上一章我们已经认识了生成器,知道它和列表最大的区别在于:
列表会一次性把结果都准备好。 生成器则是你要一个,它给一个。 也正因为这样,生成器往往更省内存,特别适合处理大量数据和顺序处理场景。
但上一章我们主要讲的是一种比较直观的写法:生成器表达式。
比如:
gen = (i * i for i in range(1, 6))
这种写法很好理解,因为它几乎就是列表推导式换了个括号。
可真正让生成器变得强大、灵活、值得单独拿出来讲的核心,不是圆括号本身,而是一个关键字:
yield
很多人第一次看到 yield,会觉得特别怪。 它既不像 return,也不像普通循环语句。 写在函数里以后,函数行为突然就不一样了。 于是就会冒出很多典型疑问:
yield 和 return 到底有什么区别 为什么函数里一出现 yield,就变成生成器了 它为什么能暂停,又为什么还能接着往下跑 到底什么时候应该用它
这一章,我们就把这些问题彻底讲清。
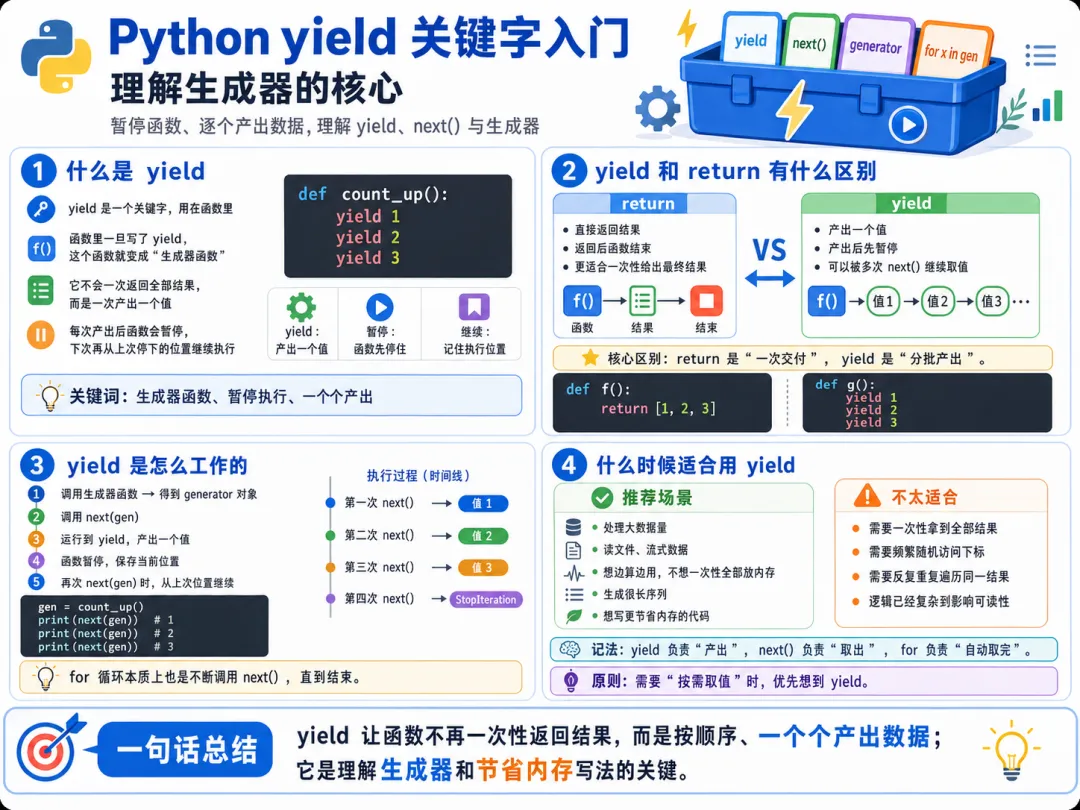
一、先说结论:yield 是生成器的核心开关
你先记一句最重要的话:
一个函数里只要出现了 yield,它通常就不再是普通函数,而会变成生成器函数。
注意这句话的重点不在“长得像函数”,而在“行为已经变了”。
比如你平时写普通函数:
defadd(a, b):return a + b
调用后立刻得到一个结果。
但如果你写:
deftest():yield1
这时它虽然看起来还是一个函数, 可你调用它时,拿到的通常不再是直接的值,而是一个生成器对象。
这就是 yield 最核心的影响。
二、先看一个最小例子
defsimple_gen():yield1yield2yield3g = simple_gen()print(g)
输出结果通常不会是 1、2、3, 而会是类似这样:
<generator object simple_gen at ...>
这说明什么?
说明函数并没有在你调用时,一口气把所有值都吐出来。 它只是返回了一个生成器对象。
那怎么真正取到里面的值?
