32岁零基础学Python量化 第7周 AI量化基础之浅层神经网络(附实战代码)
- 2026-07-02 01:54:51
吴恩达系列之浅层神经网络
前言:
有人说神经网络和量化有什么关系,我这样学完全是跑偏了,我的理解是,目前所做的东西是为未来做AI量化做地基,目前看做策略回测可能收益更大,但是我一开始的文章也有提到过,我想做的是“AI量化投资”,学习神经网络恰恰是第一步。
其实量化投资和神经网络有非常相似的地方,我列了个对比表,一目了然:

本篇简述
上一篇介绍了逻辑回归二分类问题(识猫),本篇我们探索一个数据看似像一朵红蓝点构成的花的二维平面数据(Planar data)分类问题,也就是只有两个特征,可以直接画在二维坐标系上的数据点,具体如下图:
我们使用上一篇的识猫程序使用的逻辑回归模型进行分类,结果如下:
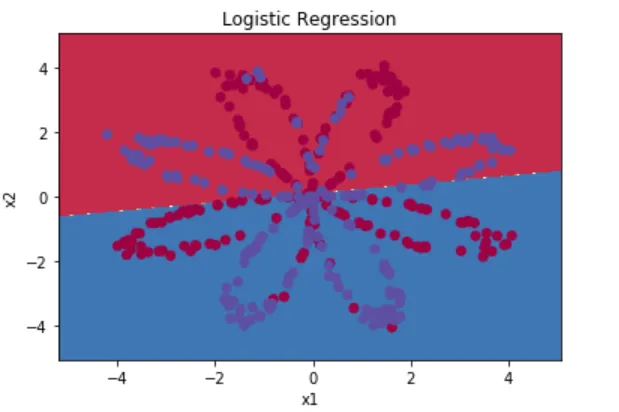
这样看来,简单的逻辑回归模型无法适应此类二维平面数据,此类数据是非线性可分的,它不能通过一条直线就将数据分开,所以我们引入单隐层神经网络,也就是在逻辑回归模型的基础上增加一个隐藏层和非线性激活函数,使得模型具备‘扭曲’空间的能力,能够拟合出复杂的曲线,或者任意形状的非线性决策边界。总的来说上篇的逻辑回归模型(识猫)和本篇的单隐层神经网络(二维数据分类)有以下几个维度的区别:
1. 数据的分布形态(最直观的区别)
• 上篇assignment2(逻辑回归): 数据通常是线性可分(或近似线性可分)的。在特征空间里,你总能画出一条直线(或一个超平面),把“猫”和“非猫”完美或大部分分开。 • 本篇assignment3(单隐层神经网络): 数据是非线性可分的。给你一朵“小红花”形状的数据集,或者一圈一圈的同心圆。你无论如何也画不出一条直线能把红点和蓝点分开。
2. 模型的决策边界(数学本质)
• 上篇assignment2(逻辑回归): 本质上是一个线性分类器。它的决策边界是一条直线(方程形式为 )。面对非线性数据,它的准确率会卡在一个瓶颈,无法继续提升。 • 本篇assignment3(单隐层神经网络): 引入了隐藏层和非线性激活函数(如 tanh或ReLU)。这使得模型具备了“扭曲”空间的能力,能够拟合出复杂的曲线、圈甚至任意形状的非线性决策边界。
3. 特征提取的能力
• 上篇assignment2(逻辑回归): 模型只能直接使用你喂给它的原始输入特征(比如图片的像素值)。如果原始特征本身不具备线性可分性,它就无能为力。 • 本篇assignment3(单隐层神经网络): 隐藏层充当了特征提取器。它能把原始的、低维的、纠缠在一起的特征,映射到一个新的高维空间里。在这个新空间里,原本不可分的数据变得线性可分了,最后再由输出层进行分类。
