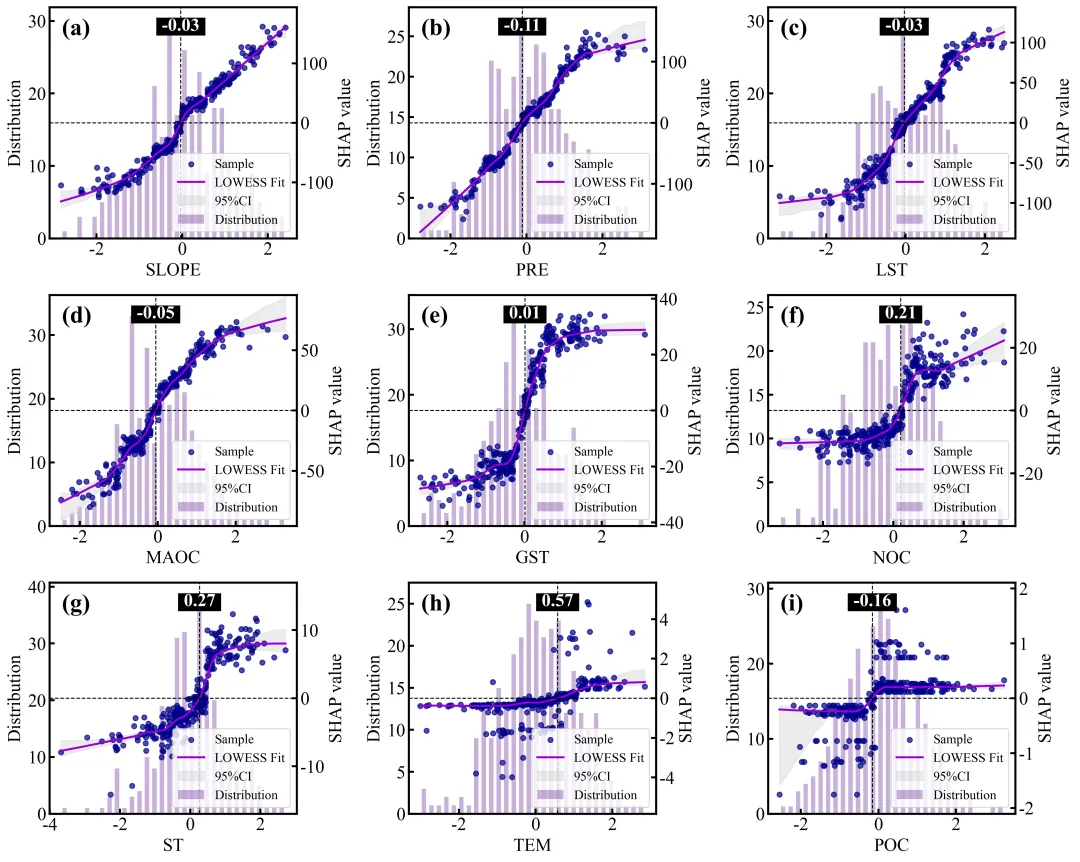
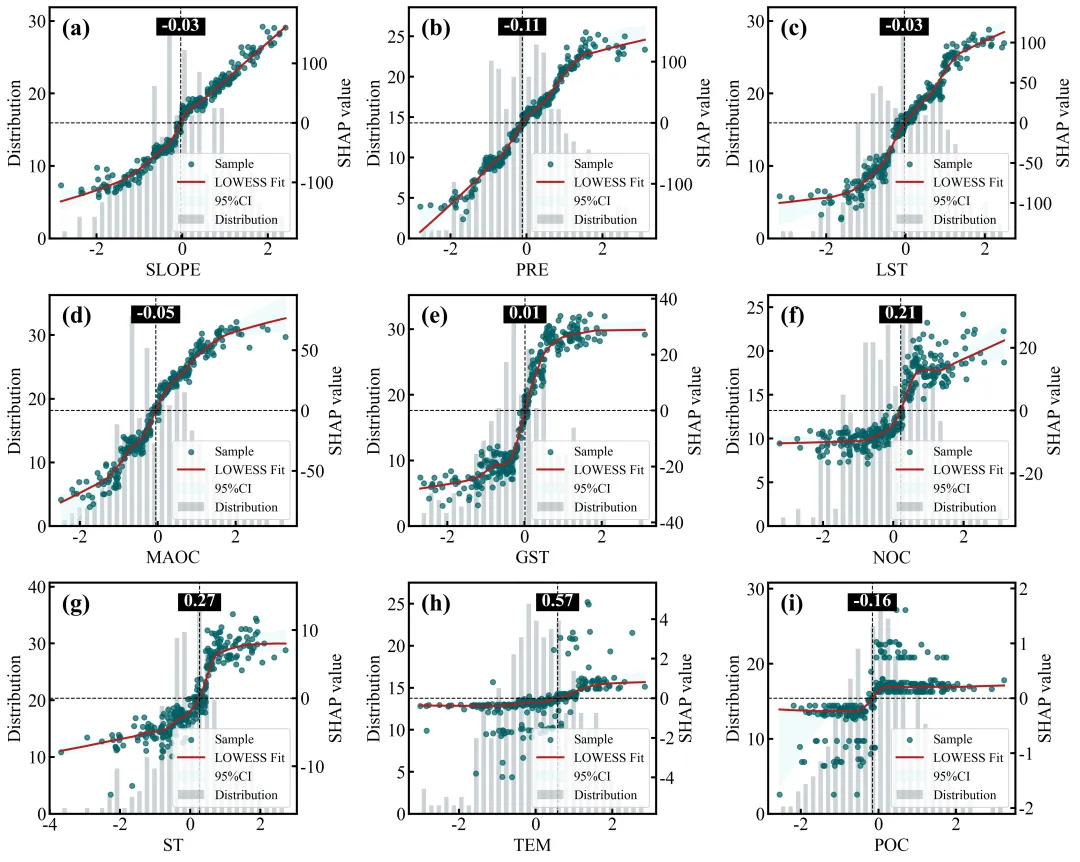
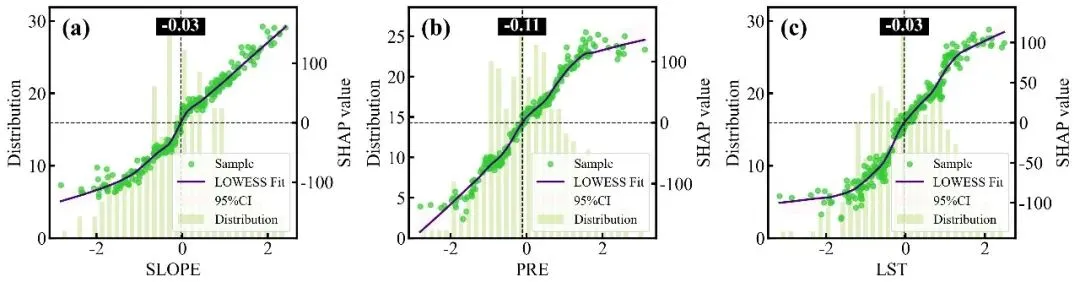
SHAP单因素依赖图绘制函数:排名前9位重要特征的SHAP单因素依赖图网格,每个子图均采用了双Y轴设计,其中背景柱状图对应左侧的Distribution轴,反映了该特征在样本数据中的频数分布状态;蓝色的散点和紫色的LOWESS平滑拟合曲线(带有灰色的95%置信区间阴影)对应右侧的SHAP value轴,展示了特征取值变化对其自身SHAP值(即对预测结果的独立贡献)的非线性影响趋势;图中的水平黑色虚线代表SHAP作用为0的基准线,而垂直的黑色虚线及其上方黑底白字的数值标签则精准标注了拟合曲线跨越零点时的特征阈值,即该特征作用由负面彻底转为正面的临界转折点。 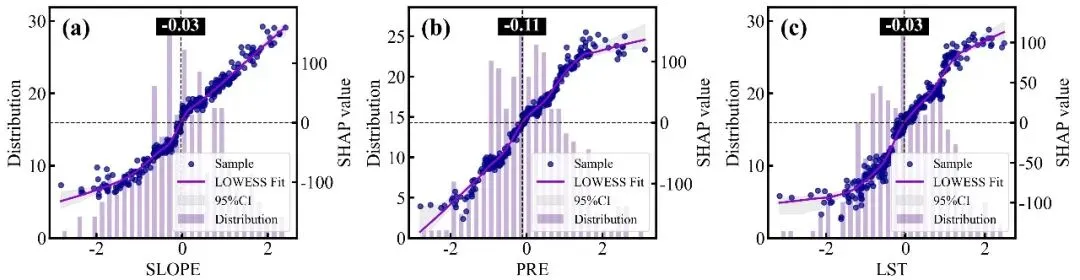
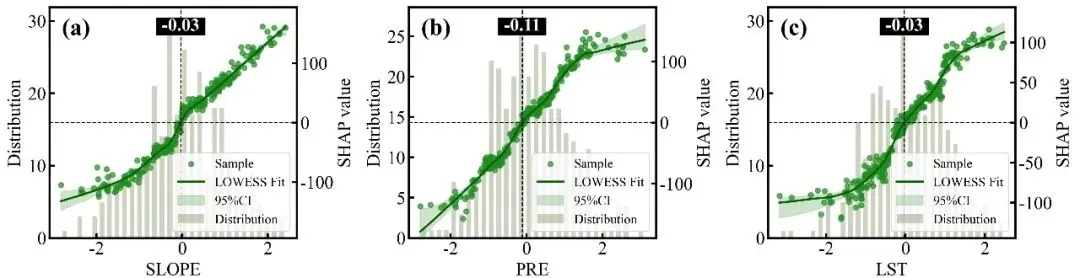
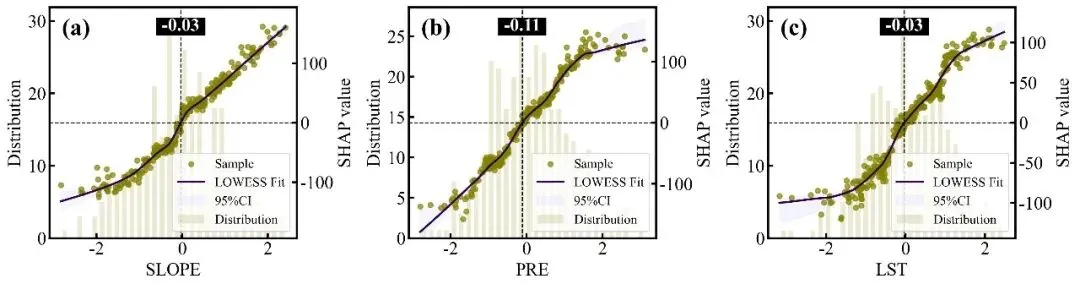
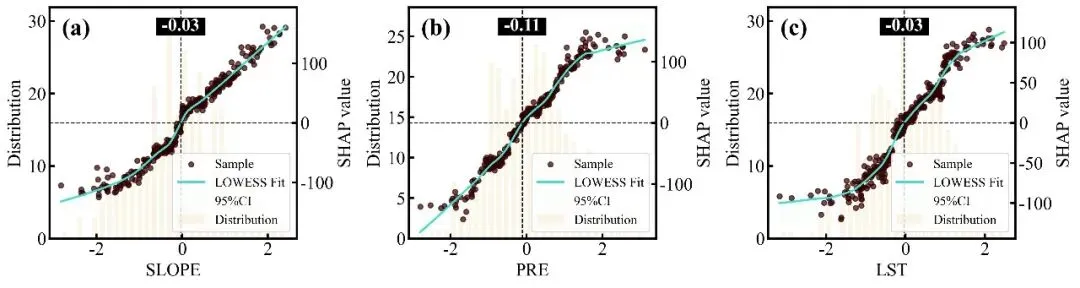
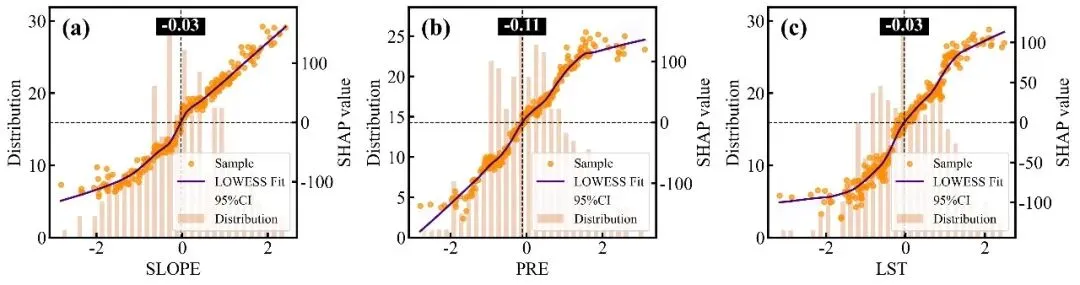


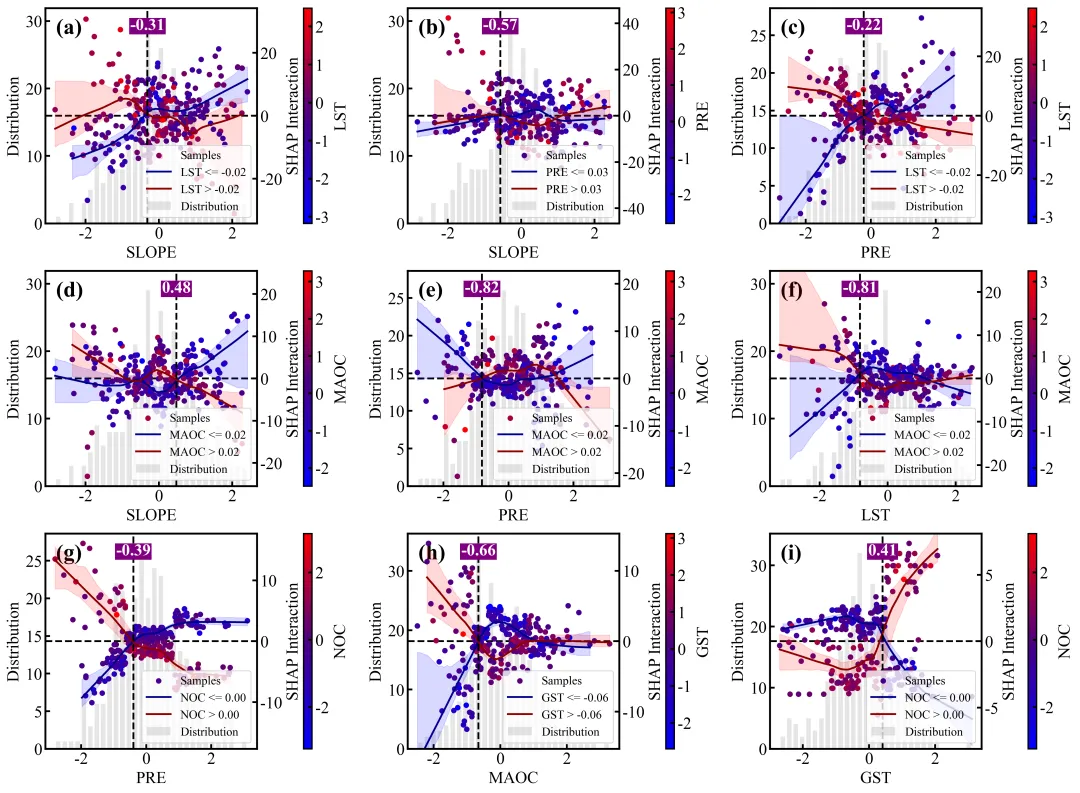
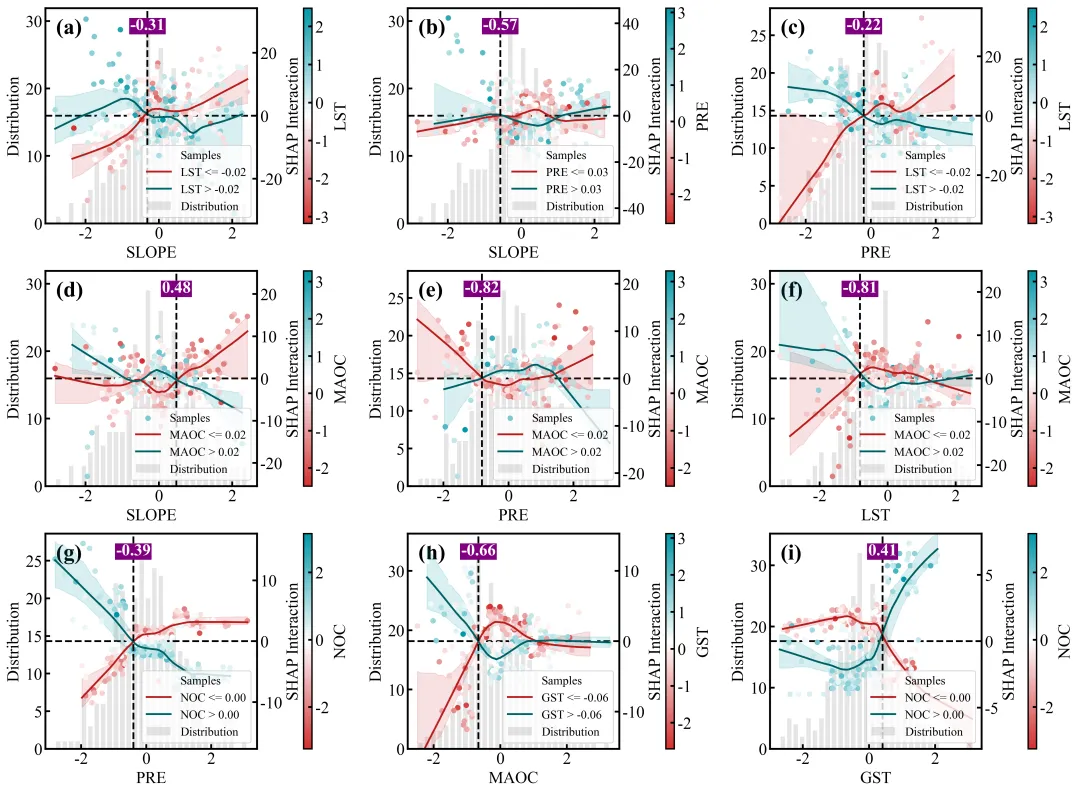
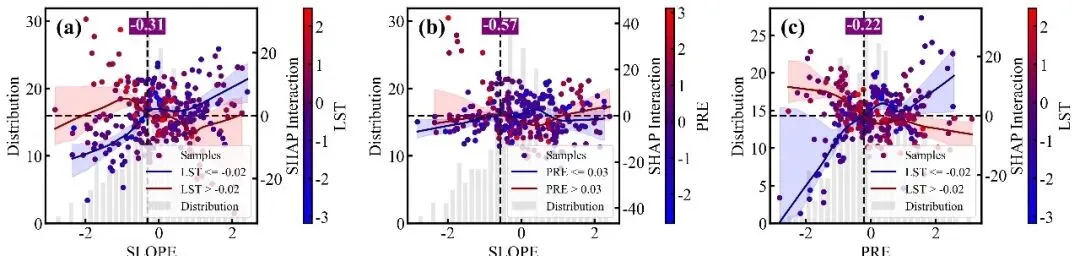
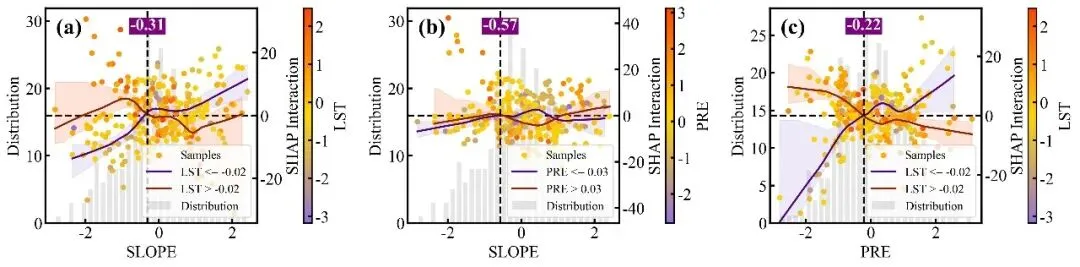
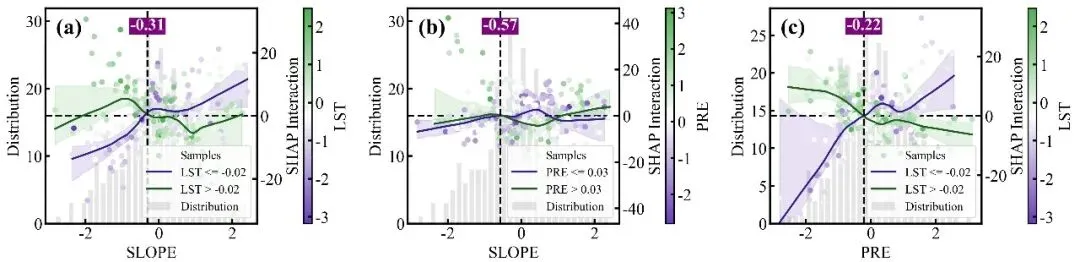
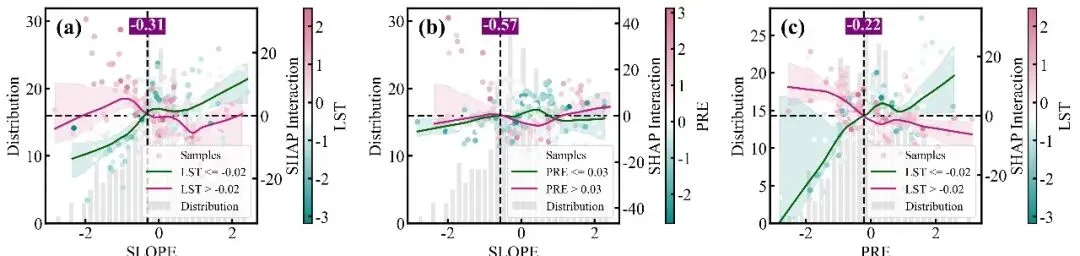
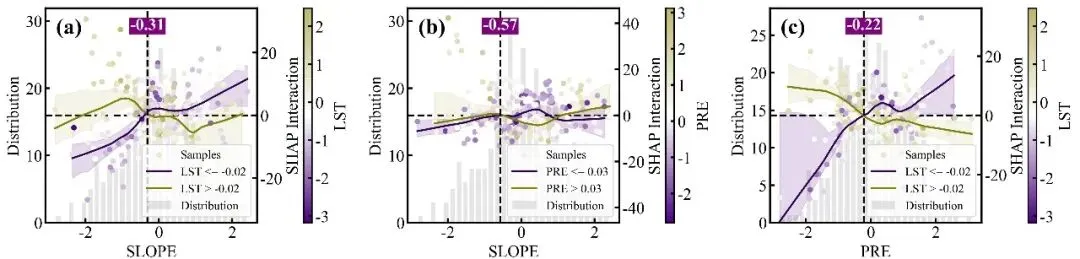
特征交互效应依赖图绘制函数:交互强度排名前9位的双特征交互效应依赖图网格,每个子图同样采用双Y轴设计,浅灰色的背景柱状图显示主特征的数据分布频数,而双色散点图则展示了这两个特征的互作效应对模型SHAP值的具体影响;图中的散点颜色由右侧独立颜色条代表的次要特征数值大小所映射,图中的深红和深蓝两条拟合曲线及其对应的浅色置信区间,分别代表了次要特征处于高值组(大于中位数)和低值组(小于等于中位数)两个条件下的主特征SHAP影响趋势,垂直黑色虚线及紫底白字的数值标签则高亮标注了这两条高低分组曲线在横轴上共同穿过零点附近的交互突变阈值,深刻揭示了次要特征状态的改变是如何扭转或放大主特征对模型预测贡献的。 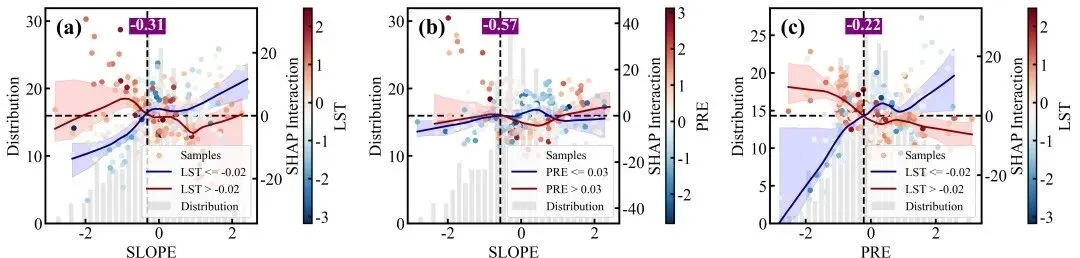


执行部分:从指定路径加载数据。以7:3的比例切分训练集和测试集。初始化XGBoost回归树模型,定义了树的数量、深度和学习率等核心超参数。使用带交叉验证(CV=3)的网格搜索求解最佳模型参数,并对得到的最佳模型 



期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
代码解释
第一部分
