2 亿美元。
这是全球验证码破解服务的市场规模。Cloudflare Turnstile、hCaptcha、reCaptcha……每一层验证码背后,都站着付费 API、代理池和解封服务商。
2026 年 3 月,X 上一条帖子直接给这个行业判了死刑:
"The CAPTCHA solving industry built a $200M business on a problem this repo just made irrelevant."
「验证码破解行业靠一个问题建立了 2 亿美元的生意,而这个仓库刚刚让这个问题变得毫无意义。」
他说的是一个叫Scrapling的 Python 开源项目。GitHub 上挂着66k Star——比大多数人更熟悉的 Scrapy(55k)还多。
这个判断有没有过头?往下看。
66k Star 从哪来的
▲ Scrapling GitHub 仓库,66k Star,README 开头写着"bypass Cloudflare Turnstile out of the box"
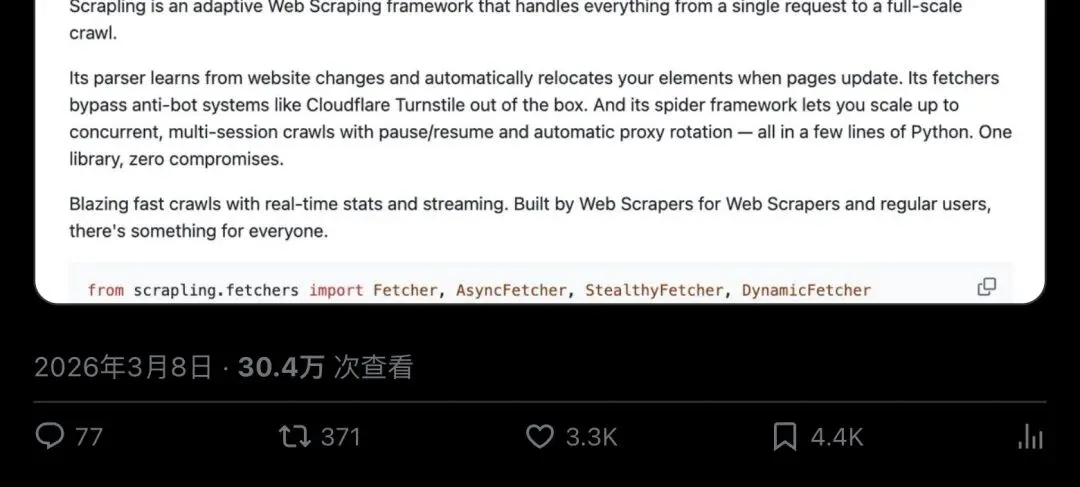
2024 年 10 月,开发者 Karim Shoair(GitHub ID:D4Vinci)发布了 Scrapling v0.1,定位是一个更快的 HTML 解析器。
2025 年,项目大重构:反检测 fetcher、自适应选择器、MCP 接口陆续上线。到 2025 年 10 月独立评测出来时,大约 7000 Star。
然后 X 上的开发者社区注意到了它。
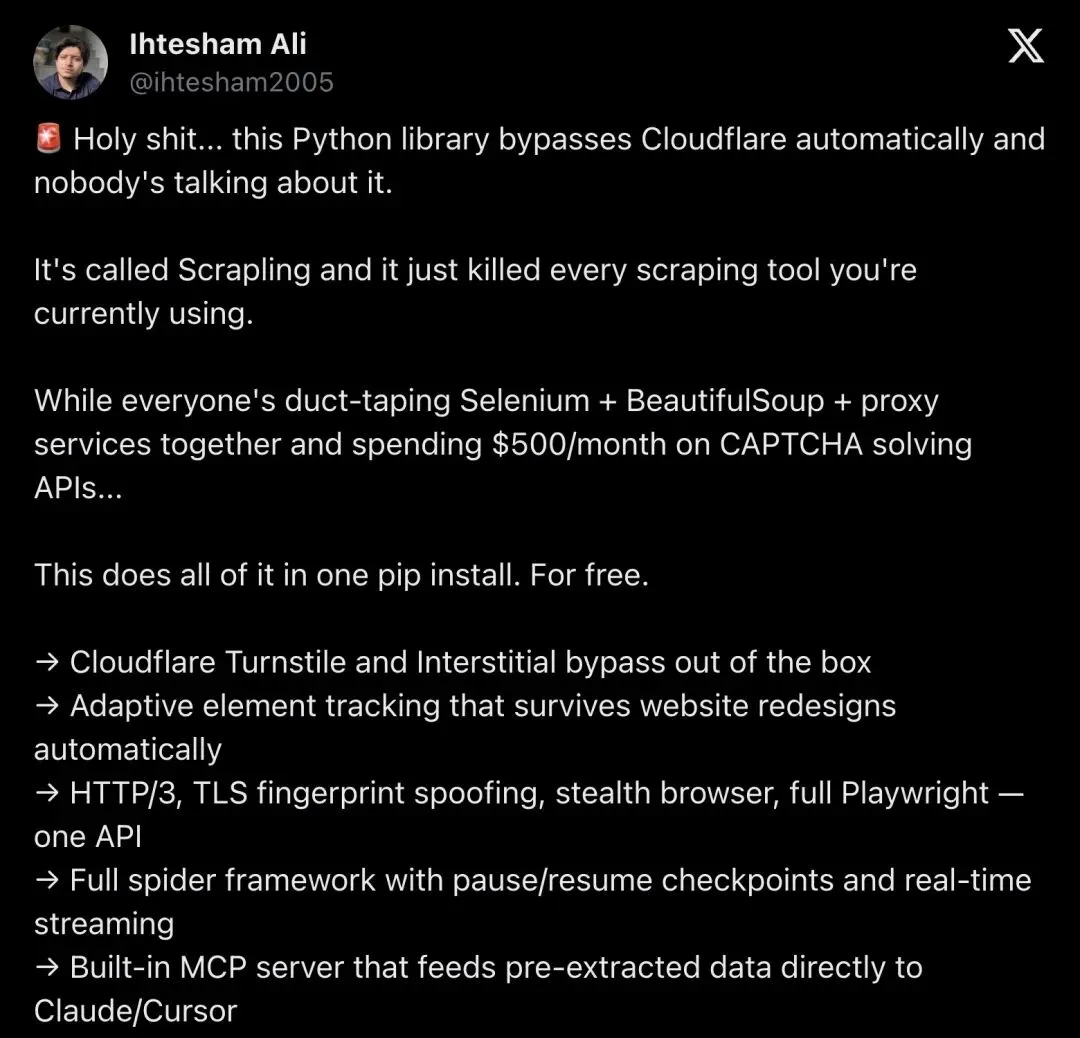
@ihtesham2005 发了一条帖,开头就是"Holy shit"——3300 赞,30 万浏览:
"Holy shit... this Python library bypasses Cloudflare automatically and nobody's talking about it."
「这个 Python 库能自动绕过 Cloudflare,居然没人讨论。」
▲ @ihtesham2005 的帖子,列出 Scrapling 核心能力,末尾直接抛出"2 亿美元产业被消灭"的判断