总结一下:上篇是在讲如何用一条直线去切分数据,而本篇是在讲 当直线切不开时,如何给数据加一个维度(隐藏层),把它变成可以用曲面切分的问题。这就是神经网络能够解决复杂问题(如图像识别、自然语言处理)的核心魔法下面我将直接针对浅层神经网络的代码进行复现,过程中出现的问题我将进行详细解析。
浅层神经网络代码复现
(注:本篇基于吴恩达深度学习assignment3)
专业词汇预备
parameters 参数forward 前向propagation 传播initialize 初始化backward 反向update 更新num_iterations 迭代次数predict 预测
一.准备阶段
1.载入必要库文件
# 导入numpy库并简写为np,用于高效的数值计算import numpy as np# 导入matplotlib的pyplot模块并简写为plt,用于数据可视化与绘图import matplotlib.pyplot as plt# 从testCases模块中导入所有测试用例,用于后续验证代码逻辑from testCases import *# 导入sklearn(scikit-learn)库,提供常用的机器学习算法与工具import sklearn# 导入sklearn中的datasets模块,用于加载内置的示例数据集import sklearn.datasets# 导入sklearn中的linear_model模块,提供线性回归等线性模型算法import sklearn.linear_model# 从planar_utils模块导入自定义工具函数,包括决策边界绘制、Sigmoid函数及数据集加载等from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets# 设置魔法命令,使matplotlib生成的图表能够直接在Jupyter Notebook中内联显示%matplotlib inline# 设置随机数种子为1,确保每次运行代码时生成的随机结果保持一致,便于复现和调试np.random.seed(1) 2.数据写入

3.定义神经网络结构

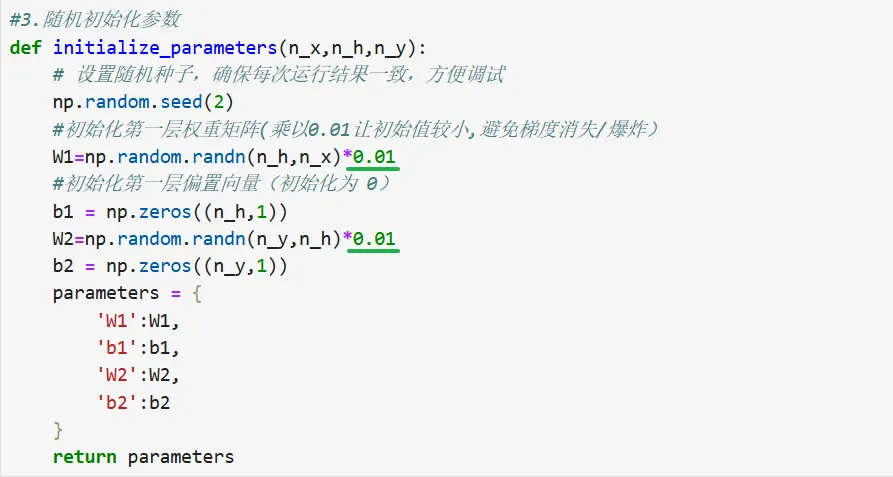
4.参数初始化
• 代码复现

• 代码纠正: 1.防止激活函数进入“饱和区”(Sigmoid/Tanh 的情况)在使用 Sigmoid 或 Tanh 这类 S 型激活函数时,如果初始权重非常大,输入到激活函数的值就会非常大(绝对值)。会导致激活函数的输出直接趋近于 0 或 1(即曲线的两端)。这些区域函数的导数几乎为 0。在反向传播时,梯度会连乘这些接近 0 的导数,导致梯度消失。权重无法更新,模型也就无法学习。乘以 0.01可以让初始输入落在激活函数中间斜率较大的区域,确保梯度能顺利传回(这里0.01是经验值,对于非常深的网络,这个值需要调整)。