# =========================================================================================# ====================================== 1. 环境设置 =======================================# =========================================================================================import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport osfrom statsmodels.nonparametric.smoothers_lowess import lowess
第二部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================COLOR_SCHEMES = {0: {'train': 'blue', 'test': 'red', 'hist': '#4B0082', 'shap_scatter': '#00008B', 'lowess': '#9400D3','ci': '#D3D3D3', 'inter_low': 'blue', 'inter_low_fit': 'darkblue', 'inter_high': 'red',}
第三部分
# =========================================================================================# ======================================3.边框与刻度设置辅助函数=======================================# =========================================================================================def apply_plot_styles(ax, tick_width=2, tick_length=5, spine_width=2, label_size=18):for spine in ax.spines.values(): #遍历边框spine.set_linewidth(spine_width) #设置边框线宽#设置刻度ax.tick_params(axis='both', #轴which='major', #主刻度direction='in', #朝向width=tick_width, #粗细length=tick_length,#长labelsize=label_size)#字体大小
第四部分
# =========================================================================================# ======================================4.结果图保存辅助函数======================================# =========================================================================================def save_fig_dual(fig, folder, filename_base, dpi=300):os.makedirs(folder, exist_ok=True) #如果文件夹不存在则创建png_path = os.path.join(folder, f"{filename_base}.png") #拼接保存路径pdf_path = os.path.join(folder, f"{filename_base}.pdf")fig.savefig(png_path, dpi=dpi, bbox_inches='tight') #保存fig.savefig(pdf_path, dpi=dpi, bbox_inches='tight')
第五部分
