如果你做过 AI Agent 开发,一定遇到过这种崩溃时刻:
- 用户昨天说"我习惯用深色模式",今天 Agent 又推荐了一套浅色主题
- 客服 Agent 刚处理完退款,用户追问进度时,它像第一次听说这件事
- 多轮对话超过 20 轮后,Agent 开始胡言乱语,把 A 用户的信息安到 B 用户头上
问题的本质不是 LLM 不够聪明,而是它缺了一块"长期记忆"的硬盘。
Cognee这个项目,就是专门来解决这个问题的。
Cognee:是什么
Cognee 是一个开源的 AI 记忆平台,由柏林团队 Topoteretes 开发。它的核心思路很简单:不是让 Agent 记住文本片段,而是让 Agent 记住"知识关系"。
这是 Cognee 处理完文档后生成的真实知识图谱。
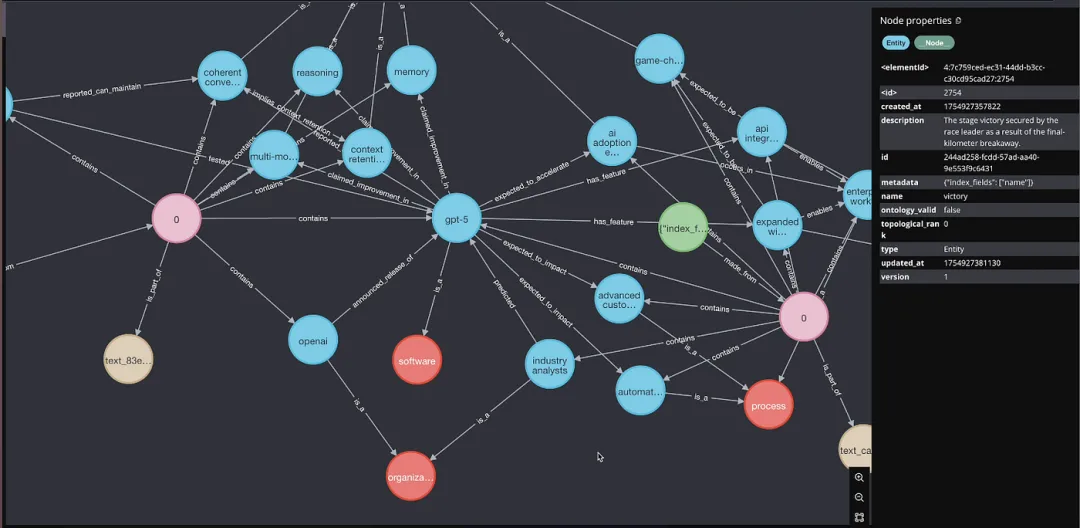
每个节点是一个实体(概念、人物、组织),边是它们之间的关系。
右侧能看到每个节点的属性面板——这不是概念图,是真实从文本里提取出来的结构化数据。
能做什么
记忆存储
- 永久记忆:提取实体、识别关系、生成本体,写入图数据库,跨会话持久保存
- 会话缓存:同一 session 先查本地缓存,后台异步同步图谱,兼顾速度和深度
- 多模态摄入:PDF、Word、音频、网页等 30+ 格式
- 自我改进:根据反馈自动优化记忆权重
检索与推理
- 自动路由查询:
recall() 自动选择最佳策略(向量 / 图遍历 / 混合) - 多跳推理:基于关系路径回答跨文档关联的复杂问题
- CoT 检索器:开源 Chain-of-Thought 模块,BEAM 基准测试超 SOTA
存储后端
- All-in-Postgres:单个 PostgreSQL 跑完整套记忆层(图 + 向量 + 缓存 + 元数据),比传统"Neo4j + 向量库 + Redis"快约 10%
- 专业后端:Neo4j / Neptune(图)、pgvector / Qdrant / Weaviate(向量)、Redis(缓存)
生态集成
- Claude Code 官方插件、OpenClaw、LangGraph、n8n、MCP 协议
- Python / TypeScript / Rust 三语言 SDK
实际场景
排查 Agent 记忆短板
cognee-cli -ui 启动本地可视化界面,浏览器里直接看到知识图谱全貌——哪些实体提取对了、哪些关系连错了、哪些文档还没 cognify,一目了然。
给 Claude Code 装跨会话记忆
安装官方插件后,每次对话的提示词、工具轨迹、助手回复自动捕获到会话记忆,注入相关上下文。会话结束同步到永久图谱。下次打开 Claude Code,它记得你上周的代码规范。
部署前做记忆基准
上线前把产品文档、API 规范全部 remember() 进 Cognee。后续需求变更后对比图谱差异——新增了什么概念、哪些关系被改了、哪些旧文档失效了。
上手:让 AI Agent 帮你装
直接复制给 Claude Code / Cursor:
用 Docker 部署 Cognee,参考 https://github.com/topoteretes/cognee
要求:
1. docker compose --profile ui up 启动 API(8000) + UI(3000)
2. 配置 LLM_API_KEY
3. 验证:cognee-cli remember "测试" && cognee-cli recall "测试"
