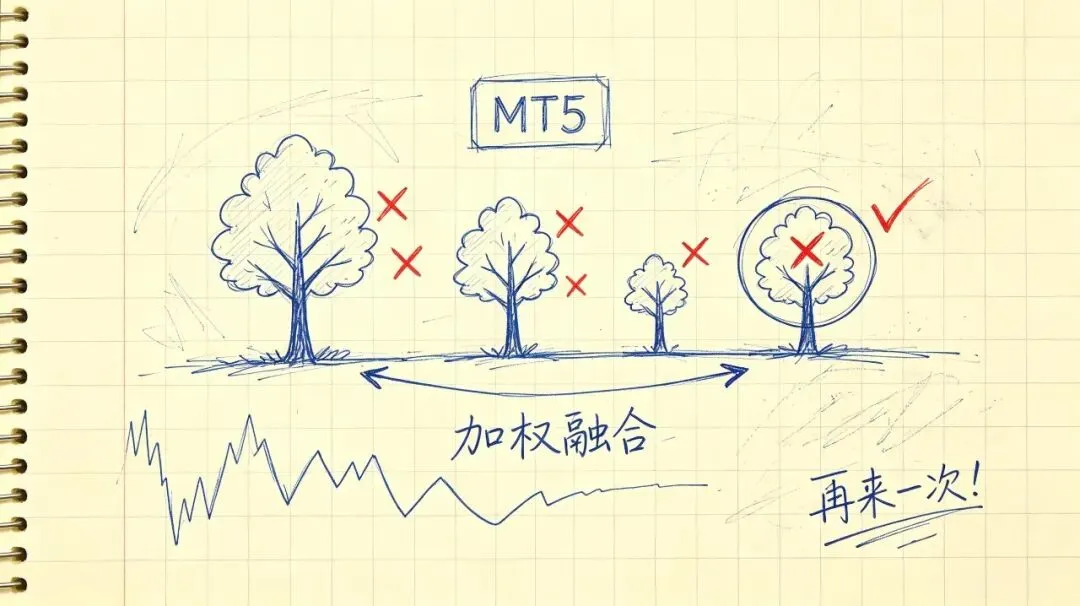
本篇的核心思路是通过迭代优化弱学习器、聚焦误差样本,即串行训练一堆弱模型,每个新模型都盯着前一个犯错的地方使劲学,最后把所有人加权组合成一个强家伙。金融市场那些非线性、说不清道不明的关系,用这套路子去抓,效果往往不错,能把预测精度提上去,最终落地成多空策略。
提升算法到底在干嘛
说白了就是个"错题集"逻辑。第一棵树的预测肯定一堆错的,第二棵树就专门盯着错的样本学,第三棵再盯前两棵都没搞定的那些。一轮轮叠加上去,最后把所有人的意见加权汇总。
这思路在金融数据上我觉得挺对路。价格走势那堆乱七八糟的非线性关系,你让线性回归去抓基本没戏,但Boosting这套串行纠偏的玩法,确实能挖出一些东西。
AdaBoost和GBM是两条基础路线。AdaBoost偏二分类,调样本权重迭代,简单粗暴。GBM更通用些,把优化目标转成梯度下降来搞,回归分类都能上。量化里好像GBM用得更多一些。
几个关键参数得心里有数。学习率我一般从0.05开始试,调低了稳一些,但树得加。早停我习惯开着,验证集一躺平就收工,不然总觉得在浪费电。子采样就是随机抽样本训练每棵树,对防过拟合感觉有点用。
XGBoost、LightGBM、CatBoost怎么选
XGBoost给我的感觉最稳,二阶泰勒展开优化损失,正则化直接嵌目标函数里,泛化确实不错。中低频多因子策略我一般优先用它。
LightGBM快得有点离谱,直方图分箱+单边梯度采样,内存占用也低。分钟级数据量一大,用它训练体感上比XGBoost能快一倍不止。
CatBoost最省事,类别特征自动处理,行业标签、品种分类直接往里扔,不用自己折腾编码,懒人福音。
调参我一般不会一上来就GridSearch全扫,太费时间。通常是先粗调学习率,确定个大概量级,再精调树深度和子采样比例。交叉验证用TimeSeriesSplit,随机打乱在时序数据里感觉不太妥当。
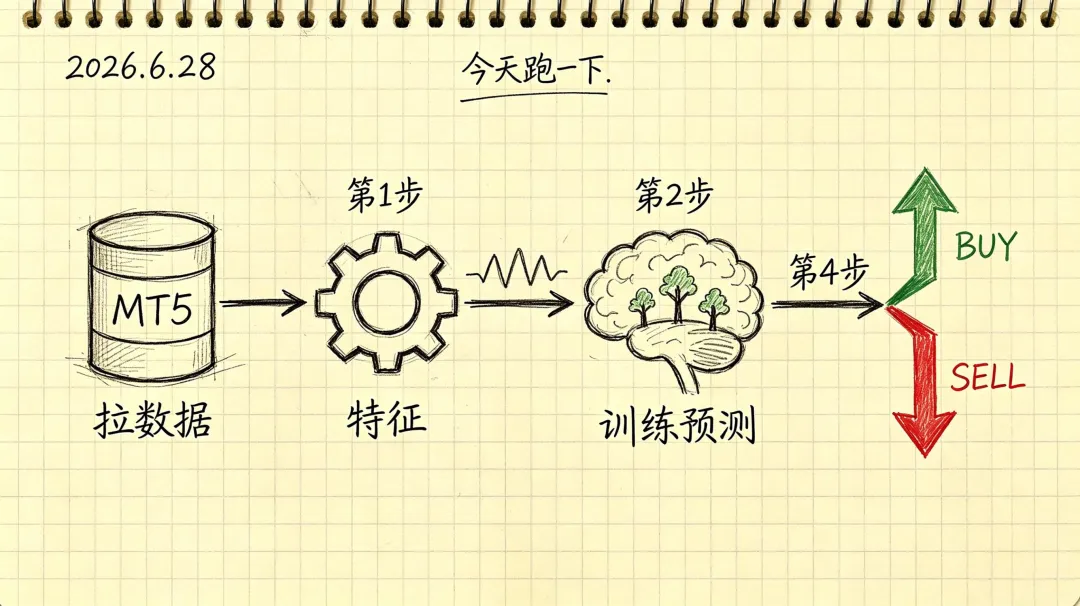
MT5上撸了一遍流程
数据用MetaTrader5库直接拉,代码量不大:
import MetaTrader5 as mt5
import pandas as pd
mt5.initialize()
rates = mt5.copy_rates_range("EURUSD", mt5.TIMEFRAME_H1,
datetime(2024,1,1), datetime(2024,12,31))
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
特征这块,技术指标用pandas-ta一把梭。但我发现光加RSI、MACD这些好像还不够,滞后特征最好也跟上——价格增量的lag值对时序依赖的捕捉挺关键。
目标变量看你怎么定义。我试过二元分类(涨/跌),也试过回归预测具体收益率。回归的信息量更大一些,但标注难度也高一点,实盘对齐的时候稍微麻烦点。
训练代码大致长这样:
from xgboost import XGBClassifier
