🤔 为什么需要 Triton
大模型训练和推理中,总有些算子是 PyTorch 原生不提供的——自定义注意力机制、稀疏矩阵操作、前向反向融合算子。过去只有两条路:要么用 PyTorch 原生算子拼凑(多次读写 HBM,性能拉胯),要么写 CUDA C++ 扩展(门槛极高、开发周期长)。
Triton 填补了中间的空白:用 Python 语法写 GPU Kernel,编译器自动处理向量化、共享内存管理和线程调度,性能可达手工 CUDA 的 80-90%,而开发效率提升数倍。OpenAI 于 2021 年发布 Triton,如今它已成为 PyTorch Inductor 编译器的默认后端——当你调用 torch.compile 时,大部分融合算子就是 Triton 生成的。
💡 关键数据
相比朴素 PyTorch 实现,Triton 融合 Kernel 通常能降低 2-10 倍延迟;相比手工 CUDA,开发时间从数周缩短到数小时,性能差距在 10-20% 以内。FlashAttention 的 Triton 实现就是最好的证明。
🧩 编程模型:从线程到块
理解 Triton 的关键,是先忘掉 CUDA 的线程思维。
🟢 CUDA:线程级编程
你定义每个线程做什么:通过 blockIdx 和 threadIdx 计算元素索引,一个线程处理一个或几个元素。你需要手动管理共享内存、同步屏障、内存合并。
🔵 Triton:块级编程
你定义每个程序(program)处理一块数据:通过 tl.program_id 标识程序编号,用 tl.load/tl.store 批量读写一整块数据。编译器自动处理向量化和内存布局。
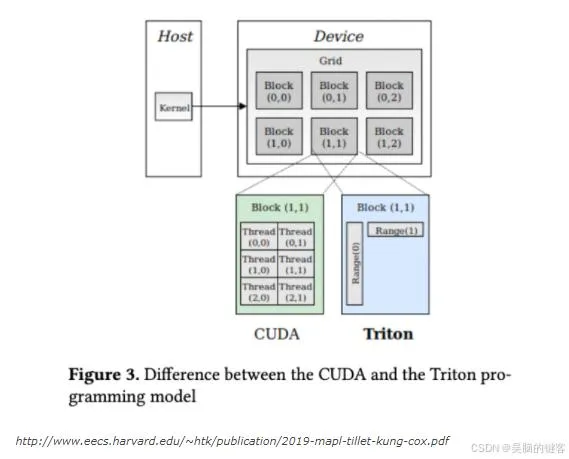
CUDA 中你操作线程(Thread),Triton 中你操作块(Range/Tile)
在 CUDA 里,常见的抽象是 grid → block → thread,你会写 int tid = blockIdx.x * blockDim.x + threadIdx.x,然后让每个 thread 处理一个元素。
而在 Triton 中,抽象变成了 grid → program → vectorized operations。Triton 里的 program 粗略类比 CUDA 的一个 block/CTA,但你不需要关心 thread id,而是写:
Python
pid=tl.program_id(0)offsets=pid*BLOCK_SIZE+tl.arange(0, BLOCK_SIZE)x=tl.load(x_ptr+offsets, mask=mask)
这里的 offsets 是一个向量(比如 [0,1,2,...,1023]),tl.load 一次性加载一整块数据。这就是 Triton 的核心风格:一个 program 负责一块数据,program 内部用向量化表达一组元素的计算。
🔑 核心概念速览
@triton.jit
装饰器,标记函数为 Triton Kernel。JIT 编译,首次调用时编译并缓存。
tl.program_id(axis)
获取当前 program 的编号。类比 CUDA 的 blockIdx,但维度语义更清晰。
tl.constexpr
编译时常量。BLOCK_SIZE 必须声明为 constexpr,编译器据此优化内存访问。
tl.arange(start, end)
生成等差序列向量。如 tl.arange(0, 1024) 生成 [0,1,...,1023]。
tl.load / tl.store
批量内存读写。支持 mask 防越界,支持 other 指定填充值。
Grid 启动网格
决定启动多少个 program 实例。类比 CUDA grid,用 triton.cdiv 做向上取整。
⚠️ 关于 mask 的要点
向量长度可能不是 BLOCK_SIZE 的整数倍,最后一个 program 可能只处理部分元素。mask = offsets < n_elements 确保不越界访问。mask=False 的位置不会被加载/写入,也可以用 other=0.0 指定填充值。
🔧 编译管线
Triton Kernel 从 Python 代码到 GPU 执行,经历以下编译步骤:
Python 代码
→
TTIR
Triton IR
→
TTGIR
Triton GPU IR
→
LLVM IR
→
PTX
→
Cubin
TTIR(Triton IR)是高层中间表示,保留 Triton 语义(load/store/dot 等),执行公共子表达式消除、广播优化等通用变换。
TTGIR(Triton GPU IR)引入 GPU 特定概念:共享内存布局、warp 分组、流水线编排、warp 特化等。NVIDIA 后端会根据架构(Ampere/Hopper/Blackwell)启用不同优化 pass。
LLVM IR → PTX → Cubin:借助 LLVM 基础设施完成最终代码生成。整个过程在首次调用时自动完成,无需手动编译。
💡 调试技巧
你可以通过 kernel.asm['ttir']、kernel.asm['ttgir']、kernel.asm['ptx'] 查看各级 IR,这在性能调优时非常有用。
🚀 示例一:向量加法 — Hello World
从最简单的例子开始。两个向量逐元素相加,这是理解 Triton 编程模式的最佳入口。
Python — Triton Kernel复制
import torchimport tritonimport triton.language as tl@triton.jitdefadd_kernel( x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr, ): # 1. 获取当前 program 的编号 pid = tl.program_id(axis=0) # 2. 计算这个 program 负责的数据偏移 block_start = pid * BLOCK_SIZE offsets = block_start + tl.arange(0, BLOCK_SIZE) # 3. 创建 mask 防止越界 mask = offsets < n_elements # 4. 从 DRAM 批量加载数据 x = tl.load(x_ptr + offsets, mask=mask) y = tl.load(y_ptr + offsets, mask=mask) # 5. 计算 + 写回 output = x + y tl.store(output_ptr + offsets, output, mask=mask)