最后,关于随机种子,在跑机器学习或深度学习模型时,虽然参数初始化带有随机性,但只要大家用同一个“种子(seed)”,生成的随机数序列就会一模一样,最终的结果也就完全对得上。这在代码复现和排查 bug 时很好用。
• 修改后的代码
二.主体训练部分
1.前向传播求成本
• 代码复现
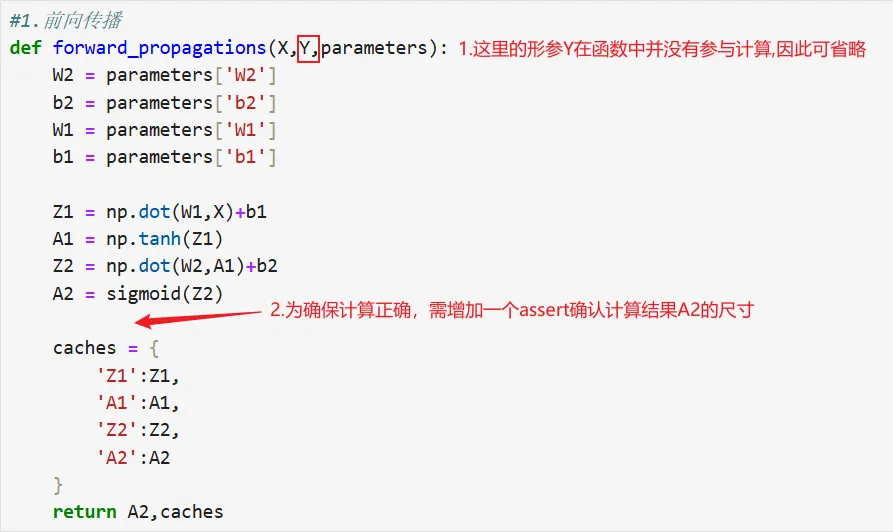

• 代码纠正:在计算交叉熵损失时 np.sum()默认会对整个数组求和,但它不会自动改变数组的维度结构,而是会保留一个外层维度。因此,即使你算出来的是一个单一数值,costs的形状可能依然是(1,)或者[[17]],而不是一个单纯的数字17。这边需要两行np.squeeze()移除数组中所有长度为 1 的维度(也就是把多余的“壳”剥掉)确保costs不是一个嵌套的数组而是一个纯粹的标量,同时需要assert确保costs是一个浮点数。• 修改后的代码

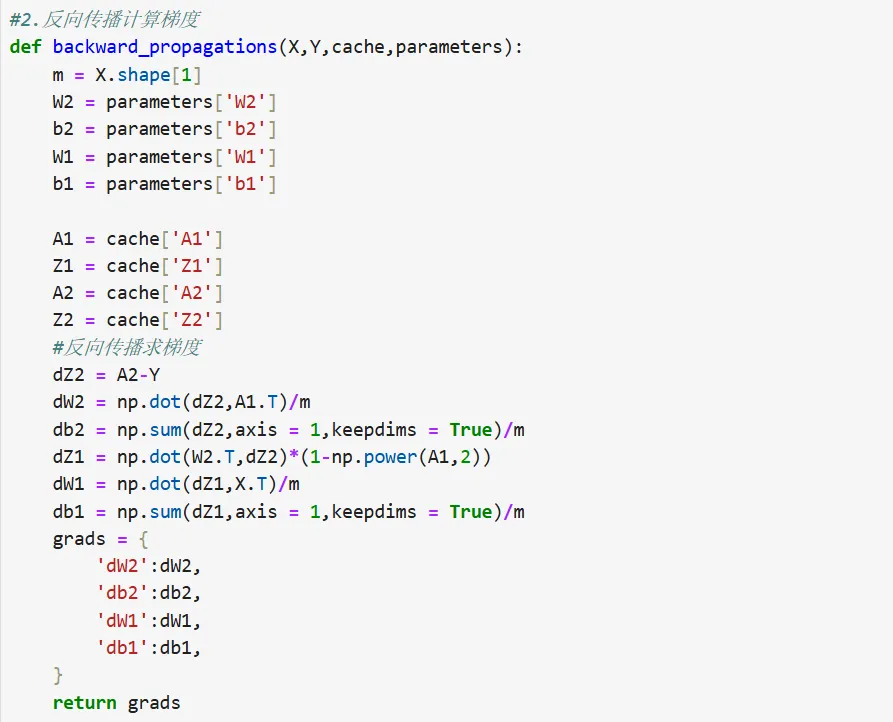
2.反向传播求梯度
• 代码复现
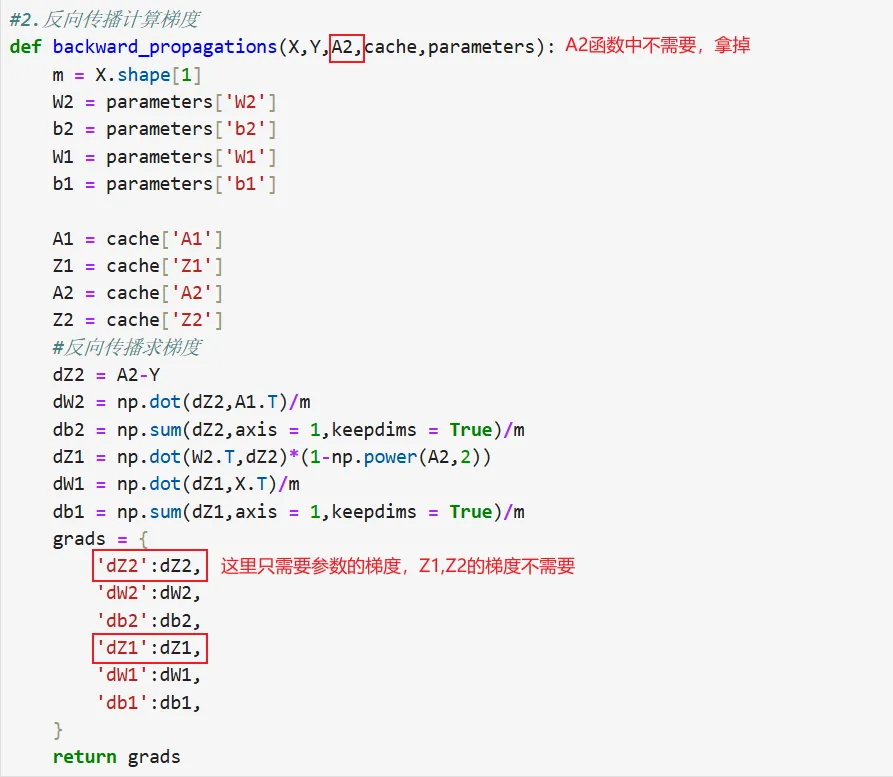
• 代码纠正:为了保证代码的简洁性,不需要的形参和返回值需拿掉 • 修改后的代码
3.用梯度更新参数
• 代码复现

• 代码说明:此处原方案是将parameters中的参数取出计算后再重新赋值到parameters这个字典中去,这边我调整了一下,直接用字典键值进行更新,使得代码更简洁。
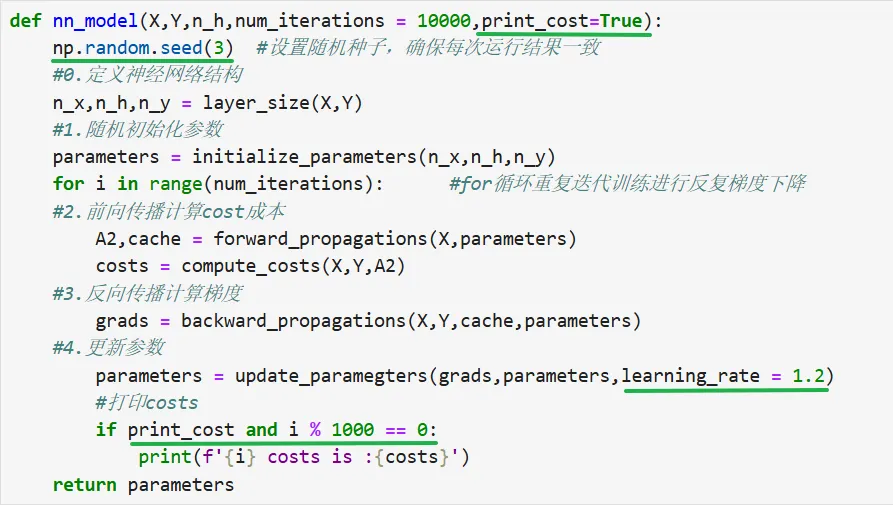
三.模型集成
• 代码复现

• 代码纠正:3.增加一个 print_cost=True的“是否打印训练进度”的开关。设为 True:程序会定期在控制台打印当前的误差值(Cost),方便你观察模型有没有在正常学习。设为 False:程序照常训练,但保持安静,不打印任何进度信息。• 修改后的代码
四.预测
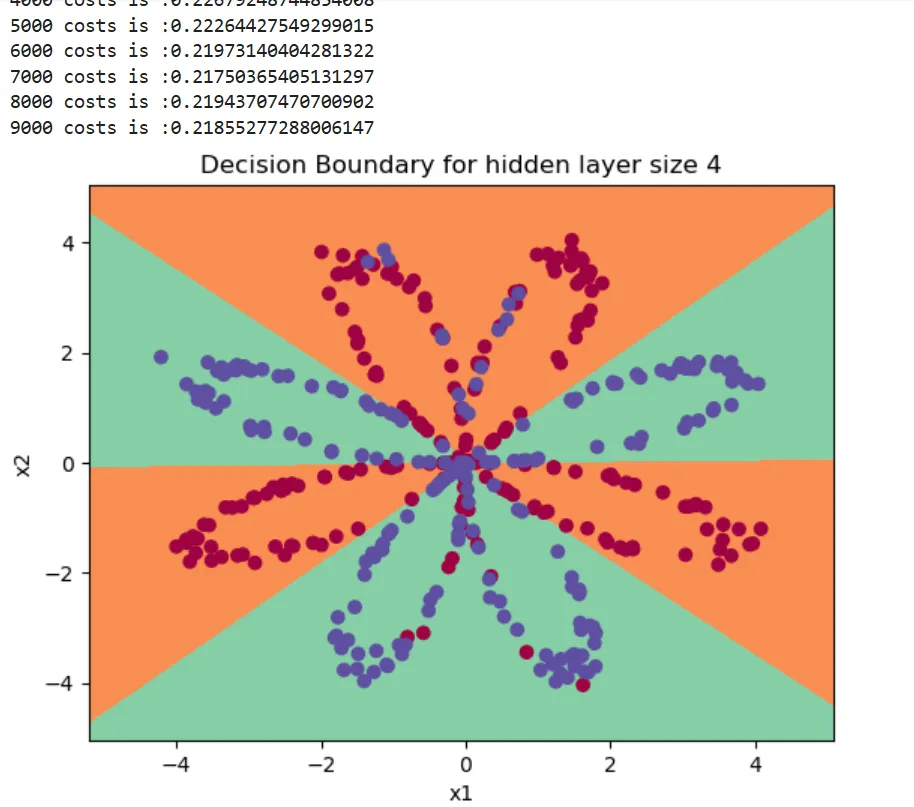
• 代码复现


• 代码运行输出正确:很好的区分了红蓝点
五.单隐层神经网络完整代码