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
model = XGBClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=5,
subsample=0.8,
early_stopping_rounds=10
)
model.fit(X_train, y_train,
eval_set=[(X_valid, y_valid)],
verbose=False)
时间顺序千万别乱。我见过有人不小心用未来数据做验证还浑然不觉,回测曲线漂亮得不像话,一实盘就原形毕露。训练集老老实实放在验证集前面。
信号出来之后调MT5接口下单:
pred = model.predict(X_test)
for idx, signal inenumerate(pred):
if signal == 1:
mt5.order_send(
symbol="EURUSD",
action=mt5.TRADE_ACTION_DEAL,
order_type=mt5.ORDER_TYPE_BUY,
volume=0.01,
price=mt5.symbol_info_tick("EURUSD").ask
)
else:
mt5.order_send(
symbol="EURUSD",
action=mt5.TRADE_ACTION_DEAL,
order_type=mt5.ORDER_TYPE_SELL,
volume=0.01,
price=mt5.symbol_info_tick("EURUSD").bid
)
仓位我是按预测得分排序,前30%做多后30%做空,每周再平衡一次。回测用的NautilusTrader接MT5,佣金滑点都塞进去了。
模型不能当黑箱用
跑归跑,最好还是知道模型凭啥下单。
特征重要性最直接,跑完就能看哪些因子在起作用。部分依赖图能告诉你PE和预测收益之间大概是正相关还是负相关,拐点在哪儿大概也能瞧出来。
SHAP值这玩意儿挺细,单个样本为什么被预测为涨,每个特征贡献了多少正负,全给你拆开。跟老板解释策略逻辑的时候特别管用。
高频场景踩的坑
试过用LightGBM跑分钟级数据。特征得换——分钟级波动率、成交量变化率、盘口委比这些,比日线那些指标好使。数据量大了,先用互信息筛一遍特征降维,不然训练慢得想哭。
信号质量评估别只看准确率。滚动IC、胜率、盈亏比这三个组合着看,比单一指标心里有底一些。
几个实实在在的坑
过拟合是老大难。树深度限制一下、学习率压一压、子采样拉开点,早停开起来——验证集一旦开始变差就别硬撑了。
数据泄露防不胜防。基本面数据发布有滞后,你用的PE如果是财报截止日的数据,实盘根本拿不到。回测时最好把滑点和佣金算进去,我见过好几个人忽略这个,回测年化三十几,实盘一跑手续费吃掉一大截。
类别特征忘编码也是个低级错误,XGBoost和LightGBM不自动处理这玩意儿,用CatBoost可以省点心。
内存扛不住的时候用子采样和特征筛选顶着,别硬上全量。
选型上我自己的习惯

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