帖子列了 Cloudflare 绕过、自适应选择器、784 倍解析速度、MCP 接入、100% 开源,最后一句扔出了那个 2 亿美元的判断。
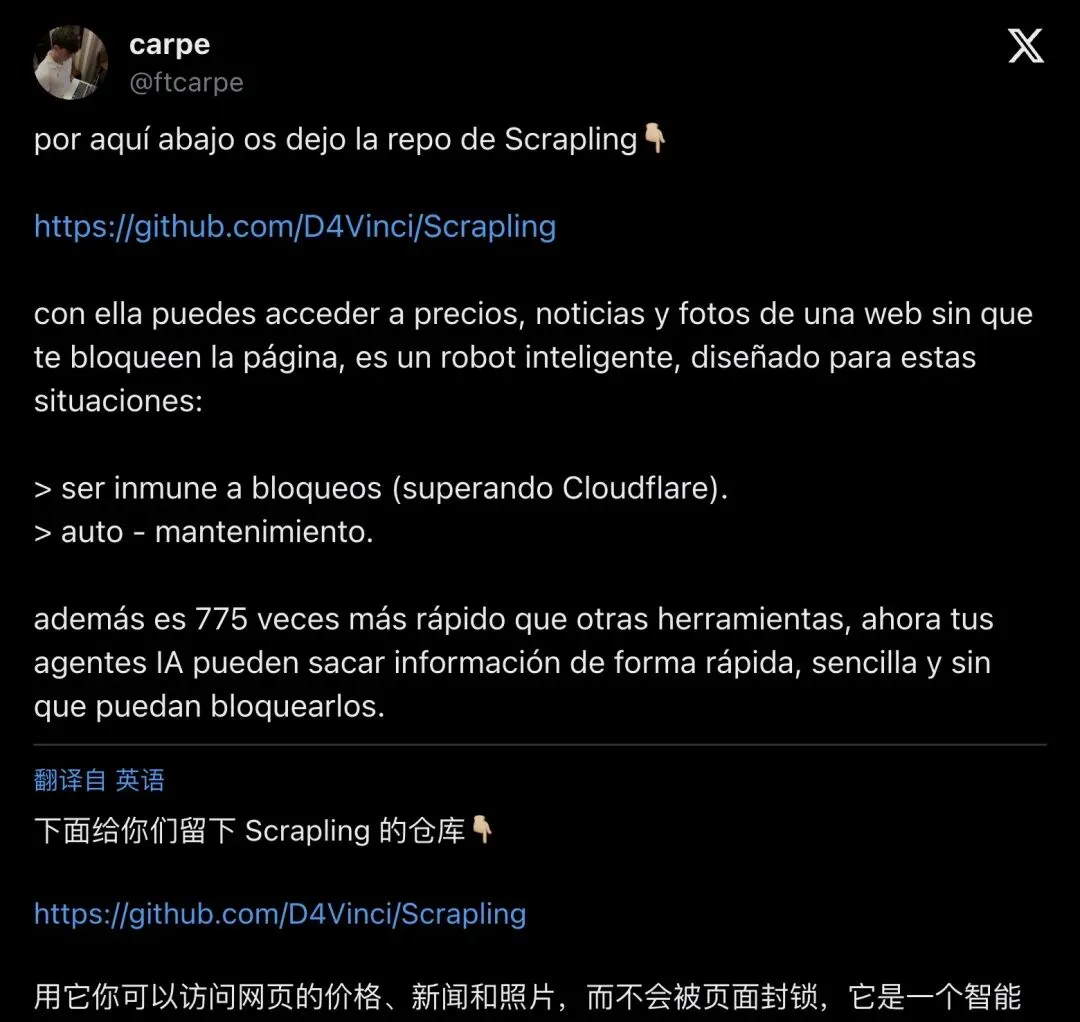
6 月 24 日,西班牙开发者 @ftcarpe 又贴了一次 GitHub 链接:
"con ella puedes acceder a precios, noticias y fotos de una web sin que te bloqueen la página"
「用它你可以访问网页的价格、新闻和照片,页面不会封你。」
▲ @ftcarpe 的西班牙语安利帖,107 赞,5.5k 浏览
从 7k 到 66k,8 个月,将近 10 倍增长。PyPI 上 0.4 系列密集发布,Docker 镜像齐全,Discord 社区活跃,21+ 贡献者。赞助商全是代理和解封服务商——ColdProxy、Evomi、NodeMaven——这些公司愿意掏钱赞助,侧面说明有大量用户在生产环境跑 Scrapling。
怎么穿透 Cloudflare
Scrapling 内置三种 fetcher,分别应对不同级别的反爬。
Fetcher——纯 HTTP 请求。TLS 指纹伪造(可以把请求伪装成 Chrome 发出的),自动加隐身 header,支持 HTTP/3。应对静态页面和轻度动态页面,速度最快。
StealthyFetcher——核心武器。底层基于魔改版 Camoufox(Firefox 系浏览器),专门处理 Cloudflare Turnstile 和 Interstitial 验证。Canvas 噪声注入、Headless 检测补丁、WebRTC 泄漏屏蔽、DNS-over-HTTPS,全部内置。代码写出来是这样的:
from scrapling.fetchers import StealthyFetcher page = StealthyFetcher.fetch( 'https://nopecha.com/demo/cloudflare', solve_cloudflare=True, headless=True ) print(page.status) # 200
