
工具分享|Scrapling|Python爬虫|Web Scraping|数据采集
做过网页抓取的人都知道,真正麻烦的地方不是写一个 selector。
麻烦的是:页面改版、元素换位置、动态渲染、反爬挑战、长任务中断、代理轮换、并发抓取。
今天分享的 Scrapling,就是一个面向现代网页的自适应 Web Scraping 框架。
一句话总结:Scrapling 不是简单爬虫脚本,而是一套面向现代网页的数据抓取工具箱。
1
它到底是什么?
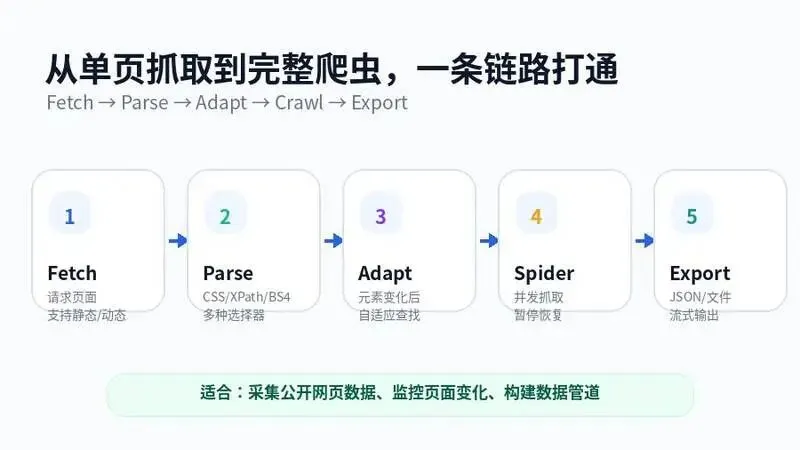
Scrapling 是一个 adaptive Web Scraping framework,定位是从单次请求到完整规模爬虫都能覆盖。
它的核心亮点是:解析器可以学习网站变化,并在页面更新后自动重新定位元素。
同时,它还提供 fetchers、spider framework、CLI、MCP 等能力,把抓取、解析、浏览器、爬虫工程放进同一个工具体系里。

2
它有哪些核心功能?
- Adaptive Parser:元素位置变了之后,可以用 adaptive 方式继续查找。
- 多种 Fetcher:支持普通请求、异步请求、StealthyFetcher、DynamicFetcher。
- 动态浏览器:可以打开浏览器会话,处理需要渲染的页面。
- Spider 框架:支持并发请求、多会话、暂停/恢复和长任务爬取。
- 选择器友好:支持 CSS、XPath、BeautifulSoup 风格查找、文本查找、元素关系导航。
- CLI / Shell:可以用命令行直接抽取页面内容,不一定每次都写完整脚本。
- MCP / AI 能力:项目也提供面向 AI Agent 的能力入口。
3
怎么用它处理不同任务?
- 小任务可以直接用 Fetcher 或 StealthyFetcher 获取页面,然后通过 CSS / XPath 抽取字段。
- 页面是动态渲染时,可以用 DynamicFetcher 或 DynamicSession 打开浏览器抓取。
- 任务变成批量采集时,就可以写 Spider,设置 start_urls、parse 方法和并发参数。
- 长时间任务还可以使用 crawldir 保存进度,中断后继续恢复。
4
性能表现怎么样?
README 里的 benchmark 显示,在 5000 个嵌套元素文本提取测试里,Scrapling 的解析器速度与 Parsel/Scrapy 接近,并明显快于 PyQuery、Selectolax、MechanicalSoup、BeautifulSoup 等方案。
在元素相似度和文本搜索测试中,Scrapling 也展示了比 AutoScraper 更快的性能。
这些数据说明它不是只堆功能,而是把解析性能也放在了比较重要的位置。
5
安装方式
- 只想用解析器:pip install scrapling。
- 需要 fetchers 和浏览器能力:pip install "scrapling[fetchers]",然后运行 scrapling install。
- 需要 MCP / AI 相关能力:pip install "scrapling[ai]"。
- 需要 shell 和 extract 命令:pip install "scrapling[shell]"。
- 想一次装全:pip install "scrapling[all]"。

6
适合哪些场景?
- 采集公开网页中的商品、文章、列表、价格、评论等结构化信息。
7
使用前一定要注意
- 不要把它用于绕过登录、付费墙或明确禁止抓取的内容。
- 抓取前要看网站 ToS、robots.txt 和当地法律要求。
- 涉及商业使用时,建议做权限确认、合规评估和日志留存。
Scrapling 最有意思的地方,是它把“网页变了怎么办”这个爬虫老大难问题放到了核心位置。
它不是只给你一个选择器工具,而是把解析、抓取、动态浏览器、爬虫框架、CLI 和 AI Agent 接口都串起来。
对于经常做公开数据采集、网页监控、爬虫工程的人来说,这个项目值得收藏。
一句话总结:Scrapling 不是简单爬虫脚本,而是一套面向现代网页的数据抓取工具箱。
工具分享|Scrapling|Python爬虫|公开数据采集|合规使用
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