然后写一个 Python 包装函数,负责分配输出张量和启动 Kernel:
Python — Launch Wrapper复制
defadd(x: torch.Tensor, y: torch.Tensor): output = torch.empty_like(x) n_elements = output.numel() # Grid: 每个 program 处理 BLOCK_SIZE 个元素 grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),) # 启动 kernel,元参数必须用关键字传递 add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024) return output# 验证x = torch.randn(10_000_000, device='cuda') y = torch.randn(10_000_000, device='cuda') torch.testing.assert_close(add(x, y), x + y)
🔑 核心要点
① tl.program_id 标识"我是哪个 program";② tl.arange 生成块内偏移向量;③ mask 处理边界;④ tl.load/store 批量访存;⑤ triton.cdiv 计算需要多少个 program。这五步是所有 Triton Kernel 的通用骨架。
🔥 示例二:融合 Softmax — Kernel Fusion 的威力
Softmax 是展示 Triton 融合优势的经典案例。朴素 PyTorch 实现需要三次读写 HBM:一次求 max、一次求 exp 和 sum、一次归一化。融合 Kernel 把三步全放在片上存储完成,HBM 访问减少约 3 倍。
Python — Fused Softmax Kernel复制
@triton.jitdefsoftmax_kernel( output_ptr, input_ptr, input_row_stride, output_row_stride, n_cols, BLOCK_SIZE: tl.constexpr, ): # 每个 program 处理一行 row_idx = tl.program_id(0) row_start_ptr = input_ptr + row_idx * input_row_stride # 计算列偏移 col_offsets = tl.arange(0, BLOCK_SIZE) input_ptrs = row_start_ptr + col_offsets mask = col_offsets < n_cols # 加载一行,越界位置填充 -inf row = tl.load(input_ptrs, mask=mask, other=float('-inf')) # 数值稳定:减去最大值 row_max = tl.max(row, axis=0) row = row - row_max # 指数 + 求和 numerator = tl.exp(row) denominator = tl.sum(numerator, axis=0) # 归一化 + 写回 softmax_output = numerator / denominator out_start_ptr = output_ptr + row_idx * output_row_stride tl.store(out_start_ptr + col_offsets, softmax_output, mask=mask)Python — Launch复制
defsoftmax(x: torch.Tensor): out = torch.empty_like(x) n_rows, n_cols = x.shape # BLOCK_SIZE 取大于 n_cols 的最小 2 的幂 BLOCK_SIZE = triton.next_power_of_2(n_cols) softmax_kernel[(n_rows,)]( out, x, x.stride(0), out.stride(0), n_cols, BLOCK_SIZE=BLOCK_SIZE, ) return out
在 A100 上,当 n_cols=32K 时,Triton 融合 Softmax 的有效带宽可达约 1660 GB/s,比 torch.softmax 的约 1120 GB/s 快 48%。差距的来源正是 HBM 访问次数的减少。
⚡ 示例三:矩阵乘法与自动调优
矩阵乘法是 GPU 计算的核心。在 Triton 中,一个 program 计算 C 的一个 tile [BLOCK_M, BLOCK_N],沿 K 维循环累加。这里引入三个新概念:2D 指针算术、L2 缓存优化、Autotune 自动调优。
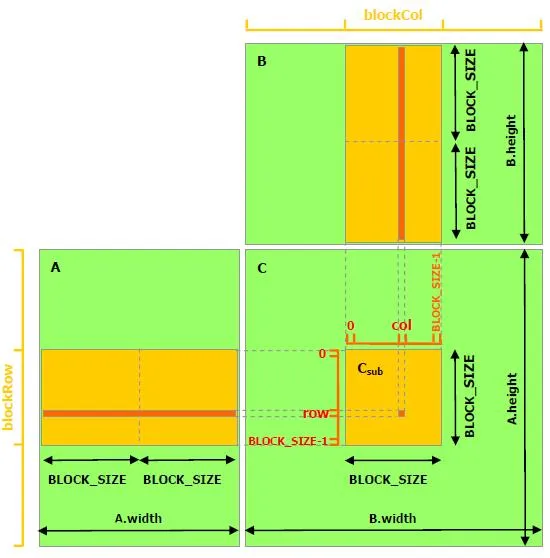
分块矩阵乘法:每个 program 计算 C 的一个 tile,沿 K 维迭代累加
Python — Matmul Kernel with Autotune复制
