自学编程第52课:Python爬虫入门——解析网页内容,用BeautifulSoup从网页里“挑”出你想要的信息
- 2026-06-29 22:44:10


上一课我们学会了用`requests` 获取网页源码,Tyree说:“现在我能拿到网页了,但我要的是‘每天的温度’啊!这一大堆乱糟糟的标签,怎么把温度数字单独拿出来?”
我说:“这就是今天要学的内容。你用
`BeautifulSoup` 把HTML拆开,像在一堆零件里挑出你想要的螺丝。”
今天,我们就用爬取天气预报作为主线例子,学用BeautifulSoup从网页里“挑”出你想要的信息。
01. 安装BeautifulSoup
在命令行执行(如果还没装):
需要逐个安装
pip install beautifulsoup4
pip install lxml
解释:
`beautifulsoup4`:解析库,负责“读懂”HTML结构。
`lxml`:解析引擎,比Python自带的解析器更快更稳定。
02. 把HTML变成“可操作”的对象
上一课我们拿到了`response.text`(HTML源码),现在把它交给BeautifulSoup处理。
先用一个简单的HTML例子理解基本操作:
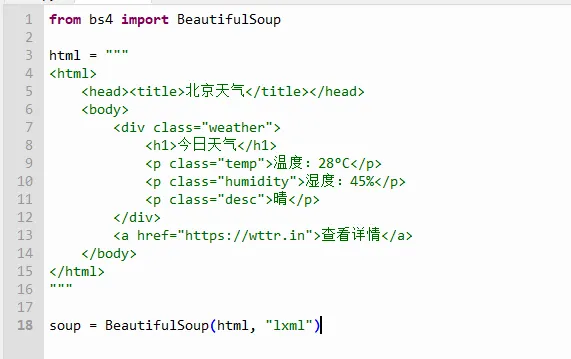
现在`soup` 就是一个可以“导航”的HTML对象了。
03. 提取标签内容:`.find()` 和 `.find_all()`
3.1 查找单个标签(`find`)
把下面红色圈起来的这一段代码加到上面代码的末尾,
每行代码后面都有注释,如下图示:
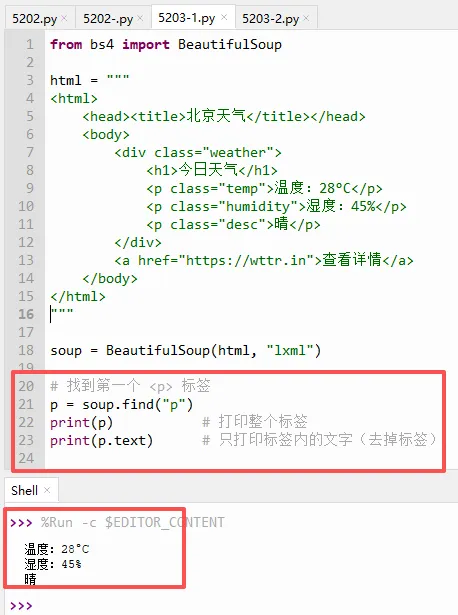
运行结果:
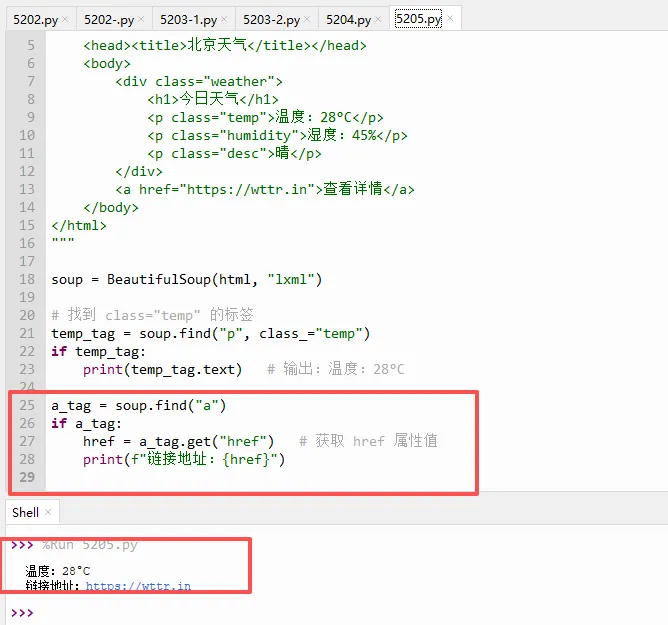
温度:28°C
湿度:45%
晴
04. 按class查找(实战中最常用)
实际网页中,你需要的信息通常藏在特定的class里。比如天气的温度可能藏在 `class="temp"` 里。
现在把下面圈起来这一段代码替换上面3.2的代码,
如下图示,不懂的可以看代码后面的注释,
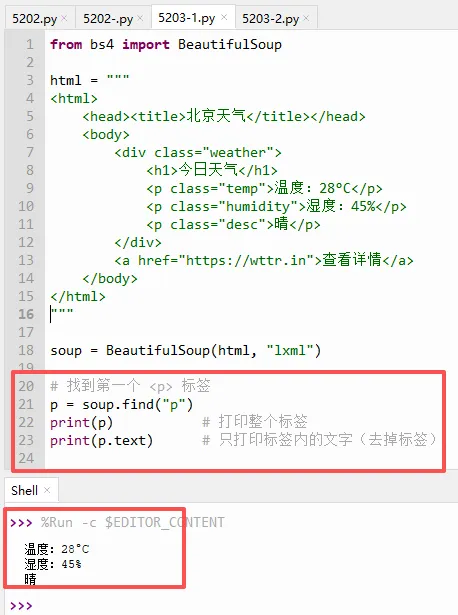
注意:`class_` 后面有下划线,因为 `class` 是Python关键字,不能直接作为参数名。
05. 提取标签属性(如链接地址)
现在把下面圈起来这一段代码放到上面04代码的末尾,如下图示,看看运行后的效果:
06. 实战:爬取真实天气预报
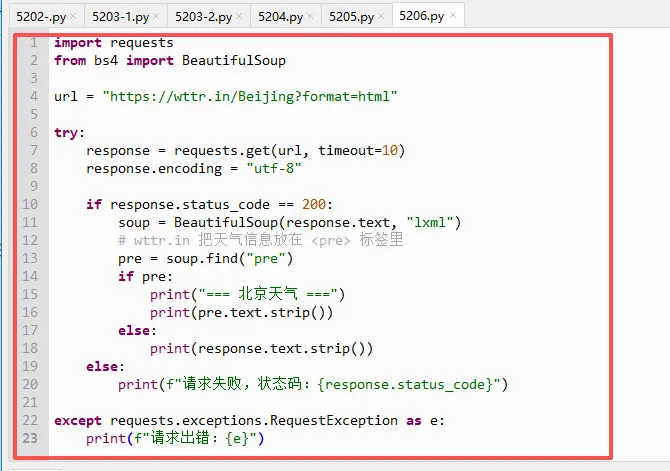
现在我们把`requests`(上一课)和 `BeautifulSoup`(本节课)结合起来,爬取真实的天气数据。
选择wttr.in 作为数据源:它是一个免费的天气服务,不需要申请API Key,非常适合学习。
方式一:用 BeautifulSoup 解析 HTML 页面
方式二:用 JSON 格式(更稳定,不需要解析HTML)
很多网站(包括wttr.in)提供JSON格式的数据,解析起来比HTML更可靠。