# =========================================================================================# ======================================5.拟合线和置信区间计算函数=======================================# =========================================================================================#使用LOWESS拟合数据,通过Bootstrap生成大量拟合线,从而计算出95%的置信区间def bootstrap_lowess_ci(x, y, n_boot=200, frac=0.5, ci_level=0.95):#少于10个,不进行拟合if len(x) < 10:return None, Noneboot_lines = [] #用于存放每次重采样拟合出来的曲线x_range = np.linspace(x.min(), x.max(), 100) #在x的极值范围内均匀生成100个点,用作统一的插值横坐标boot_lines_arr = np.array(boot_lines) #将重采样曲线列表转换为NumPy数组,便于计算分位数alpha = (1 - ci_level) / 2 #根据置信水平计算单侧分位数的概率值lower_bound = np.quantile(boot_lines_arr, alpha, axis=0) #置信下界upper_bound = np.quantile(boot_lines_arr, 1 - alpha, axis=0) #置信上界return main_smoothed, (x_range, lower_bound, upper_bound) #拟合曲线、x范围、置信上下界
第六部分
# =========================================================================================# ======================================6.阈值点寻找函数=======================================# =========================================================================================#寻找曲线穿过y=0的所有交点/X坐标。通过检测y值正负号的变化,利用两点线性插值法精确计算出过零点的x坐标def find_roots(x_curve, y_curve):roots = [] #存放根/零点的列表sign_changes = np.where(np.diff(np.sign(y_curve)))[0] #计算y值的符号差,找出正负号发生变化的相邻点索引return roots # 返回所有找到的零点列表
第七部分