#一.准备阶段#1.导入库文件# 导入numpy库并简写为np,用于高效的数值计算import numpy as np# 导入matplotlib的pyplot模块并简写为plt,用于数据可视化与绘图import matplotlib.pyplot as plt# 从testCases模块中导入所有测试用例,用于后续验证代码逻辑from testCases import *# 导入sklearn(scikit-learn)库,提供常用的机器学习算法与工具import sklearn# 导入sklearn中的datasets模块,用于加载内置的示例数据集import sklearn.datasets# 导入sklearn中的linear_model模块,提供线性回归等线性模型算法import sklearn.linear_model# 从planar_utils模块导入自定义工具函数,包括决策边界绘制、Sigmoid函数及数据集加载等from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets# 设置魔法命令,使matplotlib生成的图表能够直接在Jupyter Notebook中内联显示%matplotlib inline# 设置随机数种子为1,确保每次运行代码时生成的随机结果保持一致,便于复现和调试np.random.seed(1)#2.加载一维平面数据X, Y = load_planar_dataset()#3.定义神经网络结构def layer_size(X,Y): n_x = X.shape[0] n_h = 4 n_y = Y.shape[0] return n_x,n_h,n_y#4.随机初始化参数def initialize_parameters(n_x,n_h,n_y): # 设置随机种子,确保每次运行结果一致,方便调试 np.random.seed(2) #初始化第一层权重矩阵(乘以0.01让初始值较小,避免梯度消失/爆炸) W1=np.random.randn(n_h,n_x)*0.01 #初始化第一层偏置向量(初始化为 0) b1 = np.zeros((n_h,1)) W2=np.random.randn(n_y,n_h)*0.01 b2 = np.zeros((n_y,1)) parameters = { 'W1':W1, 'b1':b1, 'W2':W2, 'b2':b2 } return parameters#二.主体训练部分#1.前向传播def forward_propagation(X,parameters): #~~~~~~~~~~~~不需要Y #获取参数 W2 = parameters['W2'] b2 = parameters['b2'] W1 = parameters['W1'] b1 = parameters['b1'] #正向传播计算 Z1 = np.dot(W1,X)+b1 A1 = np.tanh(Z1) Z2 = np.dot(W2,A1)+b2 A2 = sigmoid(Z2) assert(A2.shape == (1, X.shape[1]))#~~~~~~~~~~~~~~~~~增加一个确认尺寸 cache = { 'Z1':Z1, 'A1':A1, 'Z2':Z2, 'A2':A2 } return A2,cache#求cost成本函数def compute_costs(X,Y,A2): m = X.shape[1] #求样本数量 costs=(-1/m)*np.sum(np.multiply(Y,np.log(A2))+np.multiply((1-Y),np.log(1-A2))) #求交叉熵损失函数 #np.squeeze()专门用来“挤压”掉那些大小为 1 的维度 #如果costs的形状是[[17]](形状为(1,1)),np.squeeze会把它变成纯数字17。 costs = np.squeeze(costs) assert(isinstance(costs, float)) return costs#2.反向传播计算梯度def backward_propagation(X,Y,cache,parameters): m = X.shape[1] W2 = parameters['W2'] b2 = parameters['b2'] W1 = parameters['W1'] b1 = parameters['b1'] A1 = cache['A1'] Z1 = cache['Z1'] A2 = cache['A2'] Z2 = cache['Z2'] #反向传播求梯度 dZ2 = A2-Y dW2 = np.dot(dZ2,A1.T)/m db2 = np.sum(dZ2,axis = 1,keepdims = True)/m dZ1 = np.dot(W2.T,dZ2)*(1-np.power(A1,2)) dW1 = np.dot(dZ1,X.T)/m db1 = np.sum(dZ1,axis = 1,keepdims = True)/m grads = { 'dW2':dW2, 'db2':db2, 'dW1':dW1, 'db1':db1, } return grads#3.更新参数def update_paramegters(grabs,parameters,learning_rate = 1.2): dW2 = grabs['dW2'] db2 = grabs['db2'] dW1 = grabs['dW1'] db1 = grabs['db1'] parameters['W2'] -= learning_rate*dW2 parameters['b2'] -= learning_rate*db2 parameters['W1'] -= learning_rate*dW1 parameters['b1'] -= learning_rate*db1 return parameters#三.