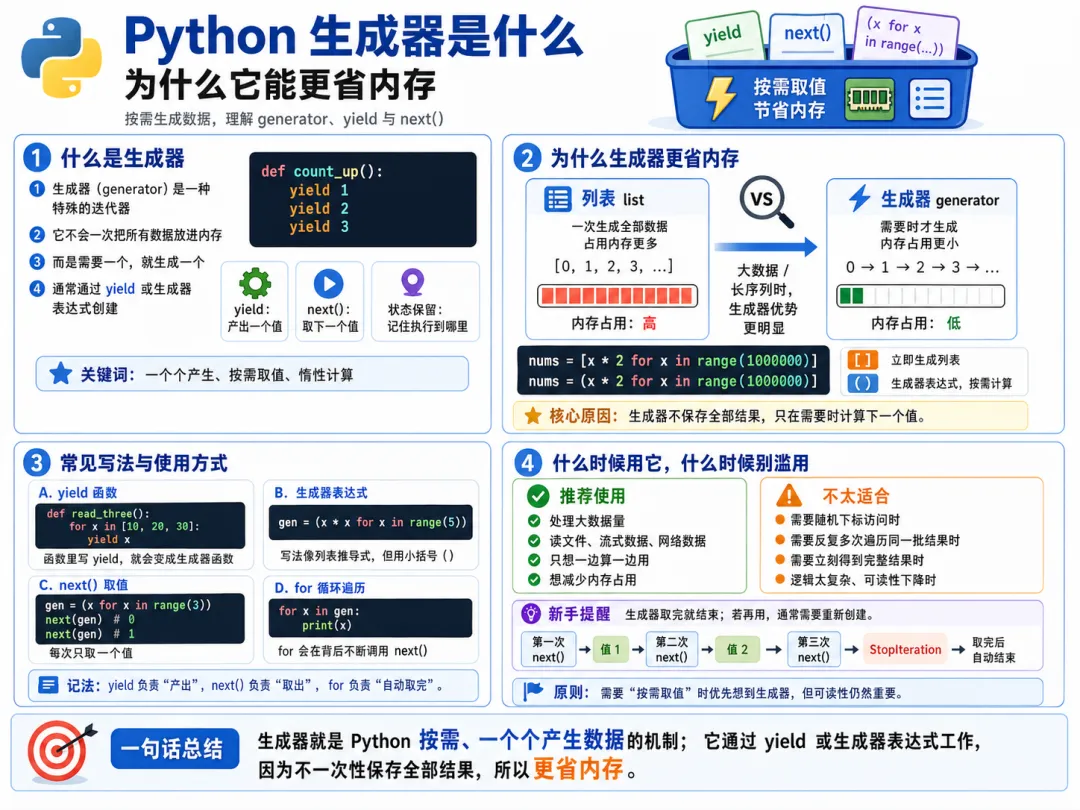
上一章我们已经把迭代器讲清楚了。你应该已经知道,for 循环背后并不是在神奇地自动遍历,而是依赖一种一个一个取值的机制。也正因为前面已经把迭代器想明白了,所以这一章就特别自然了。
因为生成器,本质上和迭代器关系非常近。 你甚至可以先粗暴地理解成一句话:
生成器,就是一种更方便产生迭代器的方式。
很多人第一次听到生成器,会先被另一个说法吸引:
生成器更省内存。
这句话没错,但如果你只是把它当成一句结论去背,很容易停留在表面。真正重要的是你要想明白:
为什么它更省内存 它到底省在哪里 它和列表这种一次性把数据都装出来的东西,到底区别是什么
这一章,我们就把这件事彻底讲透。
一、先从最容易理解的对比开始:列表为什么有时候会“太实在”
比如你想生成 1 到 10 的平方数列表,前面你已经会写很多种方式了。
最普通的写法:
result = []for i in range(1, 11): result.append(i * i)print(result)
或者用列表推导式:
result = [i * i for i in range(1, 11)]print(result)
输出都是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
这当然很好。 而且在数据量不大时,这种写法特别直观。
但你现在要开始意识到一个问题:
列表会一次性把所有结果都算出来,并且全部放进内存里。
比如上面的例子,只有 10 个数,这当然不算什么。 可如果你不是要 10 个,而是要 100 万个、1000 万个,问题就完全不一样了。
也就是说,列表的特点是:
先全算出来 再全装起来 然后你再慢慢用
这在很多场景下没有问题。 但在一些大数据量场景下,就会显得有点“太实在了”。
二、什么叫生成器,先给最直白的理解
你现在可以先把生成器理解成这样:
它不是一上来把所有结果都准备好,而是你要一个,它才给你一个。
这句话特别关键。
如果列表像一次性端上一整桌菜, 那生成器更像厨房里现做现上的模式。
你不需要它一次把所有菜都摆满桌子。 你只需要告诉它:先来一道。 吃完再来下一道。
这就是生成器最核心的味道:
延迟生成,按需提供。
而这,也正是它更省内存的根本原因。
三、先看一个最简单的生成器写法:生成器表达式
前面你已经见过列表推导式:
result = [i * i for i in range(1, 11)]
那生成器表达式长得非常像,只是把方括号换成圆括号:
result = (i * i for i in range(1, 11))print(result)
你会发现,输出结果不再是一个列表,而会是类似这样的东西:
<generator object ...>
这说明什么?
说明它不是把最终结果都直接给你了。 它给你的是一个生成器对象。
也就是说,这时候 result 里面装的,不是一堆已经算好的平方数, 而是一个“可以在需要时,一个一个产出平方数”的生成器。
你可以把它理解成:
它记住了生成规则,但还没有把所有结果一次性做完。
四、为什么只换个括号,意义会差这么大
这是你一定要想透的地方。
