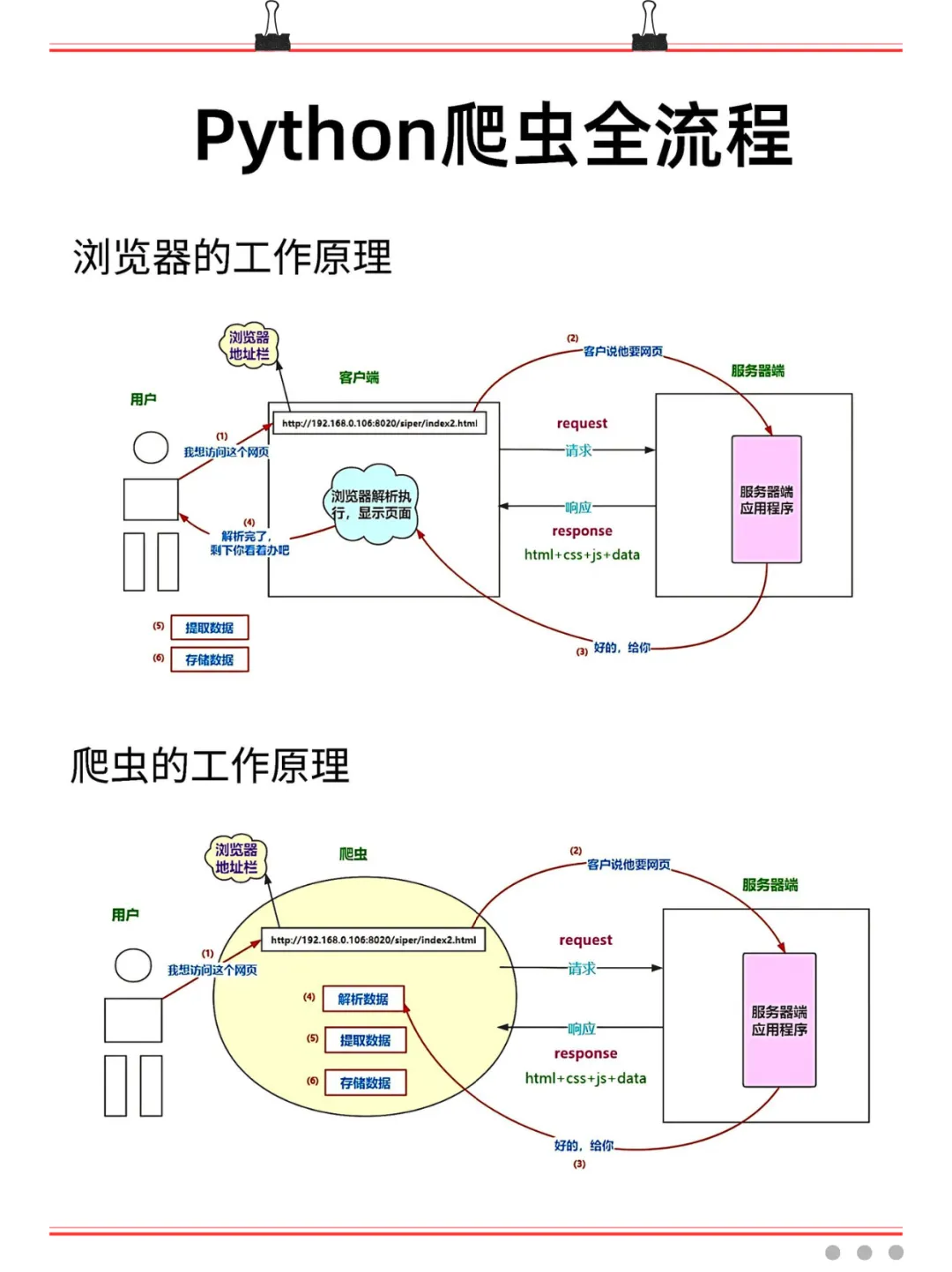
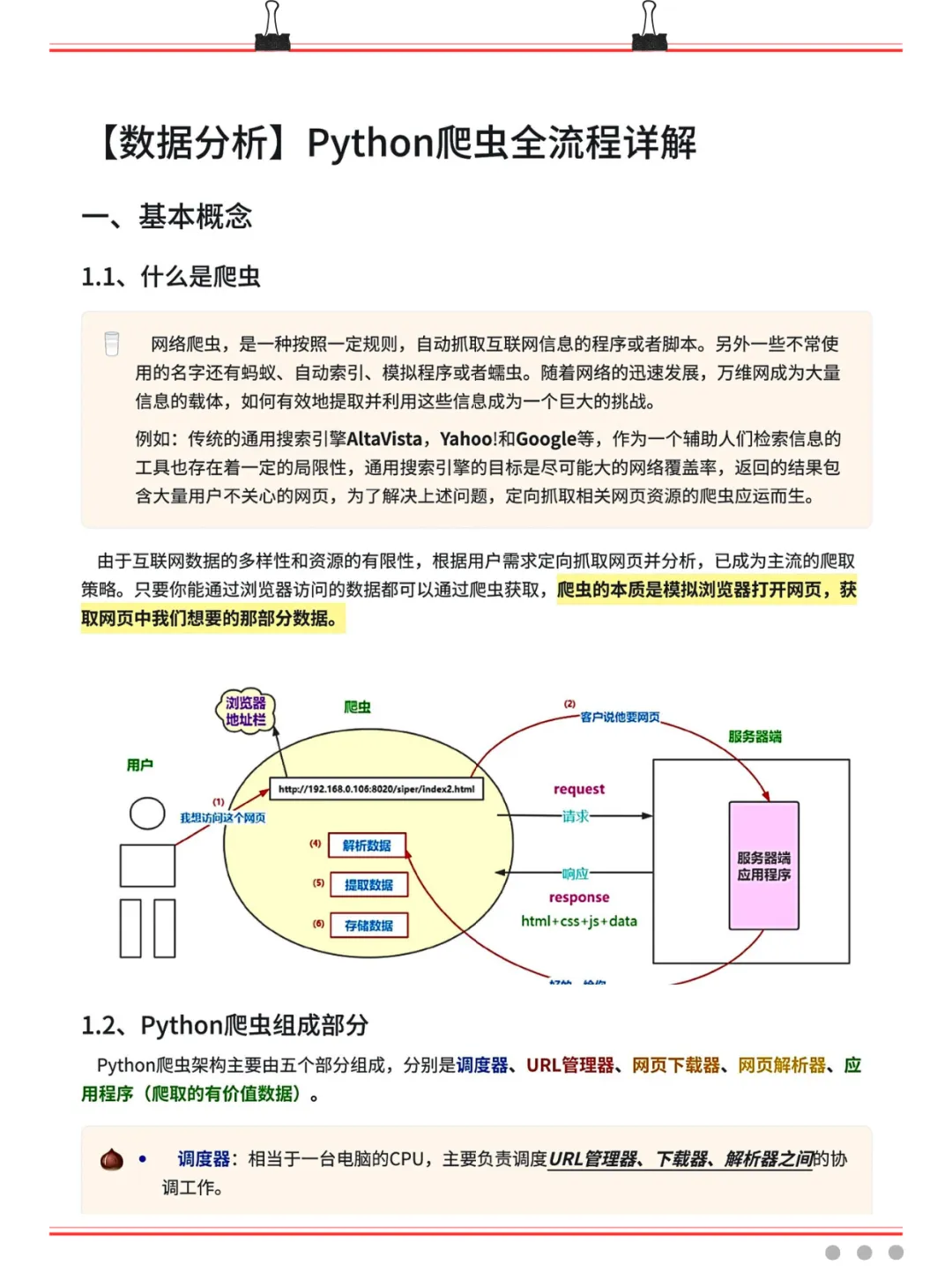
说白了,爬虫就像是你派出去的一台“信息收割机”——设定好规则,它就自动去互联网上帮你把想要的数据批量搬回来,省时省力,比你手动搜快太多了。
道理是这么个道理,但很多小伙伴一上手就被各种专业概念绕晕了:调度器、URL管理器、下载器、解析器……这些到底谁先谁后?浏览器和爬虫之间到底是什么关系?一旦搞不清楚这些,写代码就无从下手。