模型集成def nn_model(X,Y,n_h,num_iterations = 10000,print_cost=True): np.random.seed(3) #设置随机种子,确保每次运行结果一致 #0.定义神经网络结构 n_x,n_h,n_y = layer_size(X,Y) #1.随机初始化参数 parameters = initialize_parameters(n_x,n_h,n_y) for i in range(num_iterations): #for循环重复迭代训练进行反复梯度下降 #2.前向传播计算cost成本 A2,cache = forward_propagation(X,parameters) costs = compute_costs(X,Y,A2) #3.反向传播计算梯度 grads = backward_propagation(X,Y,cache,parameters) #4.更新参数 parameters = update_parameters(grads,parameters,learning_rate = 1.2) #打印costs if print_cost and i % 1000 == 0: print(f'{i} costs is :{costs}') return parameters#四.预测def predict(parameters,X): A2,cache = forward_propagation(X,parameters) predictions = (A2>0.5) return predictions# 新建一个单隐藏层模型,隐藏层维度为n_h = 4parameters = nn_model(X, Y, n_h = 4, num_iterations = 10000, print_cost=True)# 画个决策边界plot_decision_boundary(lambda x: predict(parameters, x.T), X,Y.reshape(X[0,:].shape))plt.title("Decision Boundary for hidden layer size " + str(4))plt.show()公式知识补充
本篇核心是单隐层神经网络(Single Hidden Layer Neural Network)。为了彻底弄懂,我们假设一个具体的网络结构:输入层有 个特征,隐藏层有 个神经元,输出层有 1 个神经元(用于二分类)。