# =========================================================================================# ======================================7.阈值点绘制以及标注函数=======================================# =========================================================================================#算出零点,还在图表上画出垂直虚线,标上数值标签def find_and_plot_crossings(ax, x_curve, y_curve, color, x_range):sign_changes = np.where(np.diff(np.sign(y_curve)))[0] #找出y值正负值发生变化的位置索引drawn_texts = [] #保存文本坐标ax.text(x_root, #xy_pos, #yf' {x_root:.2f} ', #文本color='white', #颜色backgroundcolor=color, #颜色ha='center', #水平va='top', #垂直fontsize=18, #字体大小fontweight='bold',#加粗bbox=dict(facecolor=color, edgecolor='none', pad=1), #文本框transform=ax.get_xaxis_transform()) #设置坐标变换drawn_texts.append((x_root, y_pos)) #保存
第八部分
# =========================================================================================# ======================================8.回归拟合图=======================================# =========================================================================================def plot_regression_results(metrics, colors, output_folder):fig = plt.figure(figsize=(8.7, 8)) #创建画布ax = plt.gca() #获取当前画布坐标轴all_y = pd.concat([metrics['train']['true'], metrics['test']['true']]) #合并训练集和测试集的真实值数据#1:1线plt.plot([all_y.min(), #起点xall_y.max()], #终点x[all_y.min(), #起点yall_y.max()], #终点y'k--', #样式lw=2, #线宽label='1:1 Line') #图例名# 设置边框和刻度apply_plot_styles(ax)# 保存save_fig_dual(fig, output_folder, 'regression_fit_plot')plt.close(fig) #关闭
第九部分
# =========================================================================================# ======================================9.