可以用 next():
defsimple_gen():yield1yield2yield3g = simple_gen()print(next(g))print(next(g))print(next(g))
输出:
123
这时候你就会明显感觉到:
这个函数不是一次性执行完的。 它像是“走到一个 yield,先交一个值出来,然后暂停住”。
这就是生成器函数最关键的味道。
三、yield 和 return 的直觉区别是什么
这必须先讲清楚。
你可以先这样记:
return 是函数彻底结束,并把结果交出去。yield 是先交一个值出去,但函数并不真正结束,而是暂停在这里。
这个区别特别关键。
比如普通函数:
deffunc():return1return2
一旦执行到第一个 return 1,函数就结束了。 后面根本不会继续。
但如果是:
deffunc():yield1yield2
第一次取值时,交出 1,先暂停。 第二次再继续,从上次暂停的位置往下走,再交出 2。
这就是为什么 yield 看起来有点像“返回值”,但本质上又不是普通 return。
它更像是:
边执行,边分批交结果。
四、yield 到底是怎么“暂停”的
这是很多人第一次接触时最惊讶的地方。
先看这个例子:
defsimple_gen(): print('开始')yield1 print('继续')yield2 print('结束')
现在我们来一步步取值:
g = simple_gen()print(next(g))print(next(g))
输出结果通常会是:
开始1继续2
注意观察执行过程。
第一次 next(g)函数从头开始执行 先打印“开始” 然后遇到 yield 1把 1 交出去 函数暂停
第二次 next(g)不是从头重来 而是从上次 yield 1 后面继续 先打印“继续” 再遇到 yield 2把 2 交出去 再次暂停
这就说明,生成器函数内部不仅能产出值,还能记住自己执行到了哪里。
这其实和上一章讲的迭代器“记住当前位置”是一脉相承的。 只不过现在这个“位置”不只是数据位置,而是代码执行位置。
五、为什么说 yield 是理解生成器的核心
因为生成器表达式虽然方便,但它只能处理那种比较简单的场景。
比如:
(i * i for i in range(1, 6))
这种场景很适合用生成器表达式。 可一旦你的生成过程稍微复杂一点,比如:
中间有多步逻辑 有条件判断 有打印调试 有多次产出值 有状态变化
这时候,生成器表达式就不够用了。 而 yield 生成器函数就特别适合。
也就是说:
生成器表达式更像简写。yield 才是生成器真正完整的表达方式。
所以你如果真的想把生成器学明白,yield 这一关一定绕不过去。
六、现在可以把生成器函数翻译成人话了
比如下面这个函数:
defcount_up():yield1yield2yield3
你不要把它想成普通函数。 你可以把它翻译成:
这是一个“按顺序一个个提供值”的函数流程 第一次要值时给 1 第二次要值时给 2 第三次要值时给 3 然后结束
也就是说,生成器函数不是“一次算完一个最终答案”, 而是“定义了一段可逐步产出值的过程”。
这个理解非常重要。
七、yield 生成器函数和列表返回,到底差在哪
看两个对比例子。
写法一,返回列表:
defget_nums():return [1, 2, 3]
调用后:
result = get_nums()print(result)
输出:
[1, 2, 3]
这里是一口气把整个列表都返回了。
写法二,使用 yield:
defget_nums():yield1yield2yield3
调用后:
result = get_nums()print(result)
输出的是生成器对象,不是列表。
这说明:
前者是一次性交付完整结果 后者是交给你一个“可逐步取值的过程”
所以这两者不是“结果长得不一样”那么简单, 而是整个计算方式都不一样。
八、一个特别适合入门的例子:逐个生成平方数
defsquare_gen():for i in range(1, 6):yield i * ig = square_gen()print(next(g))print(next(g))print(next(g))
输出:
149
这里非常有代表性。
它不是提前把 [1, 4, 9, 16, 25] 全部准备好, 而是每次 next() 时,运行到 yield i * i,交出一个平方值。
所以你会越来越清楚地感觉到:
生成器函数本质上是在写“逐步产出规则”。
而不是在写“最终一次性返回什么”。
九、生成器函数也可以直接放进 for 循环
这也是你以后最常见的用法之一。
比如:
defsquare_gen():for i in range(1, 6):yield i * ifor x in square_gen(): print(x)
输出:
1491625
这里就特别自然了。
因为生成器本身就是迭代器的一种, 而 for 循环本来就擅长不断向迭代器要下一个值。
所以你会发现:
写生成器函数 再配合 for 循环去消费它
这就是特别经典的一组搭配。
十、yield 不是“每次 return 一下”,而是“产出并保留现场”
这句话你可以重点记一下。
很多人一开始理解 yield 时,会把它想成“可多次 return”。 这个说法虽然有一点帮助,但还不够准确。
更准确的理解是:
yield 不是简单把值交出去,它还会把当前执行现场保留下来。
什么叫执行现场?
当前走到哪一行 当前循环变量是多少 当前局部变量是什么 下次该从哪里继续
这些都会被保留下来。
所以第二次 next() 时,函数不是重头来过,而是接着往下走。
这才是 yield 真正神奇、也真正核心的地方。
十一、一个特别能体现“保留现场”的例子
defdemo(): print('A') x = 10yield x print('B') x = x + 5yield x print('C')
调用:
g = demo()print(next(g))print(next(g))
输出通常是:
A10B15
注意第二次为什么能输出 15?
