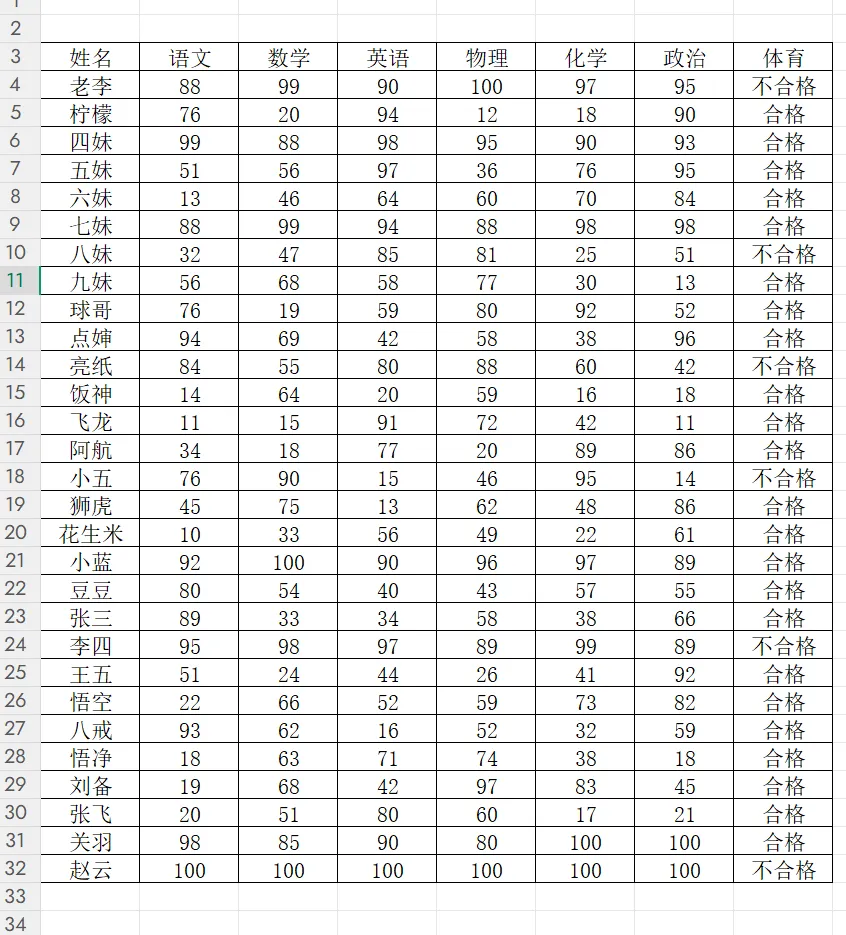
朋友发来一份 Excel:30 个学生,6 门主科 + 体育,要求"每科前 10 + 体育合格"才能评三好学生。
数据类似如下:
手动算?眼睛看瞎不算,关键是"并列第 10"这种边界情况处理起来还特别容易出错。
今天就用 Python 把它做成可复用的一键脚本,30 行搞定 👇
一、先把需求拆清楚
三好学生就两条硬条件:
① 每科成绩在班级前 10 名(6 门主科都要满足) ② 体育成绩合格
看起来简单,但有个隐藏的坑:第 10 名有并列怎么办?