特征重要性条形图与SHAP蜂巢图组合图绘制函数=======================================# =========================================================================================def plot_shap_summary(shap_values, X_test, feature_names, shap_df, base_values, colors,output_folder):#创建画布fig = plt.figure(figsize=(10, 10), dpi=300)ax_sw = fig.add_axes([0.32, 0.11, 0.59, 0.77]) #定义主坐标轴在画布上的相对位置及大小ax_bar = ax_sw.twiny() #创建共享Y轴y_pos = np.arange(len(feature_names))[::-1] #生成逆序的Y轴坐标序列,使重要特征排在最上面#绘制水平条形图ax_bar.barh(y=y_pos, #ywidth=shap_df["mean_shap"].values, #条形长度height=0.6, #高度color=colors['hist'], #颜色alpha=0.5, #透明度edgecolor="none", #边框线zorder=0) #层ax_sw.set_xlabel("SHAP value (impact on model output)", fontsize=20) #下x轴标题ax_sw.set_yticks(y_pos) #主坐标轴的Y轴刻度位置与背景条形图ax_sw.set_yticklabels(feature_names, fontsize=12) #Y轴刻度文本#设置边框ax_sw.spines['top'].set_visible(False)ax_sw.spines['right'].set_visible(False)ax_bar.spines['top'].set_visible(False)ax_bar.spines['right'].set_visible(False)apply_plot_styles(ax_sw) #调整边框和刻度粗细apply_plot_styles(ax_bar) # 调整边框和刻度粗细#保存save_fig_dual(fig, output_folder, 'combined_shap_summary_plot')plt.close(fig) #关闭
第十部分
# =========================================================================================# ======================================10.特征交互强度气泡热力图绘制函数=======================================# =========================================================================================def plot_bubble_heatmap(shap_interaction, feature_names, colors, output_folder):scatter = ax.scatter(x_idx, #xy_idx, #ys=sizes, #大小c=colors_vals, #交互强度值cmap=cmap, #颜色映射vmin=0, #颜色映射的最小值vmax=max_val, # 颜色映射的最大值alpha=1, #透明度edgecolors='black', #边缘线颜色linewidth=1.3, #边缘线粗细zorder=2) #层ax.set_xticks(range(n_features)) #设置x轴刻度位置#背景网格线ax.grid(True, #开启linestyle=':', #样式alpha=0.6, #透明度zorder=1) #层cax = ax.inset_axes([0.05, 0.05, 0.03, 0.35]) #创建颜色条轴cbar = plt.colorbar(scatter, cax=cax) #生成颜色条cbar_ticks = [0.00, max_val / 3, max_val * 2 / 3, max_val] #颜色条刻度值cbar.set_ticks(cbar_ticks) #应用到颜色条上#刻度值cbar.ax.set_yticklabels([f'{v:.3f}' for v in cbar_ticks], fontsize=14, fontweight='bold')y_positions = [0.4, 0.283, 0.166, 0.05] #气泡图例位置legend_vals = [max_val, max_val * 2 / 3, max_val / 3, 0.00] #气泡图例显示的气泡大小save_fig_dual(fig, output_folder, 'shap_interaction_bubble_heatmap_diag_zero') #保存plt.close(fig) #关闭
第十一部分
# =========================================================================================# ======================================11.SHAP单因素依赖图绘制函数=======================================# =========================================================================================def plot_dependence(X_test, shap_values, feature_names, colors, save_folder):n_features = min(9, len(feature_names)) #只选择前9个最重要特征进行绘制#创建画布ax2 = ax1.twinx() #创建第二个Y轴对象counts, bin_edges = np.histogram(x_values, bins=30) #计算特征数据的直方图分布,返回频数和边界bin_centers = (bin_edges[:-1] + bin_edges[1:]) / 2 #计算每个区间的中心x坐标bin_width = bin_edges[1] - bin_edges[0] #单个区间的宽度# 在主图层上绘制分布条形图,X坐标使用区间中心点ax1.bar(bin_centers, #xcounts, #ywidth=bin_width * 0.6, #柱体宽度align='center', #居中对齐color=colors['hist'], #颜色alpha=0.3, #透明度label='Distribution') #图例标签ax1.set_ylim(0, counts.max() * 1.1) #左侧y轴范围#绘制散点ax2.scatter(x_values, #xshap_vals, #yalpha=0.7, #透明度s=25, #散点大小color=colors['shap_scatter'], #颜色label='Sample', #图例标签zorder=2) #层save_fig_dual(fig, save_folder, 'dependence_top9_grid') #保存plt.close(fig) #关闭
第十二部分