solve_cloudflare=True,一个参数,Cloudflare 验证页直接返回 200。
DynamicFetcher——完整 Playwright Chromium 实例。支持真 Chrome 内核、CDP 连接、资源拦截、广告屏蔽、网络空闲等待。最重型的 SPA 页面用这个。
三种 fetcher 都带持久 Cookie、并发标签池(max_pages 控制数量)、代理轮换(内置 ProxyRotator)。选对工具,电商价格、新闻正文、图片链接——一次请求就能拿到。
这个说法有独立验证。评测人 Antonello Zanini 在 Substack 上用同样的 StealthyFetcher 模式抓取 scrapingcourse.com 的 Cloudflare 挑战页,页面返回了确认信息:
"You bypassed the Cloudflare challenge! :D"
▲ The Web Scraping Club 的实操评测,对 Scrapling 的抓取、解析、反爬能力逐项验证
网站改版了,选择器怎么办
爬虫工程师的日常噩梦:花半天写好的 CSS 选择器,网站一改版,class 名全换,所有逻辑报废。
Scrapling 的应对方案叫自适应选择器。
第一次抓取时,auto_save=True会把目标元素的完整特征存下来——标签类型、属性列表、文本内容、父子关系、在 DOM 树中的深度。这些特征构成了元素的"指纹"。
之后网站改版了,class 名变了、DOM 结构调了,用adaptive=True重新抓取。引擎会在新页面里搜索指纹最相似的元素,自动定位到目标。
# 第一次抓取:保存元素指纹 page.css('.product-price', auto_save=True) # 网站改版后:自动定位 page.css('.product-price', adaptive=True)
还有find_similar()、find_by_text、find_by_regex作为后备搜索手段。官方基准显示,这种相似性搜索比同类工具 AutoScraper 快5.2 倍。