@triton.autotune( configs=[ triton.Config({'BLOCK_M': 128, 'BLOCK_N': 256, 'BLOCK_K': 64}, num_stages=3, num_warps=8), triton.Config({'BLOCK_M': 64, 'BLOCK_N': 256, 'BLOCK_K': 32}, num_stages=4, num_warps=4), triton.Config({'BLOCK_M': 128, 'BLOCK_N': 128, 'BLOCK_K': 32}, num_stages=4, num_warps=4), ], key=['M', 'N', 'K'], )@triton.jitdefmatmul_kernel( a_ptr, b_ptr, c_ptr, M, N, K, stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr, GROUP_SIZE_M: tl.constexpr, ): pid = tl.program_id(axis=0) # --- L2 缓存优化:分组启动顺序 --- num_pid_m = tl.cdiv(M, BLOCK_M) num_pid_n = tl.cdiv(N, BLOCK_N) num_pid_in_group = GROUP_SIZE_M * num_pid_n group_id = pid // num_pid_in_group first_pid_m = group_id * GROUP_SIZE_M group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M) pid_m = first_pid_m + (pid % group_size_m) pid_n = (pid % num_pid_in_group) // group_size_m # --- 2D 指针算术 --- offs_am = (pid_m * BLOCK_M + tl.arange(0, BLOCK_M)) % M offs_bn = (pid_n * BLOCK_N + tl.arange(0, BLOCK_N)) % N offs_k = tl.arange(0, BLOCK_K) a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak) b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn) # --- K 维循环累加 --- accumulator = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32) for k inrange(0, tl.cdiv(K, BLOCK_K)): a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_K, other=0.0) b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_K, other=0.0) accumulator += tl.dot(a, b) # 自动映射到 Tensor Core a_ptrs += BLOCK_K * stride_ak b_ptrs += BLOCK_K * stride_bk # --- 写回结果 --- c = accumulator.to(tl.float16) offs_cm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M) offs_cn = pid_n * BLOCK_N + tl.arange(0, BLOCK_N) c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :] c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N) tl.store(c_ptrs, c, mask=c_mask)💡 三大关键技巧
① 2D 指针算术:用 offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak 广播生成二维地址矩阵,tl.load 一次加载一整块。
② L2 缓存分组:简单的行优先启动顺序会让相邻 program 加载不同的 B 行,L2 命中率低。分组策略让相邻 program 共享 B 数据,在 A100 上可提升约 10% 性能。
③ Autotune:高性能 Kernel 的参数没有固定答案。Block 大小、warp 数、流水线级数都取决于硬件和矩阵形状。Autotune 自动在多组配置中选最优。
👑 示例四:FlashAttention — 算子融合的皇冠
FlashAttention 是当今 LLM 推理加速的核心技术,也是 Triton 生态中最具代表性的项目。标准 Attention 需要生成 N×N 的注意力矩阵,显存开销 O(n²)。FlashAttention 通过 Tiling + Online Softmax 完全避免读写这个巨大中间矩阵。
核心思想:将 Q 分块,对每个 Q 块遍历 K/V 块,在片上存储中完成 attention 计算。关键在于 Online Softmax——在循环中动态更新最大值和指数和,当发现新的最大值时,对之前累加的结果进行重新缩放。
Python — FlashAttention Kernel (简化版)复制