# =========================================================================================# ======================================12.特征交互效应依赖图绘制函数=======================================# =========================================================================================def plot_interaction(X_test, shap_interaction, feature_names, colors, save_folder):n_features = len(feature_names) #获取特征总数interaction_strengths = [] #用于保存任意两个特征之间的交互强度points = ax2.scatter(x_vals, #xshap_vals,#yc=inter_vals,#根据副特征数值上色cmap=cmap,#颜色映射alpha=1,#透明度s=25, #大小zorder=2,#层label='Samples') #图例标签median_val = inter_vals.median() #计算次特征中位数,用以划分高低两个子组#定义划分高低组信息的字典groups = {'low': {'mask': inter_vals <= median_val, 'color': colors['inter_low'], 'fit': colors['inter_low_fit'],'label': f'{s_name} <= {median_val:.2f}'},'high': {'mask': inter_vals > median_val, 'color': colors['inter_high'], 'fit': colors['inter_high_fit'],'label': f'{s_name} > {median_val:.2f}'}}#颜色条轴cax_auto = ax2.inset_axes([1.22, 0.0, 0.04, 1.0])#创建颜色条cbar = fig.colorbar(points, cax=cax_auto)#标题cbar.set_label(s_name, size=18, labelpad=5)#刻度设置cbar.ax.tick_params(labelsize=18)cbar.ax.tick_params(axis='y', width=2, length=4, direction='in')# 控制颜色条自身的外边框线宽for spine in cbar.ax.spines.values():spine.set_linewidth(1.5)# 控制颜色条自身的外边框线宽for spine in cbar.ax.spines.values():spine.set_linewidth(1.5)
第十三部分
记录训练集和测试集的性能指标。调用 shap.Explainer 结合树模型的高效TreeSHAP算法,计算测试集全部样本的特征主效应SHAP值以及二阶交互作用。计算SHAP绝对均值并按重要性从大到小对特征名称、数据矩阵、SHAP矩阵和交互矩阵进行重排序,调用上面的函数分析绘图。# =========================================================================================# ======================================13.