看下面这两句:
a = [i * i for i in range(1, 11)]b = (i * i for i in range(1, 11))
a 是列表。b 是生成器。
它们表面上写法只差了一个括号。 但行为差别非常大。
列表做的是:
马上把 10 个结果都算完 全部存到内存里
生成器做的是:
先把“以后该怎么生成这些值”的规则保存起来 但暂时不全算 等你真要时,再一个个给你
所以这不是语法花样,而是计算时机发生了变化。
这也是为什么生成器和列表看着像亲戚,但本质上不是一回事。
五、生成器为什么更省内存
现在终于可以正式回答这个标题问题了。
因为它不会一次性把所有结果都存下来。
举个特别直白的例子。
如果你写:
nums = [i for i in range(1000000)]
那程序会真的创建一个装着 100 万个整数的列表。 这些数据都会占用内存。
但如果你写:
nums = (i for i in range(1000000))
那程序不会立刻准备好这 100 万个整数。 它只是创建了一个生成器对象,告诉你:
规则在这里 你要的时候我再一个一个给
这时候内存压力会小很多。 因为它不是“结果全在手里”,而是“按需生产”。
所以一句特别准确的话是:
生成器省内存,不是因为它会魔法压缩数据,而是因为它根本不急着把所有数据都存进来。
六、那生成器里的值什么时候才真的被算出来
答案是:
在你真正去取的时候。
比如:
gen = (i * i for i in range(1, 6))
此时生成器已经创建了。 但平方值通常还没有全部一口气算出来。
你只有在真正调用 next(),或者放进 for 里遍历时,它才会一个一个往外产出结果。
比如:
gen = (i * i for i in range(1, 6))print(next(gen))print(next(gen))print(next(gen))
输出结果:
149
这就很有代表性了。
它不是先准备 [1, 4, 9, 16, 25] 再让你取。 而是每次你要一个,它才给你一个。
这就是延迟计算。
七、你现在应该发现:生成器和迭代器关系特别近
没错,这正是上一章铺垫的价值。
你已经知道:
迭代器是一个一个往外给值,并且记住当前位置的对象。 而生成器正好也是这样。
所以从行为上看,生成器本身就是一种迭代器。
你可以直接验证:
gen = (i * i for i in range(1, 6))print(next(gen))print(next(gen))
它和上一章里的迭代器几乎是同一种使用方式。
也就是说,生成器不是绕开迭代器的另一套世界。 它其实就是迭代器家族里特别重要的一种成员。
所以你现在可以把关系记成这样:
可迭代对象 可以生成迭代器
生成器 本身就是迭代器的一种特殊形式
这个关系一旦清楚,后面学 yield 会轻松很多。
八、生成器也会“走到哪算到哪”
这是生成器特别重要的一个特征。
看下面这个例子:
gen = (i * i for i in range(1, 6))print(next(gen))print(next(gen))
第一次拿到 1。 第二次拿到 4。
注意,第二次不是又从头开始。 为什么?