对于需要长期运行的任务——电商价格监控、新闻标题聚合——这个能力直接砍掉了最大的维护成本。平台隔三差五改前端,选择器照样能追踪到价格标签。
这也是源帖里那个西班牙语词"auto-mantenimiento"(自动维护)的技术根源。
784 倍速度差距怎么来的
官方基准测试,测试对象是 5000 个嵌套元素的文本提取:
| | |
|---|
| Scrapling | 2.02 ms | 1.0x |
| | |
| | |
| | |
| BS4 + lxml | 1584 ms | ~784x |
| | |
BS4 + lxml 是大多数 Python 爬虫教程的标配。Scrapling 在解析层快了 784 倍。帖文说的"775 倍"取自 MechanicalSoup 对比,取了整数。
但这个数字有框定条件:只衡量了 HTML 解析环节。真实爬取中,网络延迟、JS 渲染、并发调度才是主要时间消耗。启动 StealthyFetcher 跑一个完整浏览器实例去过 Cloudflare,跟纯文本解析完全不在同一量级。
解析快的实际价值在于:AI agent 高频调用时,解析延迟从秒级降到毫秒级;批量处理时,解析层永远不会成为瓶颈。这些优势实打实存在,但"775 倍"拿来做整体宣传,确实带有选择性放大的成分。
AI 代理的网页入口
Scrapling 做了一步对 AI 开发者特别有吸引力的设计:MCP Server。
pip install "scrapling[ai]"
装上之后,Claude、Cursor 这类 AI 工具可以直接调用 Scrapling 的 get、fetch、stealthy_fetch 能力。
关键设计在于预过滤:在把页面内容传给大模型之前,先用 CSS 选择器把页面切干净,只传目标区域。整页 HTML 扔给 LLM,大量 token 浪费在导航栏、广告和页脚上;Scrapling 的 MCP 层只传.product、.article-body这样的片段,token 消耗降了几个数量级。
▲ @agenticgirl 的帖子:Scrapling 是 AI agent 的终极骨架(ultimate backbone),提供省 token 的网页访问能力