执行部分=======================================# =========================================================================================if __name__ == '__main__':excel_file_path = r'data.xlsx' #原始数据test_size = 0.3 #测试集比例random_state = 0 #随机种子os.makedirs(output_folder, exist_ok=True) #是否存在,若无则自动创建一个新文件夹df = pd.read_excel(excel_file_path) #读取数据y = df[target_column_name] #目标X = df.drop(columns=[target_column_name]) #特征metrics = {} #保存性能指标#遍历数据评估for name, X_data, y_data in [('train', X_train, y_train),('test', X_test, y_test)]:y_pred = best_model.predict(X_data) #预测explainer = shap.Explainer(best_model) #shap解析器shap_values_obj = explainer(X_test) # 测试集分析#提取SHAP的基准预测值base_values = shap_values_obj.base_values[0] if isinstance(shap_values_obj.base_values, (np.ndarray,list)) else shap_values_obj.base_values#是否批量绘图plot_all =True
如何应用到你自己的数据
1.设置原始数据的保存路径,执行部分:
excel_file_path = r'data.xlsx' #原始数据2.设置目标变量,执行部分:
target_column_name = 'FVC' #目标变量3.设置绘图结果的保存地址,执行部分:
output_folder = r'效应图' #结果路径4.设置测试集的比例,执行部分:
test_size = 0.3 #测试集比例5.设置随机种子,执行部分:
random_state = 0 #随机种子6.设置超参数网格,执行部分:
param_grid = {'n_estimators': [10, 20, 50],'max_depth': [2, 3, 5],'learning_rate': [0.05, 0.1]}
7.设置是否要进行批量绘图,执行部分:
plot_all =True推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 零基础用 PHP+MySQL 搭建公众号导航站,完整开发思路全拆解
- 企业级 Linux 用户管理平台建设、DevSecOps 集成与成熟度评估实践
- Linux UFW 防火墙配置——端口规则与服务保护
- 最新Linux的本地提权漏洞分析
- Linux "一切皆文件"到底是什么意思?
- 适合你的 Linux 桌面界面是什么?
- 嵌入式 Linux:udev 设备管理服务
- 全国计算机等级考试二级Python和二级C语言考哪个对以后就业更有帮助?
- 面向Python的阿拉伯语NLP工具:CAMeL Tools、Farasa、AraBERT与MARBERT
- 自学编程第52课:Python爬虫入门——解析网页内容,用BeautifulSoup从网页里“挑”出你想要的信息