因为生成器和迭代器一样,会记住当前进度。
你可以把它理解成:
第一次已经走到第一个值 第二次自然从第二个值继续 不会自动回头重来
这也是为什么生成器特别适合处理大数据流。 因为它不需要来回反复把所有内容端出来,它只负责顺着往前走。
九、那生成器能不能遍历很多次
这个问题和上一章迭代器的特性是连着的。
比如:
gen = (i * i for i in range(1, 6))for x in gen: print(x)for x in gen: print(x)
你通常会发现,第二个循环没有内容了。
为什么?
因为生成器也是会被消耗的。 它和已经走过的迭代器一样,走完就走完了。
所以这里一定要建立一个非常清楚的意识:
生成器不是“随时都能无限重放的数据容器”,它更像一个一次性的出值过程。
如果你需要反复遍历同一批结果,而且数据量也不大,那列表往往更方便。 如果你只需要顺着处理一遍,而且数据可能很多,那生成器就特别合适。
这就是它们的边界。
十、列表和生成器,到底该怎么理解它们的差别
你现在可以把它们放在一起比较了。
列表更像:
已经准备好的成品仓库 东西都在那里 随时能按下标取 能反复看 但会占更多内存
生成器更像:
按订单逐个生产的流水线 你要一个给一个 不急着全部准备 更省内存 但通常不能随意回头重来
所以两者没有谁绝对更高级。 关键是场景不同。
如果数据量小,而且你要频繁访问、反复使用、按下标定位,那列表很自然。 如果数据量大,或者你只是顺着处理一次,那生成器会很有优势。
十一、先看一个特别能体现差别的小案例
比如你只想取前 3 个平方数。
用列表写:
nums = [i * i for i in range(1, 1000001)]print(nums[0])print(nums[1])print(nums[2])
这当然能做。 但它在你取前 3 个值之前,已经把后面一大堆值都提前算完并存好了。
而用生成器:
gen = (i * i for i in range(1, 1000001))print(next(gen))print(next(gen))print(next(gen))
这里你只取前 3 个值,它也只需要生产前 3 个值。 后面的内容暂时根本不急着算。
这时候你就会真正体会到:
生成器的省,不是少存一点,而是很多时候根本没必要先全存。
这就是它的核心价值。
十二、为什么说生成器特别适合“大量数据、顺序处理”
因为它的工作模式本来就特别适合这一类需求。
比如:
读取一个大文件,一行一行处理 处理一个很大的数字序列 批量生成测试数据 流水式处理网络返回内容 逐步解析日志记录
这些场景有一个共同点:
数据可能很多 你并不需要一次性全部握在手里 而是更关心“来一个,处理一个”
这时候生成器就特别合适。
所以你不要把它理解成一个单纯为了省内存而存在的技术点。 更准确地说,它是一种特别适合“流式处理”的思路。
十三、生成器表达式和列表推导式到底怎么选
这又是一个非常现实的问题。
你前面已经会写:
[x * x for x in nums]
现在又学会了:
(x * x for x in nums)
那以后怎么选?