@triton.jitdefflash_attn_kernel( Q, K, V, Out, stride_qm, stride_qk, stride_kn, stride_kk, stride_vn, stride_vk, stride_om, stride_on, Z, H, N_CTX, HEAD_DIM: tl.constexpr, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, ): start_m = tl.program_id(0) offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M) offs_d = tl.arange(0, HEAD_DIM) # 加载 Q 块 q = tl.load(Q + offs_m[:, None] * stride_qm + offs_d[None, :] * stride_qk) # 初始化累加器 acc = tl.zeros([BLOCK_M, HEAD_DIM], dtype=tl.float32) max_score = tl.zeros([BLOCK_M], dtype=tl.float32) - float('inf') sum_exp = tl.zeros([BLOCK_M], dtype=tl.float32) # 遍历 K/V 块for start_n inrange(0, N_CTX, BLOCK_N): offs_n = start_n + tl.arange(0, BLOCK_N) k = tl.load(K + offs_n[:, None] * stride_kk + offs_d[None, :] * stride_kk) v = tl.load(V + offs_n[:, None] * stride_vn + offs_d[None, :] * stride_vk) # Attention scores: Q @ K^T scores = tl.dot(q, tl.trans(k)) # Online softmax:动态更新 max 和 sum block_max = tl.max(scores, axis=1) new_max = tl.maximum(max_score, block_max) scale_old = tl.exp(max_score - new_max) scale_new = tl.exp(block_max - new_max) exp_scores = tl.exp(scores - new_max[:, None]) sum_exp = sum_exp * scale_old + tl.sum(exp_scores, axis=1) * scale_new acc = acc * scale_old[:, None] + tl.dot(exp_scores, v) * scale_new[:, None] max_score = new_max # 归一化并写回 acc = acc / sum_exp[:, None] tl.store(Out + offs_m[:, None] * stride_om + offs_d[None, :] * stride_on, acc)这段代码就是 FlashAttention 的核心。它永远不会物化完整的 N×N 注意力矩阵,通过 Online Softmax 在片上存储中完成所有计算。显存从 O(n²) 降到 O(n),速度反而更快——因为减少了大量 HBM 读写。
🛠️ 性能调优清单
- BLOCK_SIZE 必须是 2 的幂(16/32/64/128/256/1024),且是 warp 大小(32)的倍数
- 用 tl.constexpr 声明编译时常量
- 确保连续内存访问:tl.load 指向连续地址时编译器可自动向量化;跨步访问会严重降速
- 累加器用 float32:即使输入是 float16/bfloat16,累加器保持 fp32 精度避免数值溢出
- 用 tl.dot 映射 Tensor Core:不要自己写逐元素乘加,tl.dot 会自动利用 Tensor Core 加速
- 共享内存不超限:A100 每 SM 164KB,算一下你的 tile 是否放得下
- 用 @triton.autotune 自动搜索最优配置:block 大小、num_warps、num_stages 一起调
- mask 不要省略:越界访问不会报错,但会返回垃圾数据甚至导致 GPU 挂死
- 避免在 Kernel 内部使用 Python 控制流:if/else 依赖运行时值会导致 warp 分歧
- 不要过早优化:先用默认参数跑通,确认正确性后再 autotune
🎯 何时用 Triton,何时不用
✅ 适合用 Triton
• 自定义注意力变体(sparse attention、sliding window)
• PyTorch 没有的融合算子(RMSNorm + 残差 + 量化融合)
• 稀疏矩阵操作
• 自定义归约/扫描模式
• 快速原型验证,之后再考虑是否转 CUDA
❌ 不需要 Triton
• 标准 matmul/softmax/layernorm——cuBLAS/cuDNN 已足够优化
• PyTorch 原生算子能高效组合的场景
• 需要极致性能的最后 5-10%——手工 CUDA 仍有优势
• 非 NVIDIA GPU 的成熟生产环境(AMD 支持尚不完善)
• 不涉及 GPU 编程的纯 CPU 任务
💡 经验法则
如果你的操作已经被 cuBLAS/cuDNN 优化过了,用库函数;如果 PyTorch 原生算子拼凑有冗余内存访问,用 Triton 融合;如果你需要极致的硬件级控制,写 CUDA C++。Triton 的最佳生态位是"比 PyTorch 快,比 CUDA 易写"。
Triton 的出现,本质上是 GPU 编程范式的一次跃迁:从"告诉每个线程做什么"到"告诉每个程序块做什么"。这种抽象级别的提升,让更多开发者能够触及 GPU 算子优化的领域——过去这是极少数 CUDA 专家的专属领地。
随着 torch.compile 将 Triton 作为默认后端、FlashAttention 等 LLM 核心算子用 Triton 重写、Blackwell 架构引入 Tensor Memory 和 Warp Specialization 支持,Triton 正在从"替代方案"变成"主流方案"。如果你在做大模型训练推理优化,Triton 已经是一项值得掌握的核心技能。
从向量加法到 FlashAttention,这篇文章覆盖了 Triton 最核心的编程思想和实战模式。下一步?打开你的 GPU,把文中的代码跑一遍——从 pip install triton 到写出你的第一个融合 Kernel,只需要一个下午
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