因为第一次暂停之后,变量 x = 10 这个状态并没有消失。 第二次恢复执行时,程序是在原来的现场基础上继续往下跑,所以:
x = x + 5
才会变成 15。
这就是“保留执行现场”最直观的体现。
十二、生成器为什么特别适合处理大数据流
现在你就能更准确地理解了。
因为它不是先把所有数据准备好,而是:
需要一个 算一个 交出去 暂停 等下次再继续
这意味着,哪怕背后逻辑很长、数据很多,它也不需要一下子把全部结果都堆在内存里。
比如你要处理一百万条数据, 如果一次性做成列表,压力会比较大。 但如果一条一条生成,一条一条处理,就会轻很多。
所以真正让生成器省内存的,不是某种“优化压缩术”, 而是这种天然的按需生产方式。
十三、yield 最适合什么场景
你现在可以先记住下面这些高频场景:
数据量比较大 只打算顺序处理一次 不需要按下标随机访问 想把一个复杂生成过程写清楚 想逐步产出结果,而不是一次性全部返回
比如:
逐行处理大文件 生成大范围数列 批量读取日志 分批产生任务 把一个复杂流程拆成多个产出步骤
只要这种味道出现,生成器函数就很值得考虑。
十四、yield 和普通函数的使用场景区别
普通函数更像:
给我参数 我算完 一次性交给你结果
生成器函数更像:
给我参数 我会按照某种规则 一个一个把结果吐给你
所以不是说谁更高级, 而是它们解决的问题不一样。
如果你的目标就是一次性得到一个最终答案,普通函数更自然。 如果你的目标是分批产出、流式处理,那 yield 生成器函数会特别顺手。
这点一定要分清。
十五、一个特别常见的误区:以为生成器函数调用时就已经开始跑了
不是这样。
比如:
defsimple_gen(): print('开始执行')yield1
如果你写:
g = simple_gen()print(g)
这时通常不会打印“开始执行”。
为什么?
因为调用生成器函数时, Python 并没有立刻把里面的代码跑完。 它只是先创建了一个生成器对象。
真正的代码执行,往往是在你第一次 next(g) 或开始 for 遍历时才开始。
这一点非常重要。 因为它再次说明:
生成器函数的核心不是“调用就执行完”,而是“创建一个可逐步执行的过程”。
十六、生成器函数最后是怎么结束的
和上一章的迭代器一样,当生成器里的值都产出完以后,再继续要值,就会触发:
StopIteration
比如:
defsimple_gen():yield1yield2g = simple_gen()print(next(g))print(next(g))print(next(g))
前两次正常。 第三次就会报结束异常。
这说明生成器和迭代器在终止机制上完全一致。 这也再次印证了:
生成器本身就是迭代器的一种实现方式。
十七、一个特别适合你现在阶段的小案例:生成偶数
defeven_numbers(n):for i in range(1, n + 1):if i % 2 == 0:yield ifor x in even_numbers(10): print(x)
输出:
246810
这个例子特别好,因为它已经有一点“业务味道”了。
你不是在死写 1、2、3。 而是在定义一个规则:
给我一个上限 n我就按顺序一个个产生不超过它的偶数
这就已经非常像真实开发里生成器函数的感觉了。
十八、再做一个更贴近文本处理的例子
比如你想把一句话里的单词一个一个产出:
defwords_generator(text):for word in text.split():yield wordfor w in words_generator('Python is very useful'): print(w)
输出:
Pythonisveryuseful
这个例子很简单,但特别有代表性。
因为它说明生成器函数不仅能生成数字, 还特别适合按规则拆分、产出、处理数据流。
这类思路在日志处理、文本分析、文件逐行清洗里会非常常见。
十九、本章小练习
你可以做三个特别适合巩固的练习。
练习 1 写一个生成器函数,逐个产出 1 到 5。
参考思路:
defgen_nums():for i in range(1, 6):yield i
练习 2 写一个生成器函数,给定 n,逐个产出 1 到 n 的平方数。
参考思路:
defsquare_gen(n):for i in range(1, n + 1):yield i * i
练习 3 在生成器函数里加上 print(),观察它每次 next() 是怎么一步步继续执行的。
这个练习特别重要。 因为它能帮你真正体会“暂停”和“继续”这件事,而不是停留在背定义。
二十、本章总结
这一章最重要的,是把 yield 的核心感觉真正建立起来。
只要函数里出现 yield,它通常就会变成生成器函数。 生成器函数调用后,不会直接返回最终结果,而是返回生成器对象。yield 和 return 最大的区别在于:return 会结束函数,yield 是产出一个值后暂停,并保留执行现场。 下次继续取值时,函数会从上次暂停的位置继续执行,而不是从头开始。 这也是为什么生成器特别适合做按需生成、顺序处理和大数据流场景。 理解 yield,其实就是理解生成器的核心。
下一章我们继续往前走,把前面几章的内容真正收束起来:098|装饰器入门:不改原函数也能增强功能。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