4. 打开 localhost:3000 确认可视化正常
手动 3 步:
git clone https://github.com/topoteretes/cognee.git && cd cognee
cp .env.template .env# 填入 LLM_API_KEY
docker compose --profile ui up
不用 Docker?一行 pip:
pip install cognee
export LLM_API_KEY="sk-..."
python -c "import cognee, asyncio; asyncio.run(cognee.remember('Hello')); print(asyncio.run(cognee.recall('Hello')))"
6 行核心代码:
import cognee, asyncio
asyncdefmain():
await cognee.remember("Cognee 把文档变成 AI 记忆。")
print(await cognee.recall("Cognee 做什么的?"))
asyncio.run(main())
| API | 作用 |
|---|
remember() | 永久存入知识图谱 |
recall() | 自动路由最佳检索策略 |
forget() | 删除数据集 |
improve() | 根据反馈优化记忆 |
竞品对比
| 维度 | Cognee | Mem0 | LightRAG | Graphiti |
|---|
| 记忆类型 | 知识图谱 + 向量 + 会话 | 向量 + 实体提示 | 双层图 RAG | 时序知识图谱 |
| 跨文档关联 | ✅ 多跳三元组遍历 | ❌ 仅实体提升 | ✅ 多跳边 | ✅ 多跳 BFS |
| 事实变更 | 保留新旧版本(带日期) | 原地更新,无历史 | 旧版本不保留 | 旧边可查询(双时态) |
| 写入成本 | 批量 cognify | 最低(~1 LLM 调用) | 中等 | 最高 |
| All-in-Postgres | ✅ | ❌ | ❌ | ❌ |
| MCP 协议 | ✅ | ❌ | ❌ | ❌ |
| Claude Code 插件 | ✅ 官方 | ❌ | ❌ | ❌ |
没有工具在每个维度都是最深的——Graphiti 时序关系更专业,Mem0 写入延迟更低,LightRAG 部署更轻。Cognee 胜在覆盖面:图推理、向量检索、会话缓存、本体生成、跨 Agent 共享,一套架构搞定,不用堆三四个系统。
注意点
- 首次
cognify 消耗 Token: 提取实体和关系需要 LLM 调用,长文档建议批量处理,实时性要求高的场景先走 session 缓存 - Postgres 有边界: 千万级节点以上建议切 Neo4j/Neptune
- LLM 是硬门槛: 本地可用 Ollama,效果最好的是 GPT-5.5/Claude 4.8
写在最后
Cognee 不是向量数据库,是Agent 的记忆层基础设施。做 AI Agent、需要给 LLM 应用加"公司大脑"、想让 Claude Code 拥有跨项目记忆的,值得试一试。
GitHub:https://github.com/topoteretes/cognee
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