举个真实场景👇
小蓝和李四政治都考 89 分,并列卡在第 10、第 11 名。
- 严格口径:只取前 10 个名额,那第 11 名的小蓝被淘汰
实际评选中,宽松口径更人性化——同分不同命会让家长投诉的。
二、技术选择
不需要数据库、不需要 Web 框架,pandas 一把梭:
- Series.rank():排名判定,核心 API
三、数据准备
Excel 结构长这样👇
姓名 语文 数学 英语 物理 化学 政治 体育
老李 88 99 90 100 97 95 不合格
四妹 99 88 98 95 90 93 合格
主科是数值,体育是"合格/不合格"文本。
四、核心实现
4.1 主逻辑:判断一个学生是不是三好学生
import pandas as pd
defjudge_sanhao(df):
"""在三好学生判定后,给 df 加一列 '三好学生',返回新 df。"""
subjects = ['语文', '数学', '英语', '物理', '化学', '政治']
# 用一个全是 True 的 Series 起步,每科 AND 一次
in_top10 = pd.Series(True, index=df.index)
for subj in subjects:
# 关键:method='min' + ascending=False
# 分数越高排名越小,并列时取最小名次(宽松口径)
rank = df[subj].rank(method='min', ascending=False)
in_top10 &= rank <= 10
pe_pass = df['体育'] == '合格'
df = df.copy()
df['三好学生'] = in_top10 & pe_pass
return df
4.2 入口
defmain():
df = pd.read_excel('students.xlsx')
result = judge_sanhao(df)
sanhao = result[result['三好学生']]['姓名'].tolist()
print(f'三好学生名单(共 {len(sanhao)} 人):')
for i, name in enumerate(sanhao, 1):
print(f' {i:>2}. {name}')
result.to_excel('students_result.xlsx', index=False)
if __name__ == '__main__':
main()
4.3 跑出来长这样
三好学生名单(共 4 人):
1. 四妹
2. 七妹
3. 小蓝
4. 关羽
五、关键技术点:pandas rank() 的 4 种 method
这个 API 是这次项目的灵魂,单独拎出来讲👇
df['score'].rank(method='?', ascending=False)
4 种 method 对比:
- 'average':并列取平均名次(统计学分析常用)
举个例子更直观。成绩 [100, 90, 90, 80],从高到低排:
- average → [1, 2.5, 2.5, 4]
我们的"宽松口径" = min:两个 89 分都给第 10 名,而不是一个第 10 一个第 11。
六、可视化验证:每科名次表
业务脚本光跑出名单不够,最好再把"每科名次"也打出来,方便核对边界 case:
defshow_rank_table(df):
subjects = ['语文', '数学', '英语', '物理', '化学', '政治']
rank_df = df[['姓名']].copy()
for subj in subjects:
rank_df[f'{subj}_名次'] = df[subj].rank(method='min', ascending=False).astype(int)
rank_df[subj] = df[subj]
rank_df['体育'] = df['体育']
return rank_df
跑一下就能看到谁卡在边界👇
姓名 语文 数学 英语 物理 化学 政治 体育
关羽 3 8 8 10 1 1 合格
小蓝 7 1 8 4 5 10 合格
李四 4 5 3 6 3 10 不合格
一眼就能看到"小蓝 vs 李四"这个边界 case:分数相同、排名相同,但体育一合格一不合格,命运就分开了。
七、拓展:换需求怎么办?
把"评选规则"参数化,就能复用到其他场景:
defjudge(df, subjects, top_n, pass_col, pass_value):
in_top = pd.Series(True, index=df.index)
for subj in subjects:
rank = df[subj].rank(method='min', ascending=False)
in_top &= rank <= top_n
return in_top & (df[pass_col] == pass_value)
# 例子 1:每科前 5 + 体育合格 = 优秀学生
df['优秀学生'] = judge(df, subjects, top_n=5, pass_col='体育', pass_value='合格')
# 例子 2:单科排名(数学竞赛选拔)
df['数学能手'] = judge(df, ['数学'], top_n=3, pass_col='体育', pass_value='合格')
这就是把"业务规则"和"技术实现"分离的好处——下学期改规则只改一行参数。
八、完整代码
把上面所有逻辑收个尾,30 行不到:
import pandas as pd
defjudge_sanhao(df):
subjects = ['语文', '数学', '英语', '物理', '化学', '政治']
in_top10 = pd.Series(True, index=df.index)
for subj in subjects:
rank = df[subj].rank(method='min', ascending=False)
in_top10 &= rank <= 10
df = df.copy()
df['三好学生'] = in_top10 & (df['体育'] == '合格')
return df
defmain():
df = pd.read_excel('students.xlsx')
result = judge_sanhao(df)
sanhao = result[result['三好学生']]['姓名'].tolist()
print(f'三好学生名单(共 {len(sanhao)} 人):')
for i, name in enumerate(sanhao, 1):
print(f' {i:>2}. {name}')
result.to_excel('students_result.xlsx', index=False)
if __name__ == '__main__':
main()
这个项目技术含量不高,但它是数据分析的典型缩影:
- 业务规则 → 逻辑拆分:把"每科前 10"拆成"每科独立排名 + AND 组合"
- API 选型:
rank(method='min') 一行顶十行 if-else - 边界 case 显式化:并列、口径分歧,必须在代码里讲清楚
下次遇到类似的"按分数/数量排名 + 多条件筛选"的需求(比如奖学金评选、绩效评级、KPI 达成),都可以拿这个模板改一改直接用。
— END —
如果觉得有帮助,欢迎点赞 + 在看 👏 有想看的主题,评论区留言,我安排 👇
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