可以先用一个很实用的判断法。
如果你需要的就是一个真正的列表结果,比如:
后面要频繁访问 要按下标取 要多次遍历 数据量也不大
那列表推导式通常更合适。
如果你只是想顺着处理,或者数据量可能比较大,不想一次性全占住内存,那生成器表达式通常更合适。
也就是说:
方括号更像“立即交付完整结果”。圆括号更像“先给你一个按需生产的过程”。
这组感觉一定要建立起来。
十四、生成器表达式并不是生成器的全部
这一点要提前提醒你。
这一章我们先讲最直观的生成器表达式:
(i * i for i in range(1, 6))
这很适合作为入门。 因为它几乎就是列表推导式换个括号,特别容易理解。
但生成器真正更核心、更强大的形式,其实和 yield 有关。 而这正是下一章的重点。
你现在先不要着急。 这一章的任务,是先把“什么叫按需生成”“为什么它更省内存”真正想明白。 等这个直觉稳了,下一章讲 yield 时,你就不会悬空。
十五、做一个特别接地气的小例子:逐个处理文件行
你前面已经知道,文件对象本身就可以一行一行遍历。 这其实本来就带有生成器那种味道。
比如:
with open('data.txt', 'r', encoding='utf-8') as f:for line in f: print(line.strip())
你不会一上来就把整个文件所有行都先摊平,然后再慢慢用。 而是文件对象一行一行给你,for 一行一行处理。
生成器的思路,其实和这个特别像。
所以你可以这样理解:
生成器把“按需取值”这种迭代思路,做成了一种更通用的能力。
它不是只能用在文件上。 很多自定义数据流,你也都可以做成这种风格。
十六、生成器为什么特别适合做数据管道
这个说法你现在先有个印象就行。
所谓数据管道,简单说就是:
前面来一点数据 中间处理一下 后面再继续传下去
这个过程中,如果你每一步都把所有数据先堆成一个大列表,内存就会比较重。 但如果每一步都按生成器的方式,一边来一边处理,就会更轻、更自然。
所以生成器在很多稍微偏进阶一点的数据处理和异步处理场景里都很常见。
你现在不用立刻写复杂例子,但至少要知道:
生成器的思路特别适合连续流式处理。
十七、一个常见误区:以为生成器只是“更省内存的列表”
这个说法只对一半。
它确实常常更省内存。 但如果你只把它理解成“压缩版列表”,就会忽略它真正的本质。
更准确地说,生成器不是把列表变小了, 而是把“先全部准备好”这个思路,变成了“需要时再产生”。
所以生成器不是“缩水列表”, 而是另一种数据产生方式。
这个理解特别关键。 因为后面你学 yield 时,会更明显看到:它根本不是在模拟列表,而是在定义一个逐步产出值的过程。
十八、什么时候特别适合考虑生成器
你现在可以先记住下面这几类高频场景:
数据量可能很大 你只打算顺着处理一遍 不需要按下标随机访问 不需要反复遍历同一批结果 更关心按需生成,而不是立刻拿到完整容器
比如:
大范围数字序列处理 日志逐行分析 文件逐块读取 批量生成测试数据 流式数据处理
只要这种味道出现,脑子里就可以开始想到生成器。
十九、本章小练习
你可以做三个特别适合巩固的练习。
练习 1 分别用列表推导式和生成器表达式,生成 1 到 10 的平方数,并观察它们打印出来的区别。
参考思路:
list_result = [i * i for i in range(1, 11)]gen_result = (i * i for i in range(1, 11))print(list_result)print(gen_result)
练习 2 创建一个生成器表达式,然后用 next() 连续取 3 次值。
参考思路:
gen = (i * 2for i in range(1, 6))print(next(gen))print(next(gen))print(next(gen))
练习 3 把一个生成器放进 for 循环里遍历完,再尝试第二次遍历,观察结果。
这个练习非常重要。 因为它能帮你真正理解“生成器会被消耗”这件事。
二十、本章总结
这一章最重要的,是把生成器的直觉真正建立起来。
生成器的核心不是一次性把所有结果准备好,而是按需一个一个生成。 它和迭代器关系非常紧密,本身就是一种可以逐个提供值的对象。 生成器表达式的写法和列表推导式很像,只是把方括号换成圆括号。 列表更像一次性交付完整结果,生成器更像按需生产的过程。 生成器之所以更省内存,不是因为压缩得更厉害,而是因为很多时候根本不急着把所有数据都存下来。 它特别适合大数据量、顺序处理、只遍历一次的场景。
下一章我们继续往前走,进入生成器真正的核心:097|yield 关键字入门:理解生成器的核心。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
