大家好,我是木木。
今天给大家分享一个硬核的 Python 库,desbordante。
desbordante
desbordante 是一个面向数据画像和数据质量发现的工具,核心能力不是简单的 describe,而是发现和验证数据中的模式:函数依赖、近似函数依赖、唯一列组合、包含依赖、关联规则、否定约束等。它的底层是 C++,并提供 Python bindings,让你可以把 pandas DataFrame 交给算法去挖数据约束。需要说明的是,当前 Windows 环境没有可安装的 desbordante 发行版,因此本文示例用 pandas 复现它关注的几类数据规则思路;在 Linux/macOS 环境可以使用官方 Python binding 跑更完整的算法。
项目地址:https://github.com/desbordante/desbordante-core
官方文档:https://desbordante.unidata-platform.ru/
三大特点
模式发现
关注数据中隐藏的依赖、唯一性、包含关系和约束,而不只是表面统计值。
解释冲突
验证某条规则不成立时,能够给出违反规则的行,方便定位数据问题。
偏工程化
底层实现追求性能,适合较大的表和更复杂的数据质量分析任务。
最佳实践
安装方式:Linux/macOS 环境可参考官方文档使用 pip install desbordante 或从源码构建;Windows 当前没有匹配发行版。
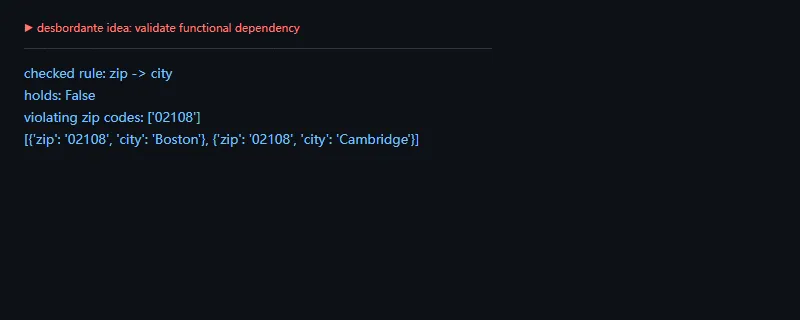
第一段代码解决的问题是:验证一个函数依赖是否成立。例子里检查 zip -> city,同一个邮编如果对应多个城市,就说明这条规则在当前数据里被破坏了。
importpandasaspddf=pd.DataFrame({"zip":["10001","10001","02108","02108"],"city":["New York","New York","Boston","Cambridge"]})violations=df.groupby("zip")["city"].nunique().loc[lambdas:s>1]print("checked rule: zip -> city")print("holds:",violations.empty)print("violating zip codes:",list(violations.index))print(df[df["zip"].isin(violations.index)].to_dict("records"))
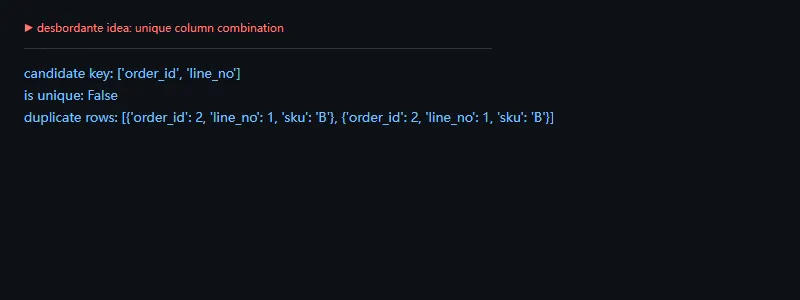
第二段代码解决的问题是:检查一组字段能不能作为唯一键。Desbordante 支持 Unique Column Combination 这类模式,真实算法会更系统地搜索候选组合;这里用 pandas 展示最小版验证逻辑。
importpandasaspddf=pd.DataFrame({"order_id":[1,2,2,3],"line_no":[1,1,1,1],"sku":["A","B","B","C"]})keys=["order_id","line_no"]dups=df[df.duplicated(keys,keep=False)]print("candidate key:",keys)print("is unique:",dups.empty)print("duplicate rows:",dups.to_dict("records"))
环境与版本信息
本文示例使用 Python 3.11.0、pandas 2.3.3。由于当前 Windows 环境无法安装 desbordante 包,示例展示的是它所处理的数据质量规则思路;正式使用时建议在支持的系统上安装官方 Python binding。
高级功能
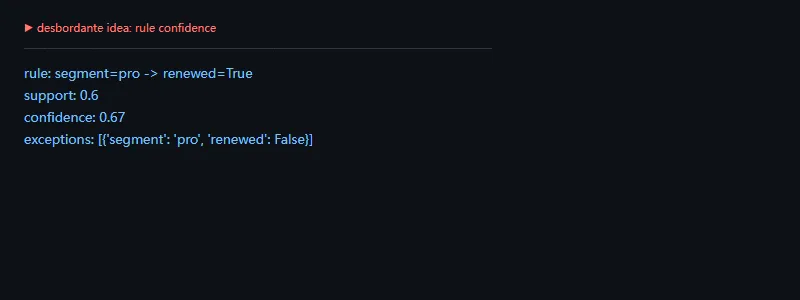
进阶一点看规则置信度。近似依赖和关联规则并不要求 100% 成立,它们会关心 support、confidence 这类指标,并列出例外记录。这类能力适合真实世界里“数据大体有规律,但有噪声”的情况。
importpandasaspddf=pd.DataFrame({"segment":["pro","pro","free","pro","free"],"renewed":[True,True,False,False,False]})rule_rows=df[df["segment"]=="pro"]confidence=rule_rows["renewed"].mean()support=(df["segment"]=="pro").mean()print("rule: segment=pro -> renewed=True")print("support:",round(support,2))print("confidence:",round(confidence,2))print("exceptions:",rule_rows[~rule_rows["renewed"]].to_dict("records"))
适用场景
适合数据质量分析、主键候选发现、外键/包含关系检查、重复和异常定位、科研数据模式发现,以及需要从数据里自动挖约束的治理场景。
不适用场景
不适合只需要简单 describe 的轻量分析,也不适合在不支持其发行包的平台上强行接入生产链路。复杂模式的解释成本较高,团队需要理解规则含义再落地。
上线检查
- 先确认部署平台是否能安装官方 Python binding。2. 对关键表限定字段范围,避免全表全组合搜索过慢。3. 把发现的模式交给业务确认,不要直接当作硬规则。4. 对验证失败的冲突行保留样本,方便回溯修复。
总结
desbordante 更像数据质量领域的“规则发现引擎”。如果你的问题不是“这列平均值是多少”,而是“这张表里到底有哪些应该成立的关系”,它就很值得关注。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