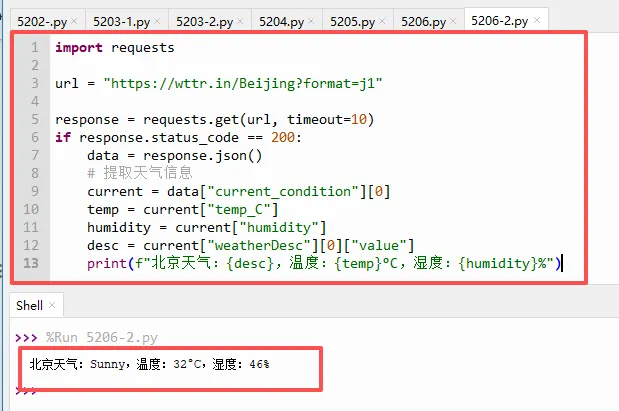
运行结果:
北京天气:晴,温度:28°C,湿度:45%
解释:
`response.json()`:将JSON格式的响应转换为Python字典。
`data["current_condition"][0]`:获取当前天气数据(列表的第一个元素)。
`weatherDesc[0]["value"]`:天气描述(如“晴”“多云”)。
注意:不同网站返回的JSON结构不同,需要查看API文档或打印 `data` 来确认字段名。
07. 两种方式对比
HTML解析(BeautifulSoup):适合展示美观的文本,灵活,页面结构可能变化,内容少、结构固定的页面。
JSON解析:数据直接可用,稳定可靠,输出需要自己排版,获取数据做进一步处理。
建议:如果网站提供JSON接口,优先用JSON;如果只有HTML,再用BeautifulSoup。
08. 课后小挑战
挑战1:爬取你所在城市的天气
把`Beijing` 换成你所在城市的英文名(如 `Shanghai`、`Guangzhou`),用JSON方式获取天气。
挑战2:自己解析一个网页
找一个包含新闻标题或文章列表的网页,用`soup.find_all()` 提取所有标题。
09.今天学到了什么
`BeautifulSoup(html, "lxml")`:创建解析器。
`soup.find("标签")`:查找第一个匹配的标签。
`soup.find_all("标签")`:查找所有匹配的标签,返回列表。
`soup.find("标签", class_="类名")`:按class查找。
`tag.text`:提取标签内的纯文本。
`tag.get("属性名")`:提取标签的属性值。
`response.json()`:将JSON格式响应转为Python字典(更稳定可靠)。
下一节课我们来学习:数据清洗与存储——把爬到的天气数据整理成表格,存到CSV文件里,方便以后查看。
————热门推荐————
自学编程第7课:turtle画图入门(画正方形五角形三角形)
自学编程第一步:安装Python和Thonny(零基础图文教程)
(本系列教程每天更新,欢迎关注收藏)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python变量 简单易懂不弯弯绕绕
- Python实战Demo大揭秘:从零开始的5个救命级问答
- 部署一个 Python 应用有多麻烦?从 SSH 到 systemd 的部署
- 主力在撤离还是建仓?我用Python扒掉了“资金流向”的遮羞布!(附全套源码)
- Linux 定时任务实战让服务器在凌晨两点自动帮你干活
- OpenAI 刚买下 Python 顶流工具,作者却说:AI PR 正在拖垮开源社区
- Linux 基金会加持的开源 AI Agent,48K Stars 日涨 700
- 吃透鸟哥Linux基础:进程与服务,读懂系统运行的底层逻辑.docx
- Python async 到底什么时候快,我们测了 6 个场景
- 少儿编程Python 字符串入门:搞懂长度和索引,孩子轻松处理文字