将整个计算过程分为前向传播、损失计算和反向传播三个阶段来详细拆解。
一、 前向传播(Forward Propagation)
目标:从输入数据计算出预测值
1. 隐藏层计算
• 线性变换: • 是输入数据矩阵(维度:, 是样本数)。 • 是隐藏层的权重矩阵(维度:)。 • 是隐藏层的偏置矩阵(维度:)。 • 是隐藏层的线性输出(维度:)。 • 非线性激活: • 这里通常使用 tanh或ReLU。tanh会将结果压缩到 之间,为网络引入了非线性,这是它比逻辑回归强大的关键。• 是隐藏层的激活输出(维度:)。
2. 输出层计算
• 线性变换: • 是输出层的权重矩阵(维度:)。 • 是输出层的偏置(维度:)。 • Sigmoid 激活: • 因为是二分类,输出层使用 Sigmoid 函数,将结果压缩到 之间,代表属于正类的概率。
二、 损失计算(Cost Function)
目标:衡量预测值 和真实标签 之间的差距
使用交叉熵损失(Cross-Entropy Loss):
• 当真实标签 时,我们希望预测值 尽可能接近 1;当 时,希望 尽可能接近 0。 • 这个公式通过向量化(Vectorization)可以写成矩阵形式,方便用代码一步算出所有样本的损失。
三、 反向传播(Backward Propagation)
目标:计算损失函数对每个参数的梯度,用于更新参数
这里用到链式法则(Chain Rule)。我们从输出层往回倒推:
1. 输出层的梯度
• • 核心结论: 当使用 Sigmoid 激活函数和交叉熵损失时,输出层的误差项 刚好等于预测值减去真实值,这个简洁的公式是数学推导的结果。 • • (代码中通常用 np.sum(dZ2, axis=1, keepdims=True) / m)
2. 隐藏层的梯度
• • 关键点: 这里的 *是逐元素相乘(Element-wise),不是矩阵乘法。• 是 tanh函数的导数。因为 的导数是 ,而 就是 。• 表示把输出层的误差“反向传递”回隐藏层。 • •
四、 参数更新(Gradient Descent)
目标:沿着梯度的反方向,让损失 变小
• 是学习率(Learning Rate),控制每次更新的步长。
总结:公式相对复杂,但不需要死记硬背,需要记住前向传播的逻辑,然后理解反向传播中链式法则的求导过程。重点检查每一步矩阵的维度是否匹配,只要维度对得上,公式基本就不会写错,导数推导过程就不详细写了,后面可能会新开一篇单独讲下。
结语
下篇将更新深层神经网络内容,对于本篇各位同学和前辈有什么心得或建议欢迎留言一起交流。谢谢看完,晚安~~