对做 AI agent 产品的团队来说,这意味着让 agent "看网页"的成本大幅下降——看价格、看新闻、看图片,而且大部分场景下不会被反爬系统拦住。
别急,先看它的边界
Cloudflare 也在升级。今天能绕过的验证方式,明天可能就被针对性封堵。赞助商名单里全是代理和解封服务商,说明在大规模生产场景中,代理池仍然是刚需,光靠 Scrapling 本身不够。
浏览器实例吃资源。StealthyFetcher 开一个页面没问题,同时跑几百个并发就得掂量服务器配置了。784 倍的速度优势在解析层;跑浏览器的时候,这个优势会被摊薄。
法律边界需要自行把关。项目 README 反复强调"教育和研究用途"。用它抓竞品价格做监控、抓新闻做聚合分发,都需要遵守目标网站的 ToS 和当地法律。
封装带来的取舍。有开发者指出,对高度定制化的爬取流程,直接用 Playwright 加 Camoufox 可能有更高的可控性。Scrapling 降低了门槛,也牺牲了一部分底层灵活度。
这场攻防赛还会继续
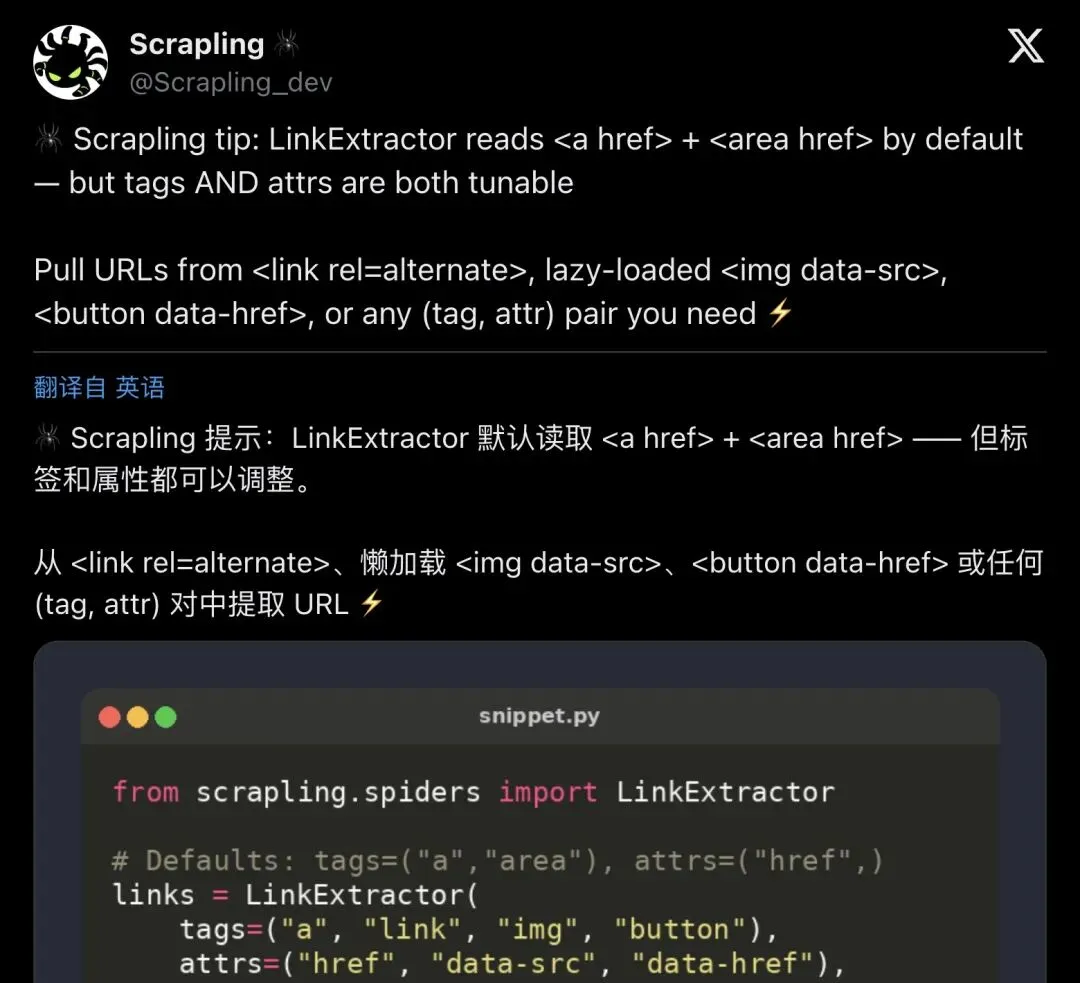
▲ @Scrapling_dev 官方贴士:LinkExtractor 可配置任意标签和属性,用于抓取懒加载图片和各类链接
回看 Scrapling 的演进路径——2024 年底的 v0.1 只是一个解析引擎,2025 年加入 fetcher 和自适应,2026 年推出异步 Spider 框架、代理轮换、MCP 接口——方向明确:从解析工具变成 AI 代理的网页访问层。
AI agent 需要"看"互联网,但互联网在用越来越复杂的手段阻止机器人。Scrapling 把"看"的能力打包成一条 pip install:隐身抓取 + 自愈选择器 + 预过滤。
66k Star 说明大量开发者看好这个方向。至于 Cloudflare 会不会针对性反制、自适应在极端场景下会不会失灵、大规模部署的稳定性如何——这些答案只能等真实生产流量来验证。
回到那个"2 亿美元产业被消灭"的判断——或许夸张了,但它指出了一个正在发生的趋势:开源工具正在蚕食付费反爬服务的市场空间。而 Scrapling,是目前这条赛道上跑得最快的选手之一。